- ホーム
- お役立ち
- Google Service
- AWS、AzureにあるデータをBigQuery で分析してみよう
AWS、AzureにあるデータをBigQuery で分析してみよう
- AWS (Amazon Web Services)
- Azure
- BigQuery
- GCP
- Google Cloud (GCP)

Google Cloud(GCP)のBigQuery(BQ)は、強力な分析ツールですが、分析対象となるデータはGoogle Cloud (GCP)上にあるとは限りません。昨今、複数のクラウドを活用することは珍しいことではなくなり、データレイク一元化の難易度が上がるとともに、分析データが散らばっていることも増えてきています。
本ブログでは、こうした状況に対してのGoogle Cloud (GCP)のアプローチや、Google Cloud (GCP)のデータ分析基盤であるBigQuery でAWS、Azure 上のデータを分析する手順について解説します。
ご覧になっている方は、AWSかAzureのどちらかを利用されている方だと思いますので、利用されていない方のクラウドとの連携方法は読み飛ばしていただけたらと思います。
データレイクの概要からユースケースまで知りたい方は以下の記事がオススメです。
Google Cloud (GCP) で構築できる「データレイク」とは?概要、メリット、構築方法、ユースケースまで徹底解説!
Google Cloudでデータレイクの構築を検討されている方は以下の記事がオススメです。
Google Cloud(GCP)におけるデータレイクとは?Google Cloudでのサービスと概要までご紹介!
従来のBigQueryとAWS、Azure の連携例例
BigQuery とAWS、Azure従来のアプローチの例は下記のように、データをGoogle Cloud (GCP)側に転送するケースがありました。
具体的には、下図のような「Google Cloud Strage ( GCS )へのデータ転送」であったり、「Amazon S3データをBigQuery テーブルにコピー」です。各クラウドベンダーが提供するデータ転送サービスを活用してもらい、いかに自身のクラウドにデータを取り込むかという思惑もあったかと思います。
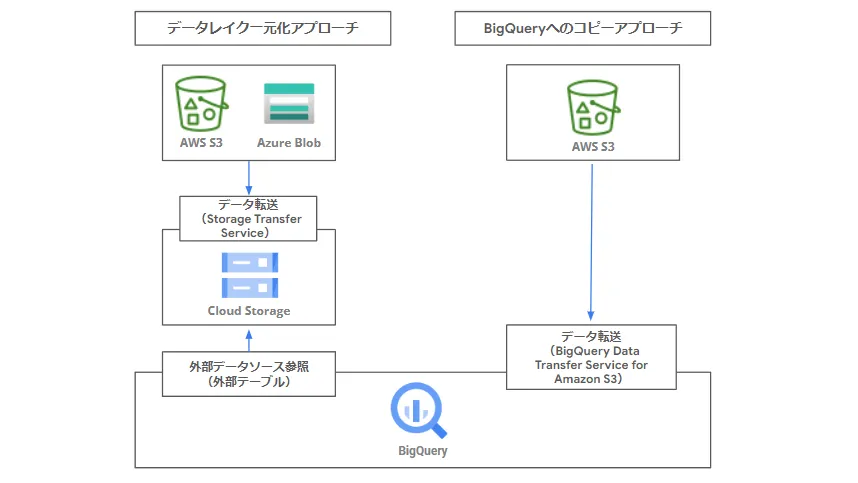
こうした従来アプローチは、Google Cloud (GCP)以外のクラウドサービスでも同様に採用され、自身のクラウド上にデータを配置してもらえるよう様々なサービスが提供されています。
- AWS Strage Gateway、Snowball、Import/Export 等
- Azure Import/Export、DataBox 等
マルチクラウド、クロスクラウド分析への流れ
一方で、多くのユーザー企業はクラウドサービスのいいとこどりを狙い、オンプレからクラウドへの移行の後は、「ひとつのクラウドへの統合」に進むケースは少なく、クラウドをまたぐマルチクラウドの形でデータが増加していきました。こうした状況に対し、Google Cloud (GCP)は早い段階から、マルチクラウドが定着していることを認識し、クラウド間のデータ連携機能に加えて、BigQuery から他クラウド各データへのアクセスを容易にしていくというアプローチを強化しています。
まず、2021年10月に、BigQuery Omni が発表されました。BigQuery Omni は下図の通り、AWS、Azure側のコンピューティング領域でBigQuery のクエリエンジンを実行するアーキテクチャです。2022年5月現在、クエリとエクスポート(クエリ結果をAWS、Azure側に保管)の2つの機能があります。
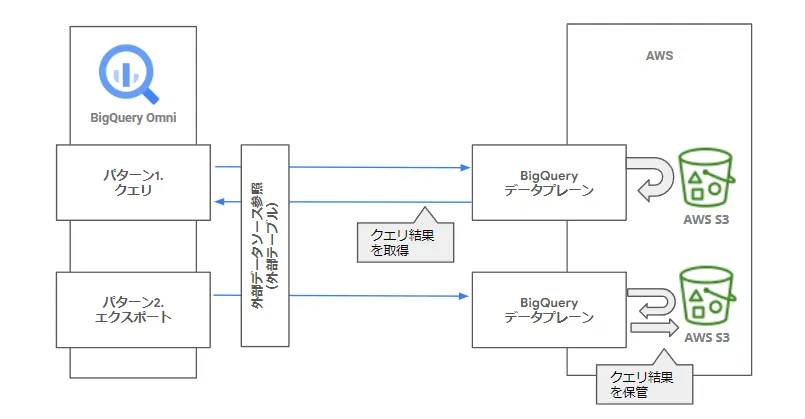
これにより、AWS、Azure上のデータをBigQuery にコピーしなくても、データへの迅速なクエリが可能になります。対応しているリージョンはAWS(US East(北Virginia))、Azure(米国東部 2)のみとなりますが、他のクラウドのリソースを借用(Google がAWS のEC2、Azure のVM を管理)して橋頭保をつくり、他クラウド上のデータ制御を柔軟に行うアプローチです。この方式については、具体的な手順を次項にて後述します。
このようにGoogle Cloud (GCP)は、データを移動させず、BigQuery 側からデータにアクセスするクロスクラウド分析の方式を作り、その結果を一括して表示、分析する機能を強化しています。
そして、2022年4月には、Biglake プレビューが発表されました。これは、データウェアハウス(DWH)、データレイクに対し、セキュリティやアクセス制御を実施し、分散するデータ群に対しガバナンスを効かせることで、マルチクラウド上の分析に求められる要件に対応するものです。Biglake は、BigQuery の外部データソースに、Biglake テーブルという選択肢が加わり、このテーブル経由で、各データにガバナンスに従ったアクセスをすることができます。
このように、Google Cloud (GCP)は分散するデータの統合ではなく、各データをBigQuery のポータルから自在に分析して、結果を一元的に表示させるアプローチを強化していると考えられます。
Biglake については以下の記事で詳しく解説しておりますので、あわせてご覧ください。
Google の新サービス「 BigLake 」とは?特徴やメリット、ユースケースまで徹底解説!
データウェアハウス(DWH) について理解を深めたい方は以下の記事がオススメです。
クラウドDWH(データウェアハウス)って何?AWS,Azure,GCPを比較しながら分析の手順も解説!
BigQuery Omni経由のAWSのデータソース接続例
本項では、BigQuery Omni によるAWS への接続手順を解説します。初回設定のみ、AWS、Google Cloud (GCP)側と設定の行き来が発生しますので、下記手順を参考に進めてください。
ここでは、分析対象となるデータは、csv 形式のファイルとしています。BigQuery Omni の対応フォーマットは、AVRO, PARQUET, ORC, CSV, NEWLINE_DELIMITED_JSON, Google Sheetsです。
Google Cloud (GCP)側設定(プロジェクトの作成)
BigQuery Omni と 下記API が有効なプロジェクトを利用します。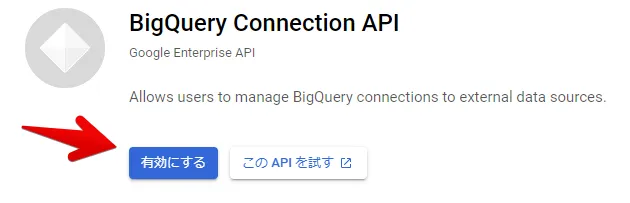
AWS 側設定(S3の設定)
S3 バケットを新規作成し、バケットのARN 情報をメモします。リージョンは「米国東部(バージニア北部)us-east-1」を選択してください。(2022/05現在、BigQuery Omni はAWS のこのリージョンのみ対応)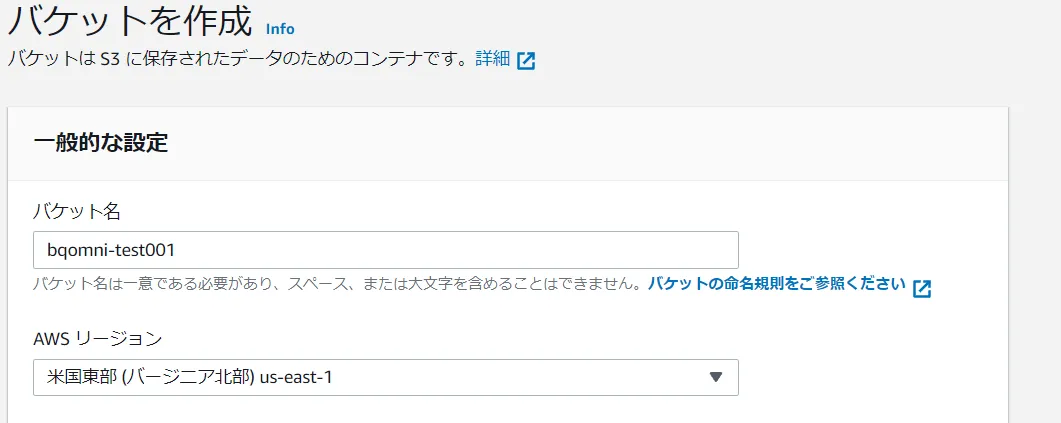
新規バケット作成時はデフォルトの下記チェックボックスをONにし意図せぬ外部公開を回避します。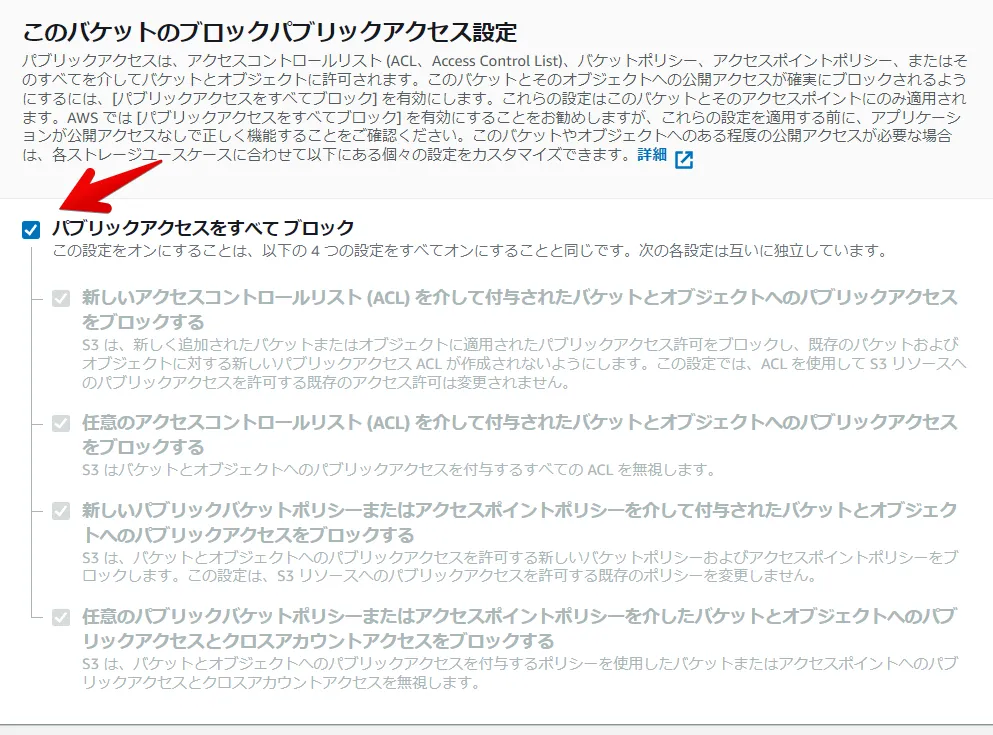
作成したバケットのARN 情報を確認します。(ここでは、"bqomini-test001" というバケットを作成しました)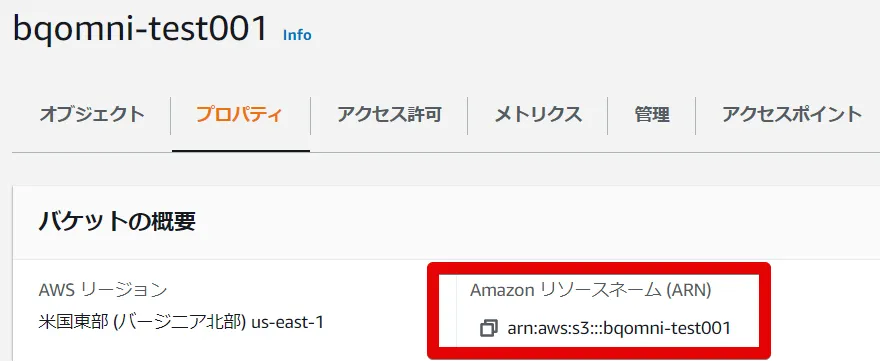
本手順ではバケット直下に疎通確認用の下記データをもつ "test.csv" を配置します。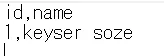
AWS 側設定(IAMのポリシー作成)
IAM ポリシーを作成します。先ほど作成したバケットの参照権限を付与します。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": ["s3:ListBucket"],
"Resource": ["arn:aws:s3:::bqomni-test001"]
},
{
"Effect": "Allow",
"Action": [
"s3:GetObject"
],
"Resource": ["arn:aws:s3:::bqomni-test001/*"]
}
]
}
※Amazon S3 バケットにデータをエクスポートする必要がある場合は、s3:PutObject 権限も必要です。
上記JSONを下記ポリシー作成画面の赤枠に置き換える形でペーストします。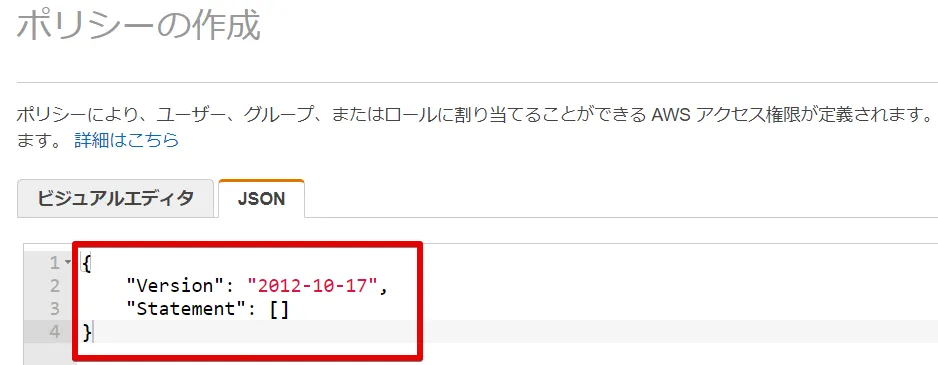
意図した権限であることを確認し、IAM ポリシーを作成します。(ここでは、"bqomni-s3" というポリシーを作成しました)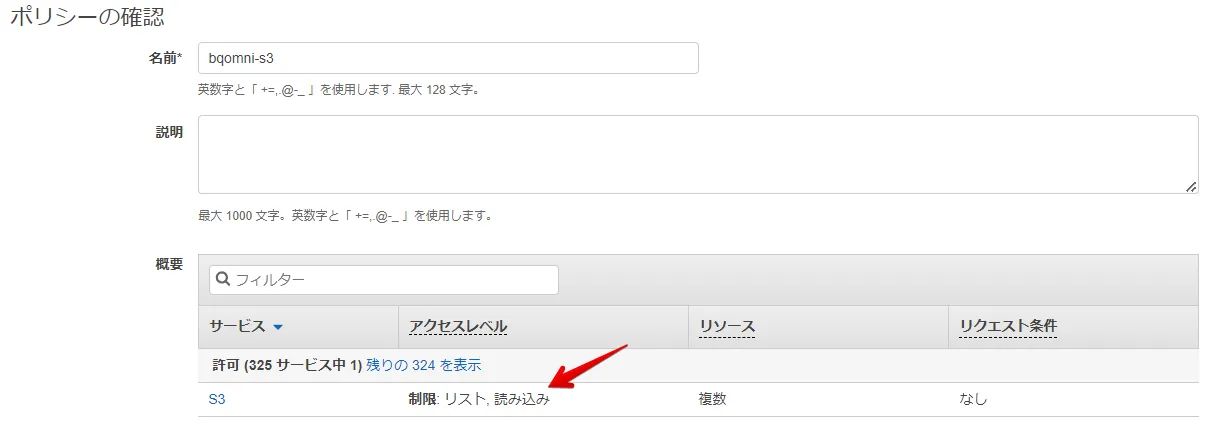
AWS 側設定(IAMロール作成)
Google Cloud が利用するIAM ロールを作成します。(下図 "00000" 部分は後続手順で再設定します)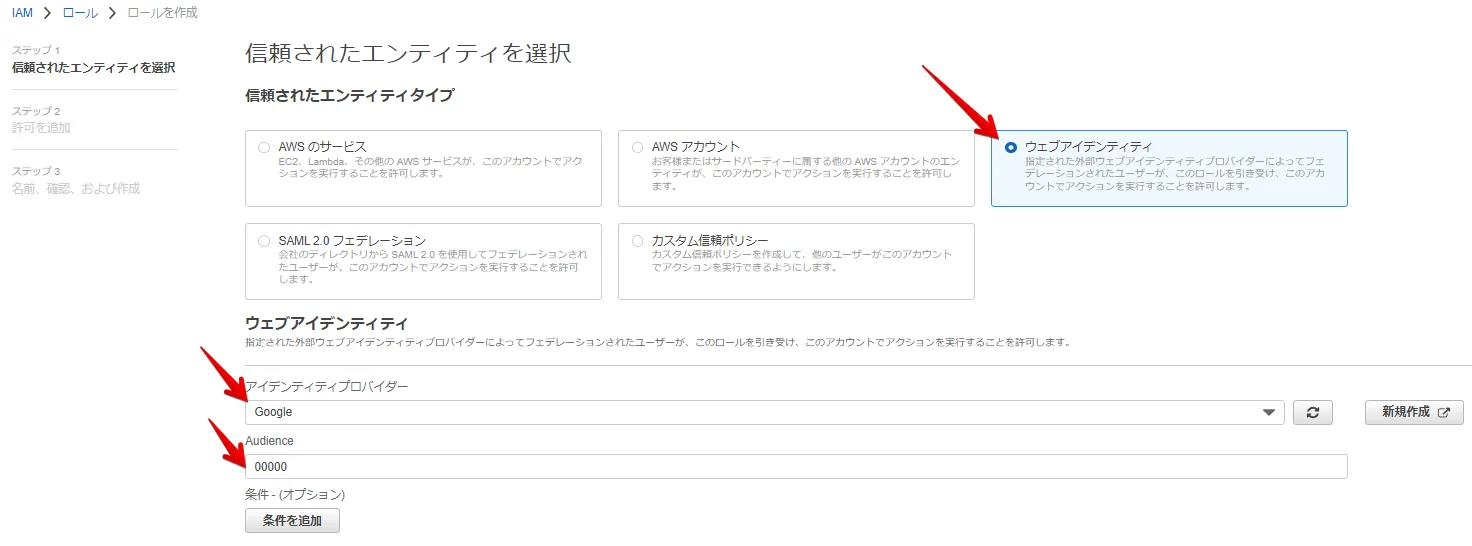
※2022/05現在、下記公式マニュアル日本語版のIAM ロール作成手順は実機の動きと異なるため、英語版もしくは本ブログの手順をご確認ください。
https://cloud.google.com/bigquery-omni/docs/aws/create-connection
IAM ロールに先ほど作成したIAM ポリシーを付与します。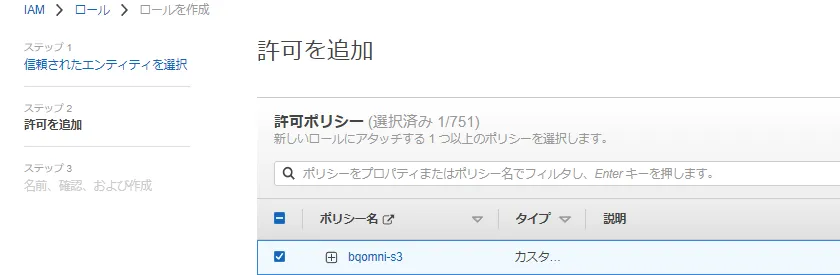
IAM ロール作成後、ARN 情報を確認します。(この値は、Google Cloud (GCP)側で利用します)
BigQueryでのデータソース作成
BigQuery で外部データソースを作成します。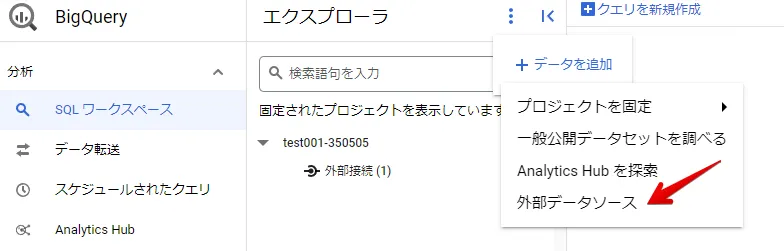
BigQueryでのデータソース設定
先ほど確認したAWS IAM ロールのARN 情報を下図AWS ロールID に入力します。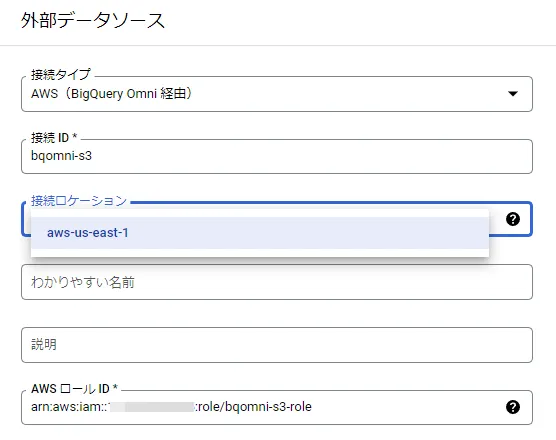
※2022/05現在、AWS側のロケーションは、米国東部(バージニア北部、US-EAST-1)となります。
作成された外部接続情報の、BigQuery Google ID を確認します。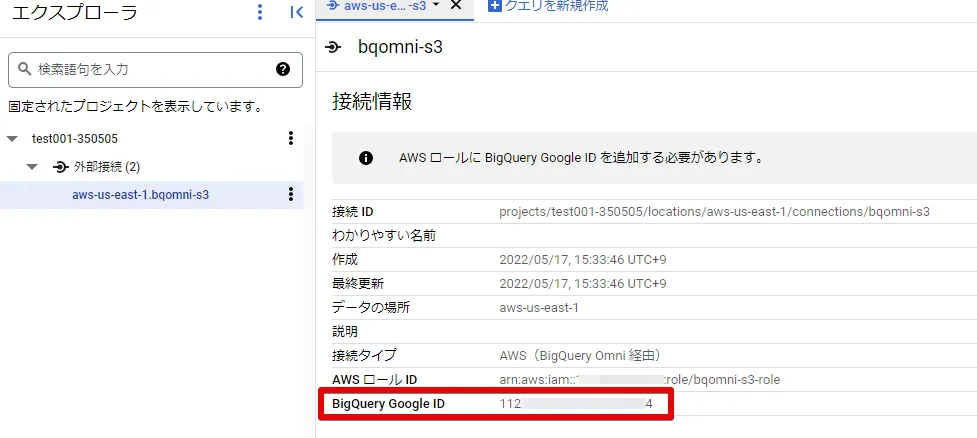
AWS 側設定(IAMロールの編集)
作成したIAM ロールを編集します。
「最大セッション時間」を「12時間」に変更
「下図赤枠のaud 情報」を先ほど確認した「BigQuery Google ID に変更」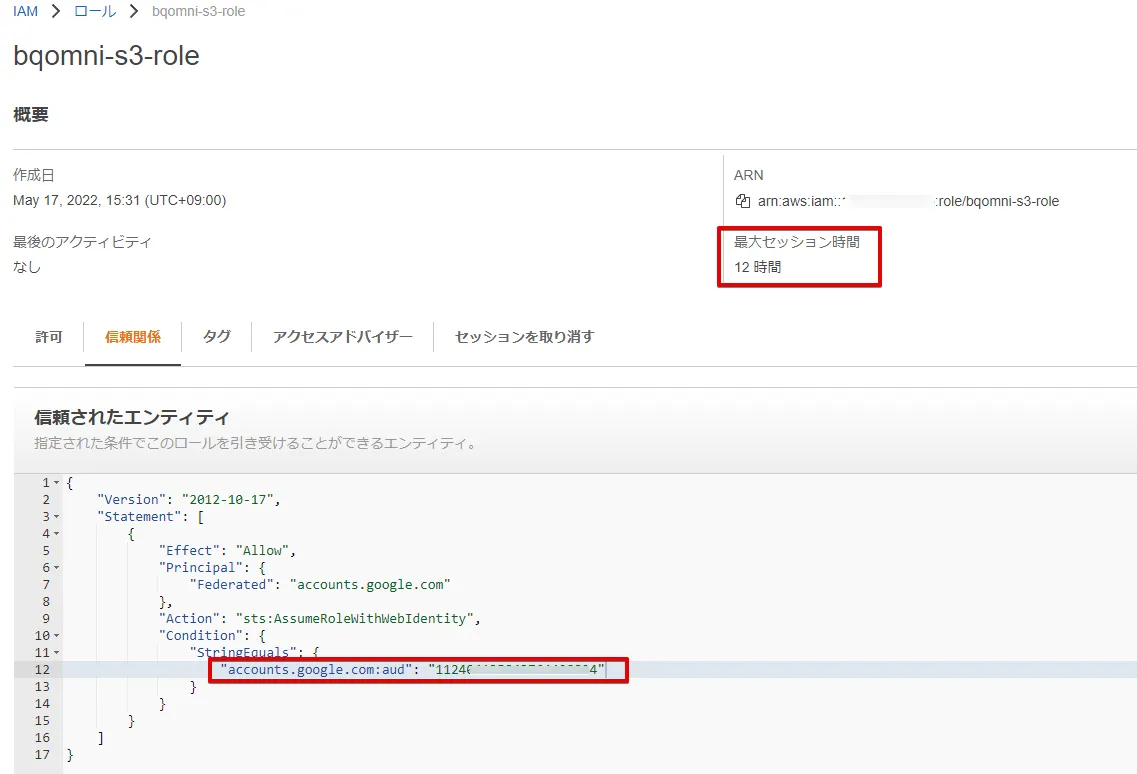
BigQueryのデータセット作成
データセットを作成します。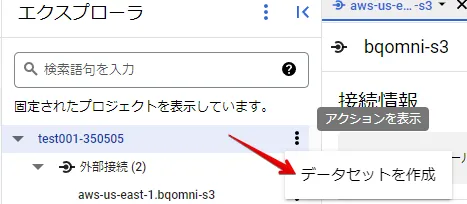
BigQueryのデータセット設定
データのロケーションは、外部データソース作成で設定したロケーションを指定します。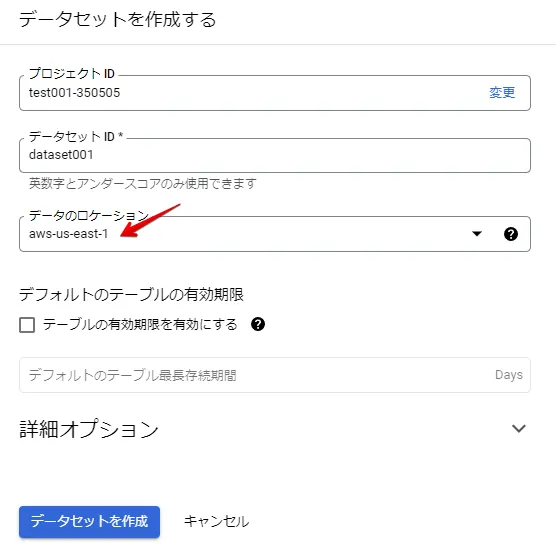
BigQueryでの外部テーブルの作成
外部テーブルを作成します。
BigQueryでの外部テーブルの設定
S3のパスは、s3://{バケット名}/* としています。(これにより、バケット直下の "test.csv" を参照できます)
接続ID は自動で検出されます。
スキーマの自動検出チェックボックスをONにします。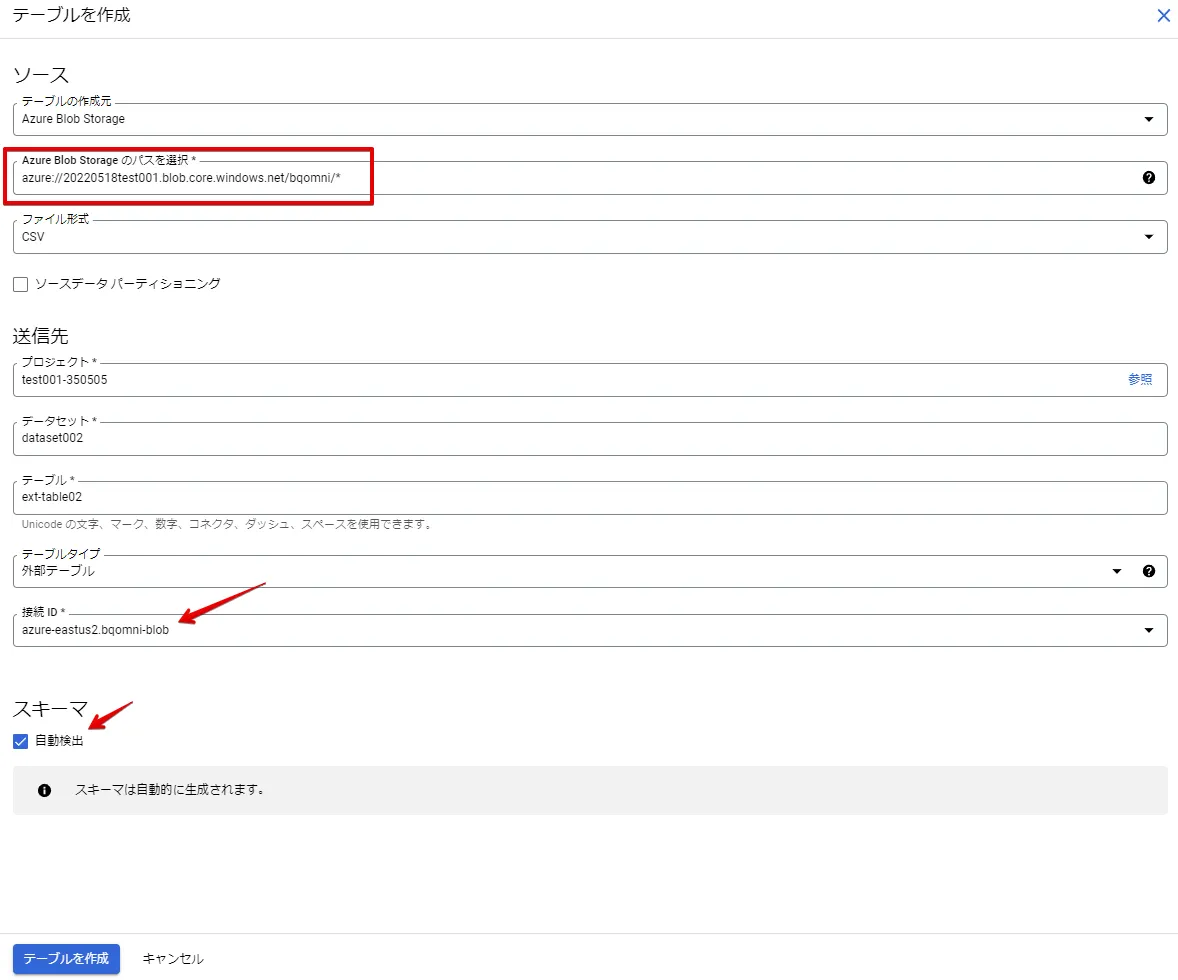
テーブルを作成すると、S3 バケットに配置した "test.csv" のフィールド名が取得できます。これにより、AWS S3 のファイルにアクセスできていることが確認できました。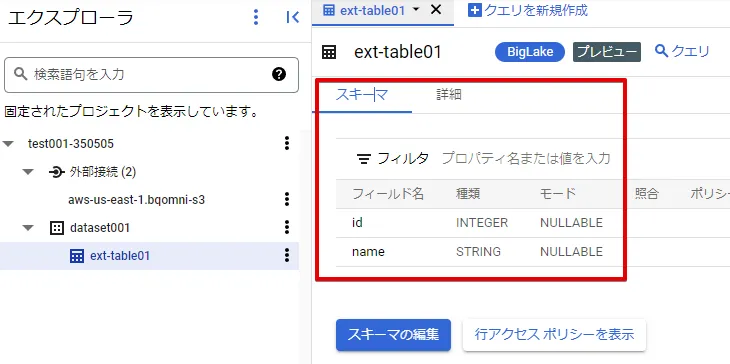
参考:S3 の "test.csv" のデータ
BigQueryとAWS連携確認
外部テーブルの作成の結果、スキーマ情報が自動で検出されていることをもって、BigQuery Omni を経由したAWS との連携確認とします。(実際のクエリによる確認は、次のスロット購入後に可能になります)
BigQueryでのスロット購入
BigQuery Omni の利用には、スロットの購入が必要であり、スロット未購入の状態でクエリを実行すると、下図の通り、購入の注意喚起メッセージが出力されます。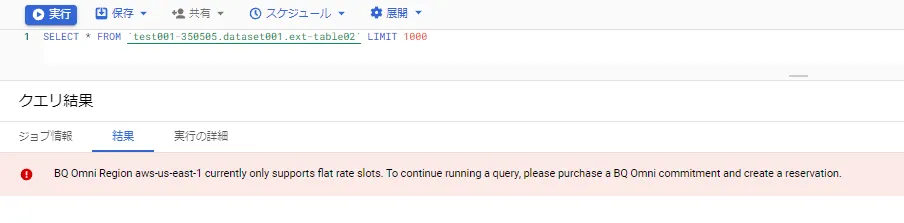
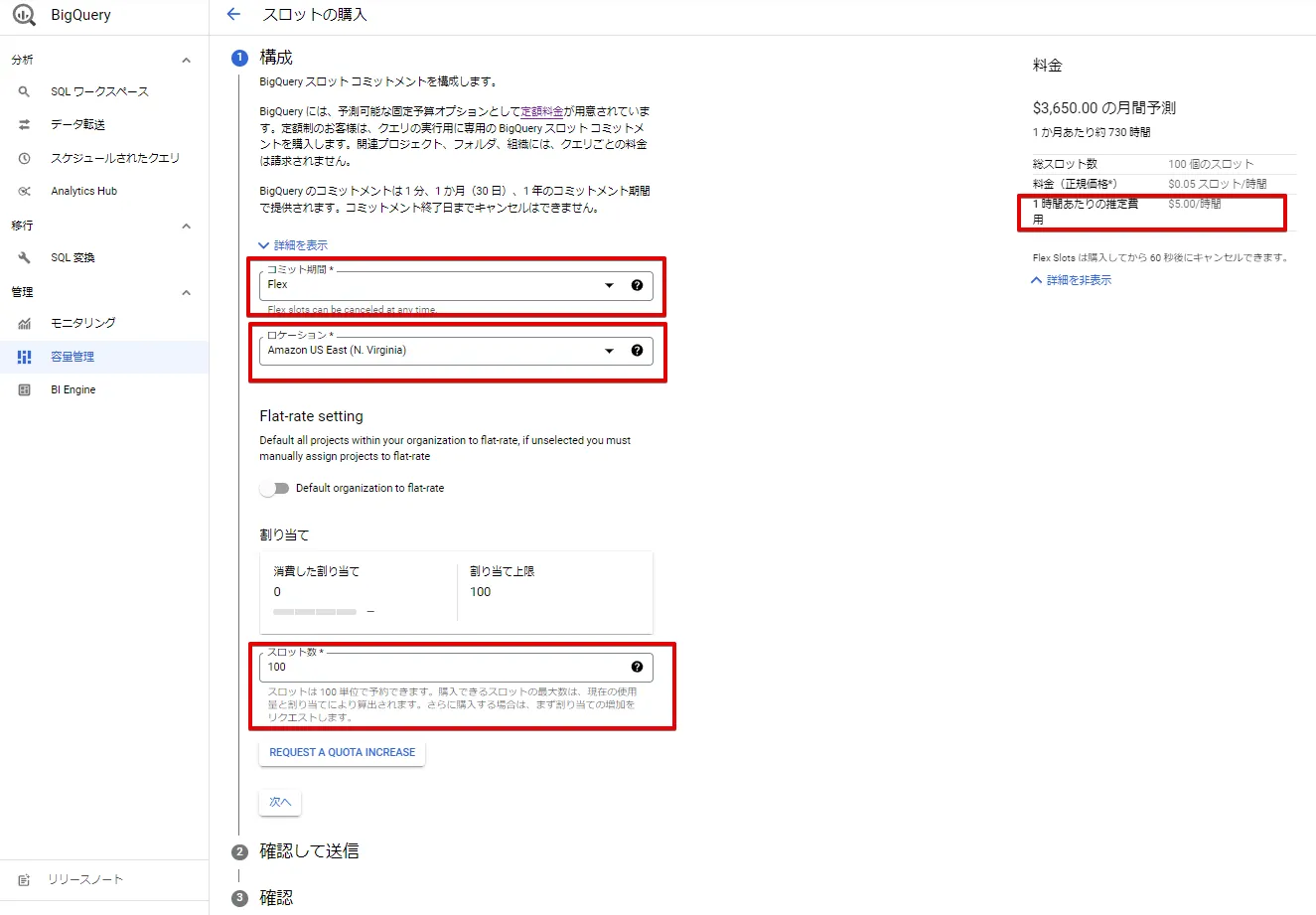
BigQuery のサイドメニュー「容量確認」 をクリックし、スロットを購入します。
課金観点の注意:
- 検証の場合、必ず、「Flex」を選択し、時間課金となるようにしてください。
- AWS側のロケーションの指定ミスをしないようにする必要があります。
- スロット数は100 からとなります。
- 時間単価も比較的高価なため、事後手順のスロット削除を忘れないようにしてください。
購入後、スロットの「予約」タブをクリックし、検証中のGoogle Cloud (GCP)プロジェクトと紐づけてください。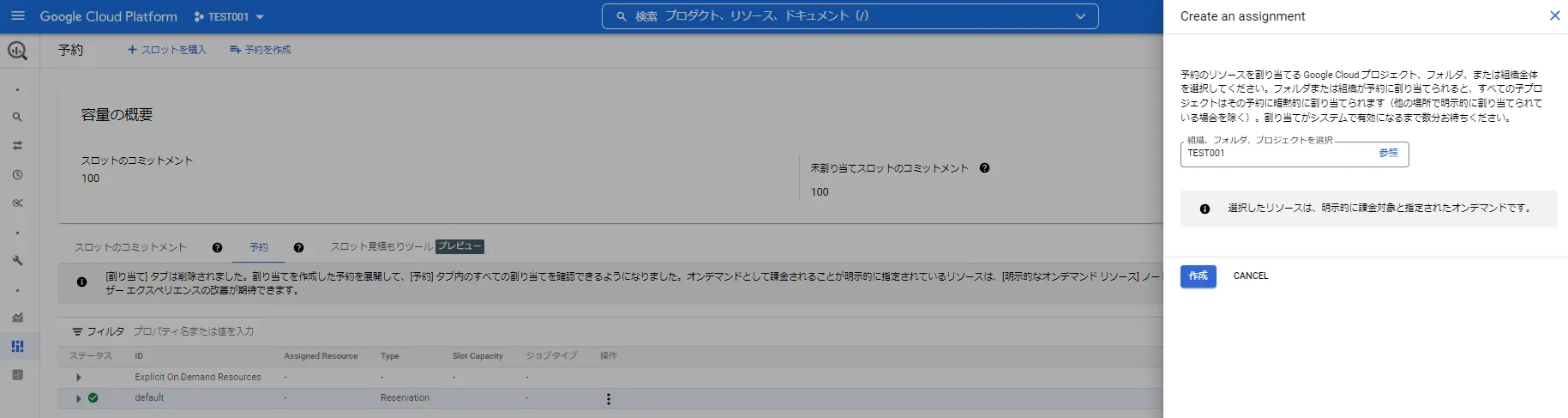
スロットとプロジェクトの紐づけが完了すると、下図のように表示されます。(本手順のプロジェクト名は、"test001-350505" となります)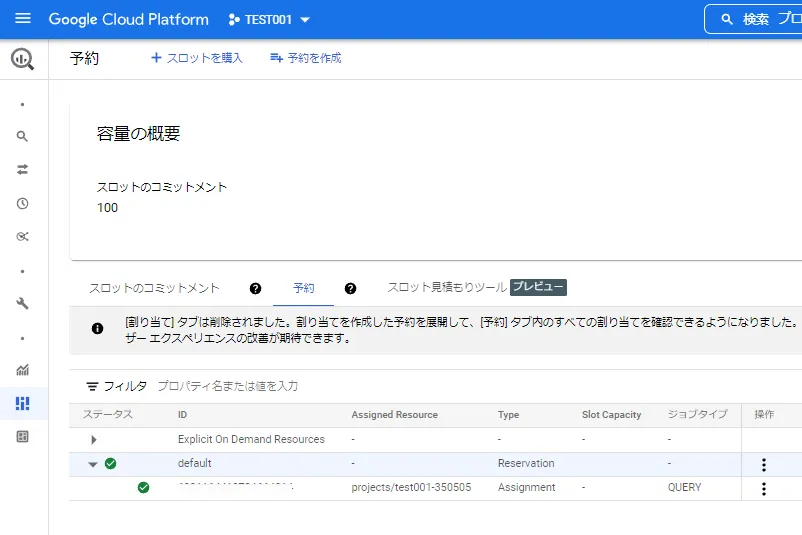
ここまでが、AWS とGoogle Cloud (GCP)の事前設定と疎通確認手順となります。
BigQuery Omni経由のAzureのデータソース接続例
本項では、BigQuery Omni によるAzure への接続手順を解説します。初回設定のみ、Azure、Google Cloud (GCP)側と設定の行き来が発生しますので、下記手順を参考に進めてください。
ここでは、分析対象となるデータは、csv 形式のファイルとしています。BigQuery Omni の対応フォーマットは、AVRO, PARQUET, ORC, CSV, NEWLINE_DELIMITED_JSON, Google Sheetsです。
Google Cloud (GCP)側設定(プロジェクトの作成)
BigQuery Omni と 下記API が有効なプロジェクトを利用します。
Azure 側設定(Azure Active Directory)
テナントID を確認します。(ここではデフォルトのテナントをそのまま使います)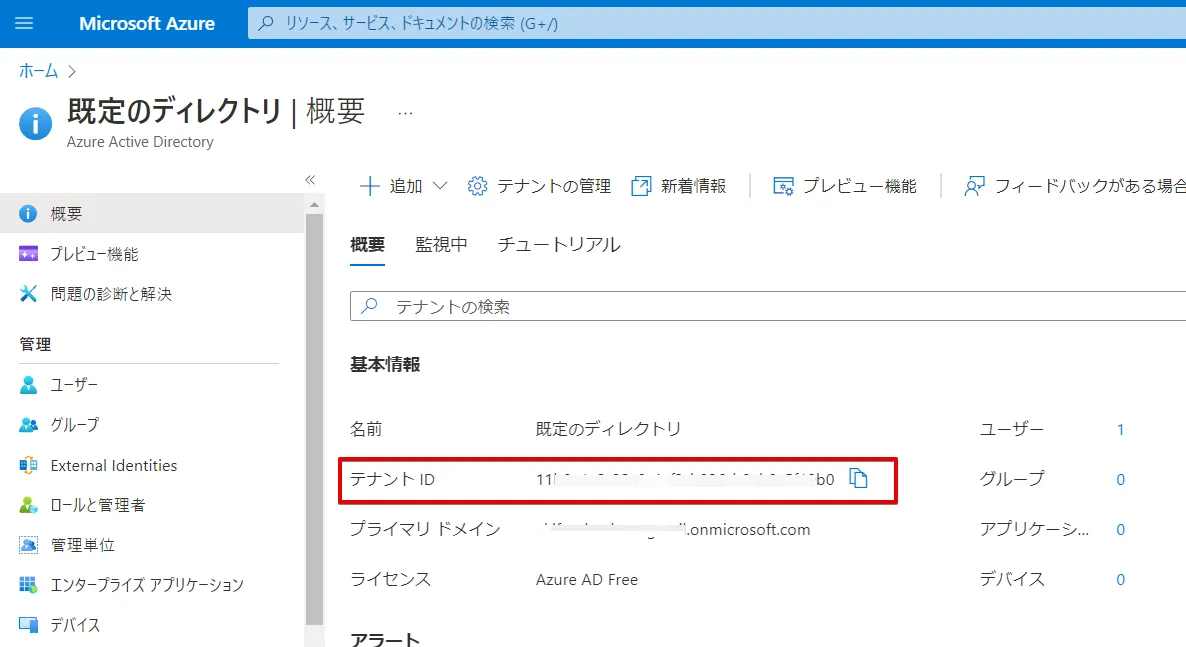
Azure 側設定(ストレージアカウントの作成)
新規ストレージアカウントを作成します。(ここでは、"20220518test01" というアカウント名としました)基本デフォルト設定で問題ありませんが、地域は「(US) East US 2」を選択してください。(2022/05現在、BigQuery Omni はAzure のこのリージョンのみ対応)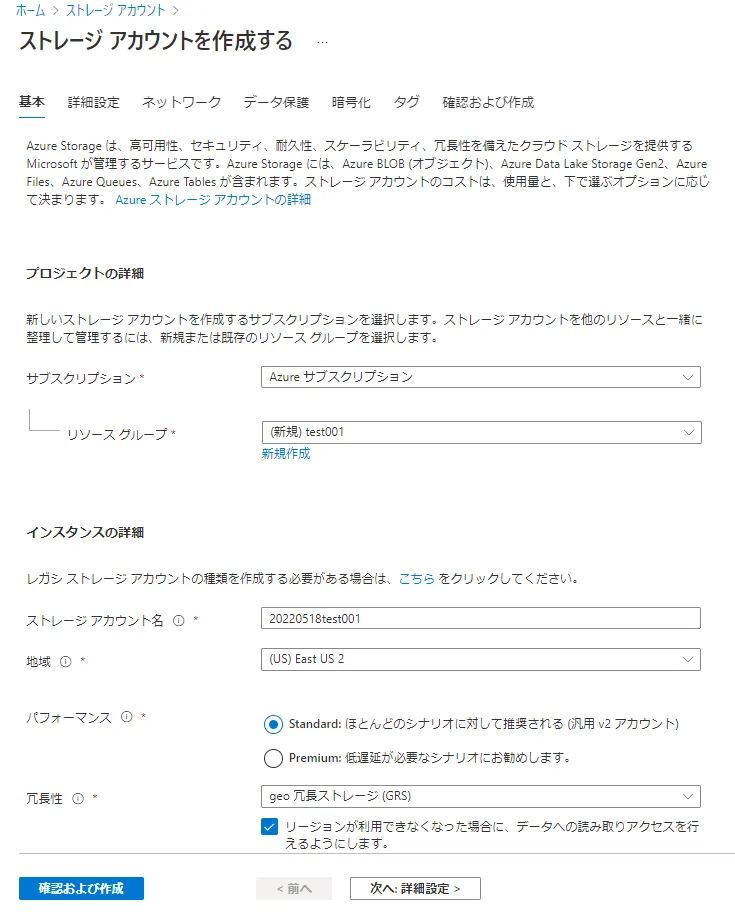

本ストレージアカウントにて、Blob Strage コンテナを作成し、疎通確認用の下記データをもつ "test.csv" を配置します。
BigQueryでのデータソース作成
BigQuery で外部データソースを作成します。
BigQueryでのデータソース設定
先ほど確認したAzure Active Directory テナントIDを下図Azure テナントID に入力します。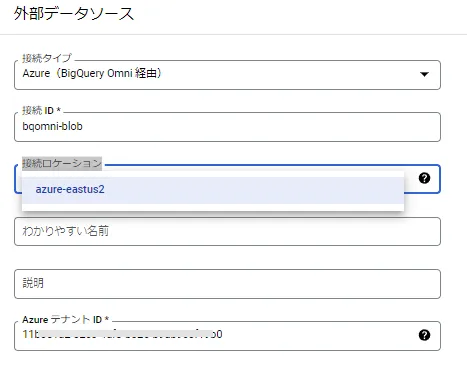
※2022/05現在、Azure の対応リージョンは、米国東部2(us-east-2)となります。
作成された外部接続情報の赤枠情報を確認し、サービスプリンシパル情報の作成のリンクをクリックします。
注意:Azure にログインしますが、本手順ではAzure ポータルにログイン済みのブラウザで操作しています。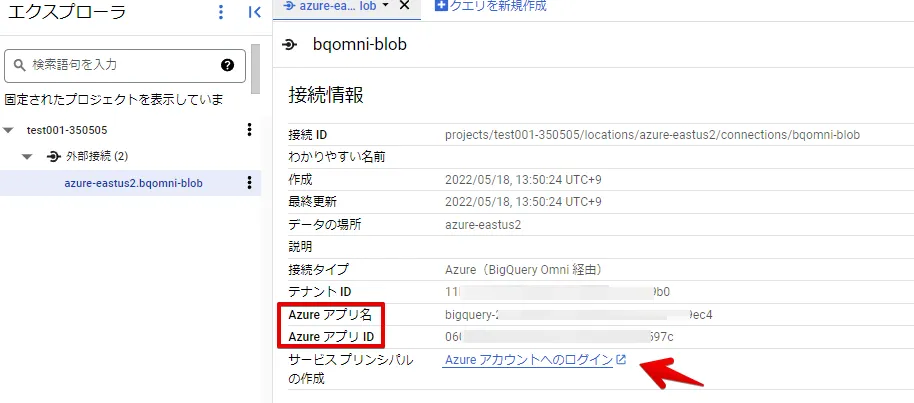
下図の通り、アクセス許可画面が表示されますので、同意チェックボックスをON にして承諾をクリックします。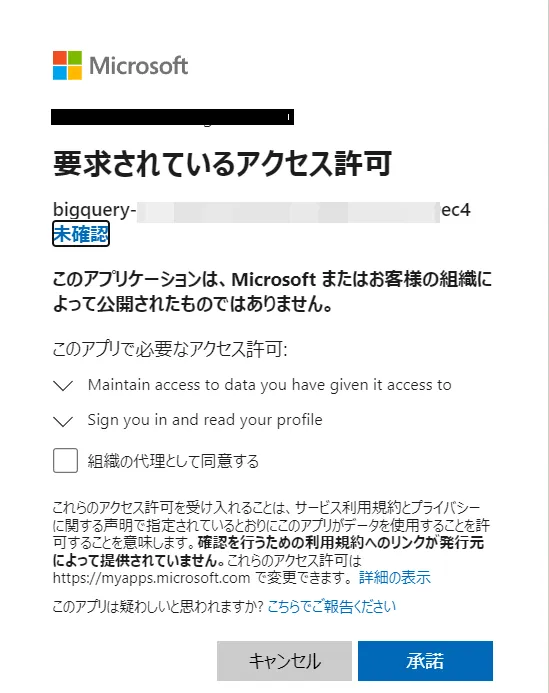
サービスプリンシパルの作成が成功すると、下記画面に遷移します。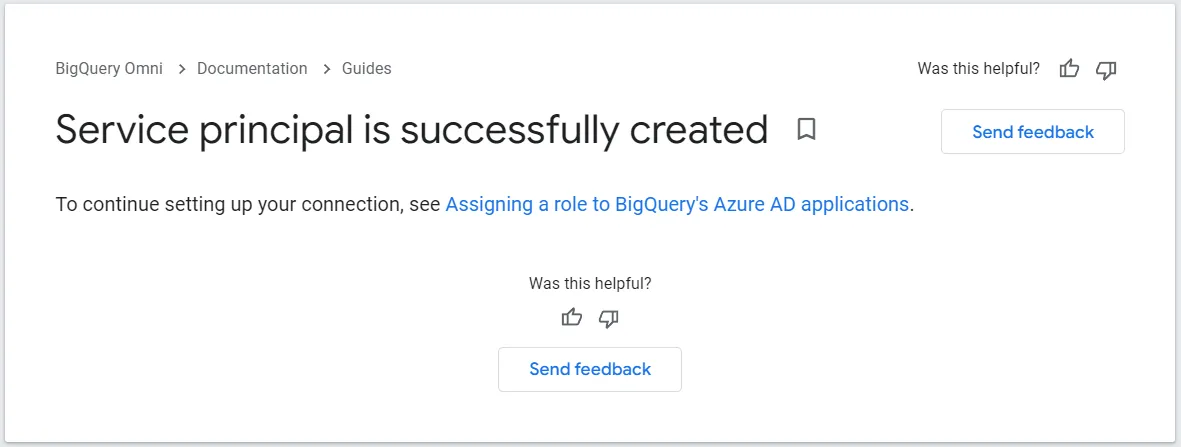
URLフォームを見ると、code がパラメータとして付与されているため、OIDC準拠の認証に準拠していると考えられます。
Azure 側設定(ストレージアカウントのIAM設定)
ストレージアカウントのIAM 設定を行います。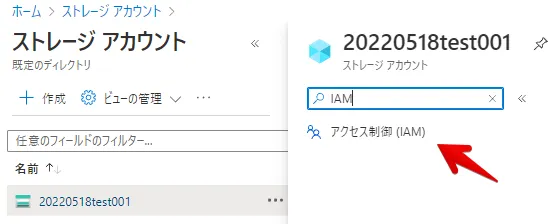
このストレージアカウント内のリソースにアクセス権を付与するため、下図「ロールの割り当てと追加」をクリックします。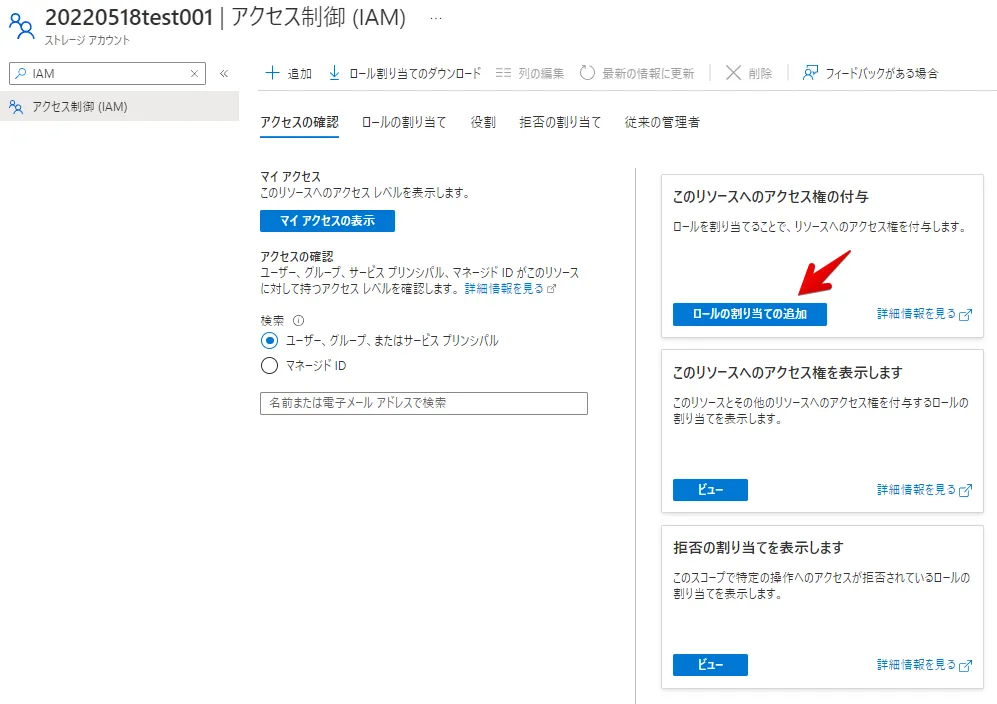
アクセス権を選択します。(ここでは、参照権限のみ選択しています)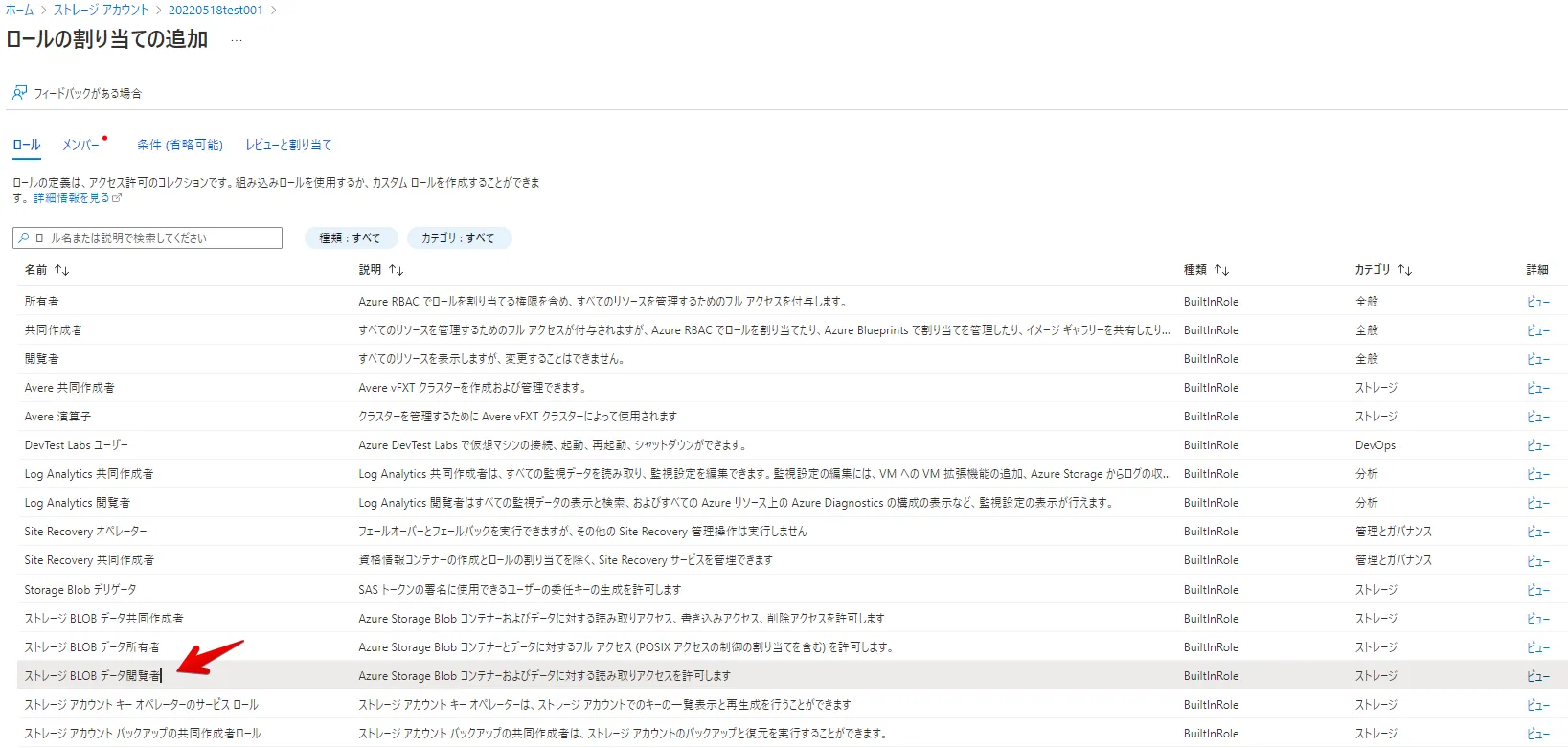
アクセスの割り当て先を下図の通り選択し、メンバーには、先ほどBigQuery 外部接続情報で確認した「Azure アプリ名」を検索し、メンバーに追加します。(この後の手順はデフォルト値で問題ありません)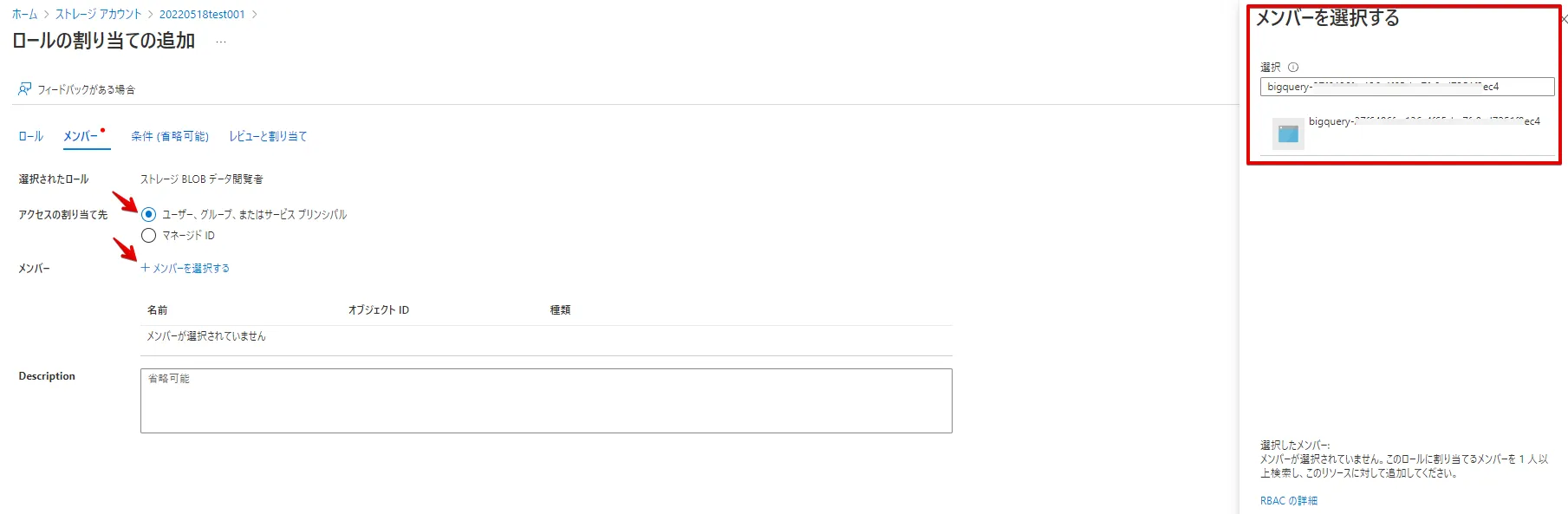
BigQueryのデータセット作成
データセットを作成します。
BigQueryのデータセット設定
データのロケーションは、外部データソース作成で設定したロケーションを指定します。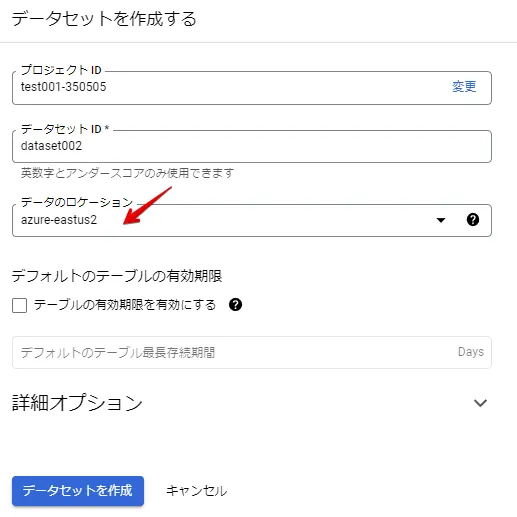
BigQueryでの外部テーブルの作成
外部テーブルを作成します。
BigQueryでの外部テーブルの設定
Blob Strageのパスは、azure://{ストレージアカウントBlob識別名}/{コンテナ}* としています。(これにより、コンテナ直下の "test.csv" を参照できます)
接続ID は自動で検出されます。スキーマの自動検出チェックボックスをONにします。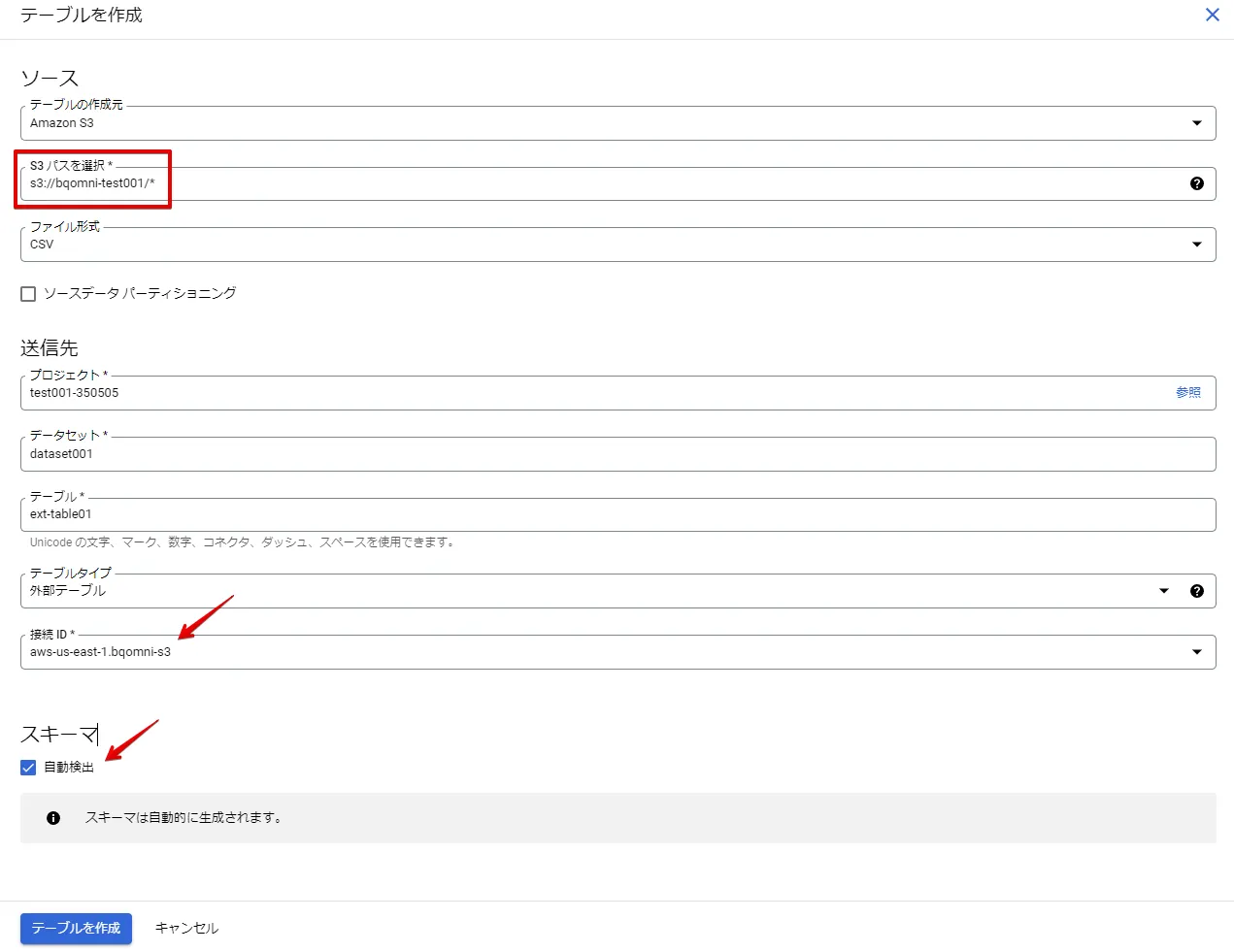
テーブルを作成すると、Blob Strage に配置した "test.csv" のフィールド名が取得できます。これにより、Azure Blob Strage のファイルにアクセスできていることが確認できました。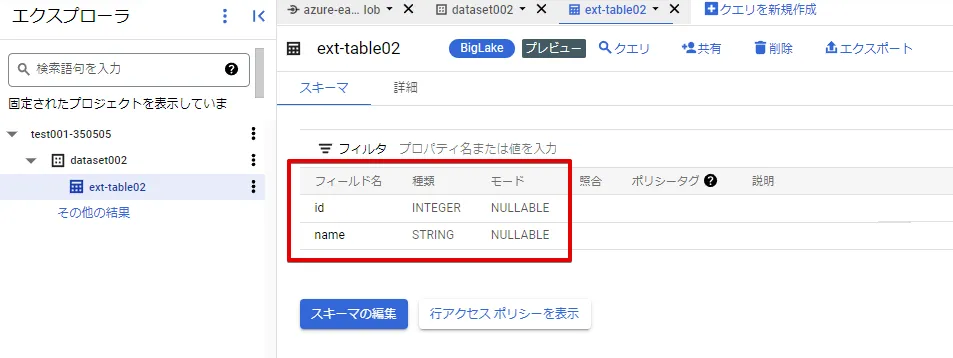
参考:Blob Strage の "test.csv" のデータ
BigQueryとAzure連携確認
外部テーブルの作成の結果、スキーマ情報が自動で検出されていることをもって、BigQuery Omni を経由したAzure との連携確認とします。(実際のクエリによる確認は、次のスロット購入後に可能になります)
BigQueryでのスロット購入
BigQuery Omni の利用には、スロットの購入が必要であり、スロット未購入の状態でクエリを実行すると、下図の通り、購入の注意喚起メッセージが出力されます。
BigQuery のサイドメニュー「容量確認」 をクリックし、スロットを購入します。
課金観点の注意:
- 検証の場合、必ず、「Flex」を選択し、時間課金となるようにしてください。
- AWS側のロケーションの指定ミスをしないようにする必要があります。
- スロット数は100 からとなります。
- 時間単価も比較的高価なため、事後手順のスロット削除を忘れないようにしてください。
購入後、スロットの「予約」タブをクリックし、検証中のGoogle Cloud プロジェクトと紐づけてください。
スロットとプロジェクトの紐づけが完了すると、下図のように表示されます。(本手順のプロジェクト名は、"test001-350505" となります)
ここまでが、Azure とGoogle Cloud の事前設定と疎通確認手順となります。
BigQueryを活用してAWS、Azure内のデータ分析例
それでは、公開データセットをもとに簡単なSQL を実行してみます。
ここでは、お試しで、kaggle で公開されている米国領の教育施設リストを利用します。
https://www.kaggle.com/datasets/satoshidatamoto/colleges-and-universities-a-comprehensive-datasee
本データセットをAWS、Azure のオブジェクトストレージに配置し、スキーマ情報を自動検出すると、下記のように学校名、住所、緯度経度等のフィールド名が取得されます。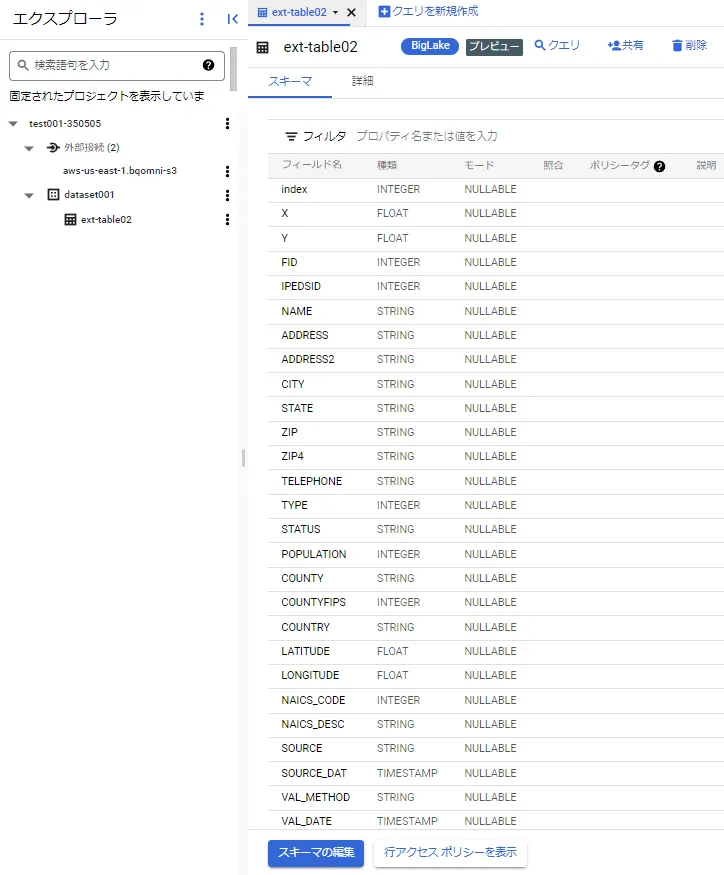
簡単なSQL(州単位のグルーピング)を実行してみると、最も教育施設が多い州はカリフォルニア州で、教育施設が少ないのはアメリカ領サモア、北マリアナ諸島、バージン諸島等であることがわかります。
【州でグルーピング、カウント(昇順)】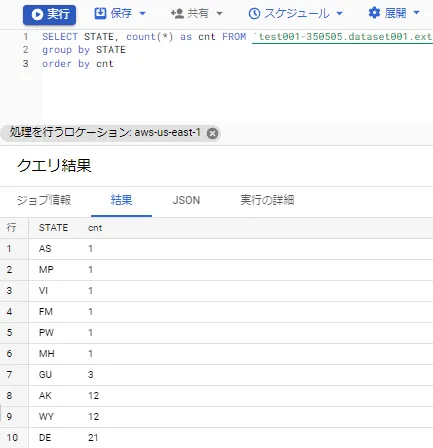
【州でグルーピング、カウント(降順)】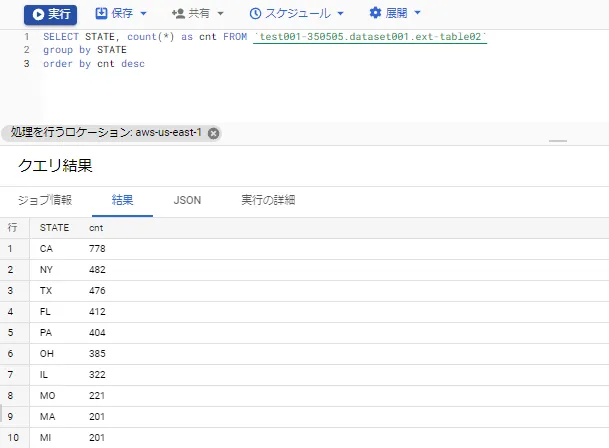
このように、一部制約がありますが、BigQuery の標準SQL が使えるので、すでにAWS、Azure に複数、大規模なデータセットが配置されている場合、外部テーブル経由で直接クエリが可能です。
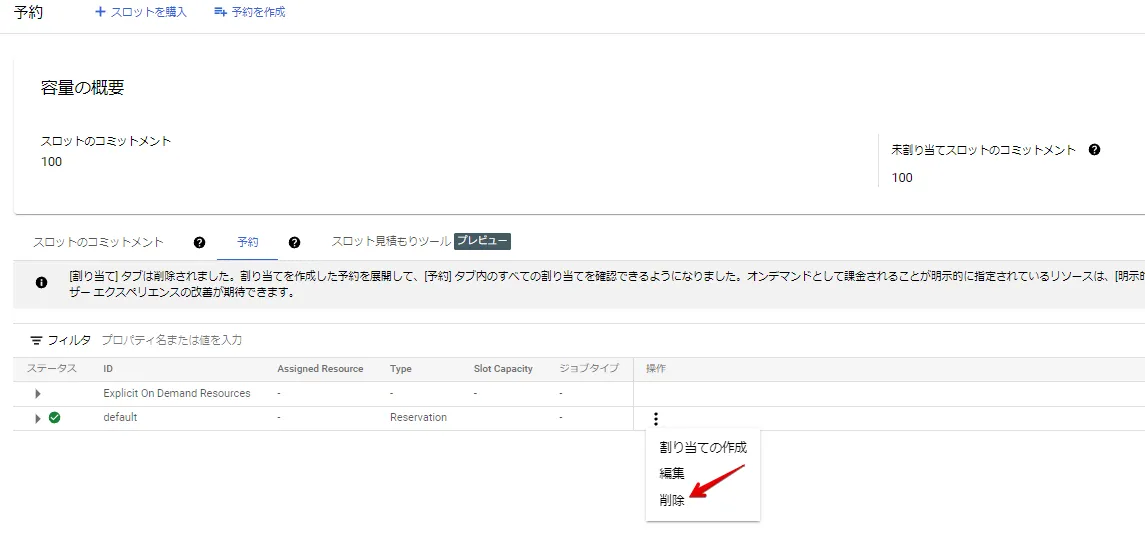
最後に事後手順として、スロットを削除します。default の配下にある予約設定を削除し、スロットを削除します。
予約の削除
スロットの削除
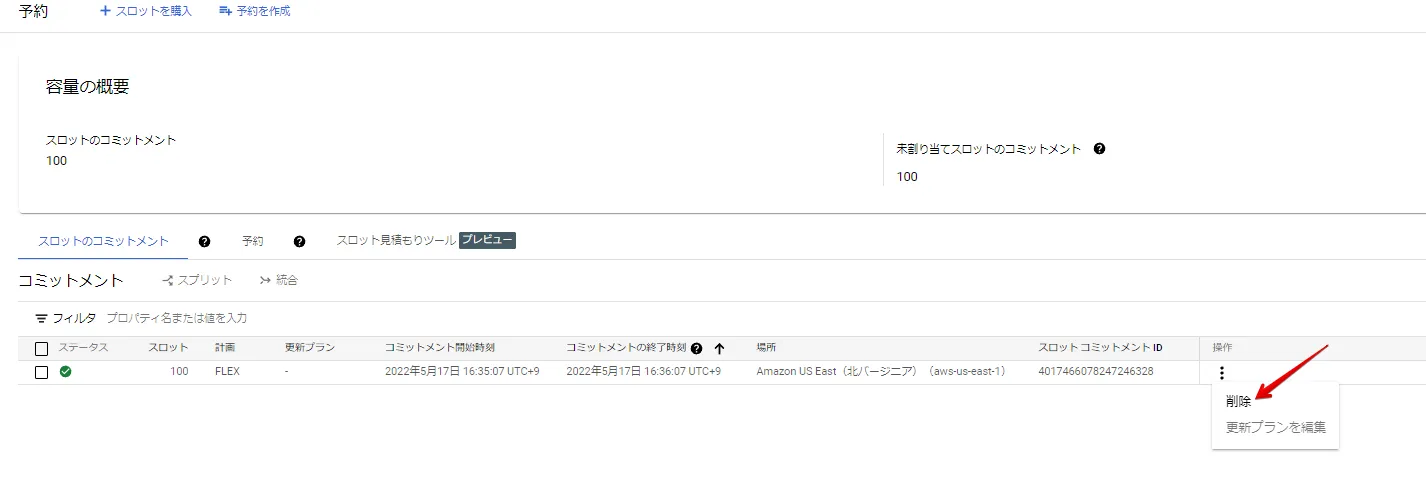
最後に標準クエリを再度実行し、スロットの購入依頼メッセージを表示されれば、スロットが削除済みとなったことを確認できるので確実です。
料金例
BigQuery Omni 用として、スロットを購入することで、AWS や Azure アカウント側でBigQuery Omni 分析に関連する追加料金は発生しません。
| AWS US-East-1(月定額契約) | 月額 $2,500 / 100 スロット |
| AWS US-East-1(年定額契約) | 月額 $2,125 / 100 スロット |
| AWS US-East-1(Flex) | 1時間 $5.00 / 100 スロット |
| Azure-East US 2(月定額契約) | 月額 $2,920 / 100 スロット ※ |
| Azure-East US 2(年定額契約) | 月額 $2,482 / 100 スロット ※ |
| Azure-East US 2(Flex) | 1時間 $5.80/ 100 スロット |
※2022/05/19 現在、Azure の月定額、年定額契約については、下記の通り、期間限定ですが、請求しないという記載があります。(期間変更の際はGoogle から連絡するとのこと)
「*For a limited period of time we are not charging for BigQuery Omni customers for Azure-US-East. We will notify you on changes to billing.」
https://cloud.google.com/bigquery/pricing#bqomni
おわりに
BigQuery のAWS、Azure 連携について、最近の動向を踏まえ、解説しました。Google Cloud のアプローチの通り、昨今では分析対象データのロケーション統合には大規模な工数がかかりますので、マルチクラウド、クロスクラウド目線での手順を押さえておくことは大切かと思います。
BigQuery Omni の対応するAWS、Azure のリージョン拡大や、Biglake によるデータガバナンス等、今後の期待も大きい分野ですので、データ分析におけるクラウド基盤の動向は定期的に観察していきましょう。
G-genは、Google Cloud のプレミアパートナーとして Google Cloud / Google Workspace の請求代行、システム構築から運用、生成 AI の導入に至るまで、企業のより良いクラウド活用に向けて伴走支援いたします。
この記事を読んだ方にオススメのBigQuey関連記事一覧
BigQuery から Cloud Spanner に直接クエリを実行し、トランザクションデータをリアルタイムに分析しよう
効率的なリアルタイム分析を実現! BigQuery を活用したレプリケーションのやり方とは?
【意外と簡単?】オンプレミスの DWH から BigQuery へのデータ移行を徹底解説!
BigQueryで考慮すべきセキュリティとその対策を一挙ご紹介!
【事例付き】 BigQuery を活用したデータ分析基盤の構築方法を3ステップで解説!
最後に本記事作成にあたり参考にしたサイトを記載します。
BigQuery Omni が AWS と Azure で利用可能になり、クロスクラウド データ分析が実現 | Google Cloud Blog
関連記事



Contactお問い合わせ

Google Cloud / Google Workspace導入に関するお問い合わせ