- ホーム
- お役立ち
- Google Service
- 効率的なリアルタイム分析を実現! BigQuery を活用したレプリケーションのやり方とは?
効率的なリアルタイム分析を実現! BigQuery を活用したレプリケーションのやり方とは?
- BigQuery
- リアルタイム分析
本記事は、2021年9月7日に開催された Google の公式イベント「データクラウドサミット」において、 Google の データアナリティクススペシャリストである西村哲徳氏が講演された「 OLTPDB と BigQuery のレプリケーションで実現するリアルタイム分析」のレポート記事となります。
今回はトランザクション系のデータベースと BigQuery を組み合わせたリアルタイム分析のやり方を具体的にご説明します。それぞれのパターンごとに分けて、レプリケーションの手順やポイントをわかりやすくまとめていますので、ぜひ最後までご覧ください。
なお、本記事内で使用している画像に関しては、データクラウドサミット「 OLTPDB と BigQuery のレプリケーションで実現するリアルタイム分析」を出典元として参照しております。
それでは、早速内容を見ていきましょう。
リアルタイム分析の必要性
IDC の調査によると、2025年までに世界で生成されるデータの4分の1以上がリアルタイムデータになる、と言われています。これらのデータは、発生してから早いタイミングで分析を行い、後続のアクションを取ることで、より価値の高いサービスを提供することができます。
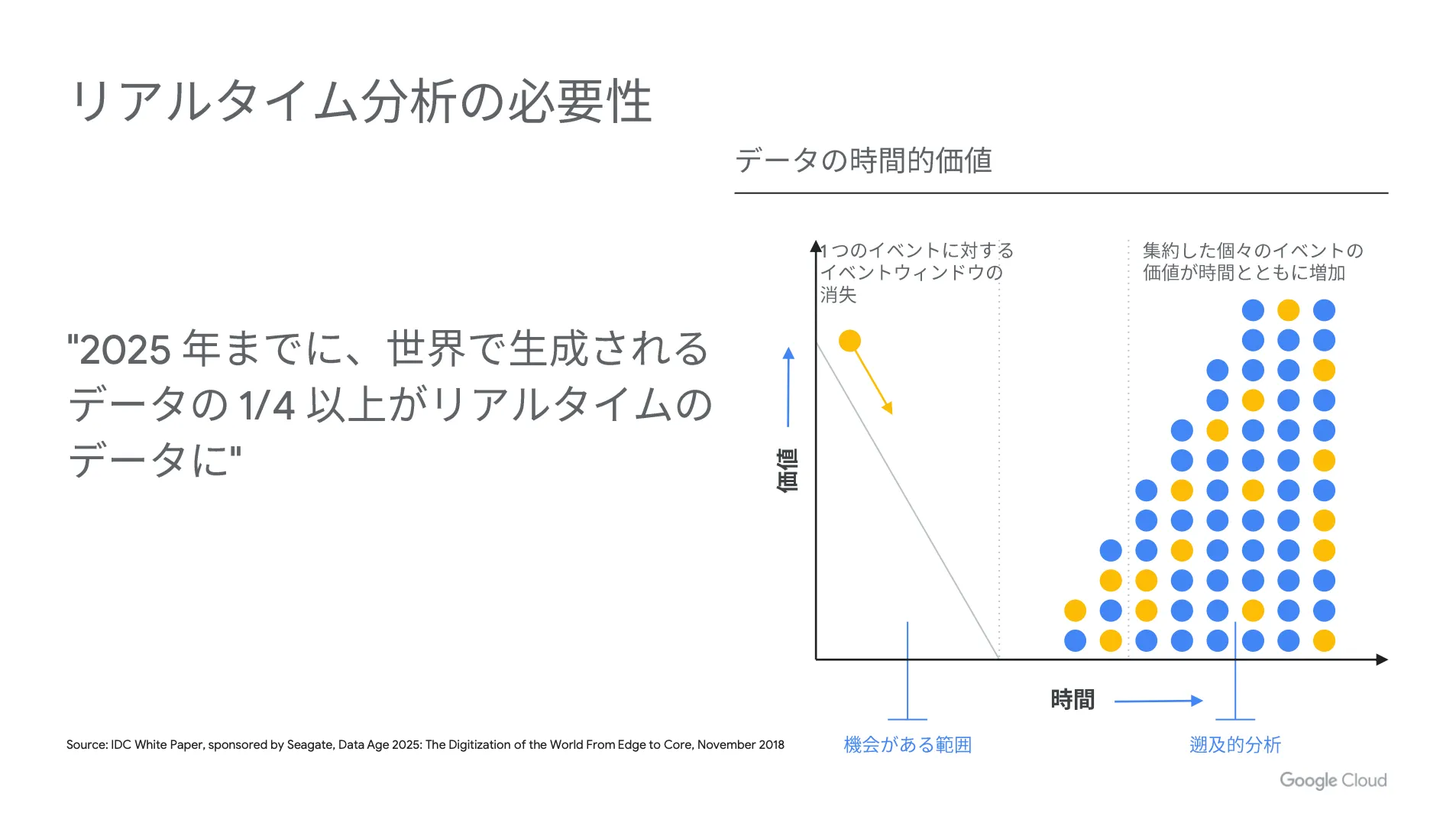
例えば、モバイルアプリケーションの場合、ユーザー行動をもとにレコメンドを送るなど、顧客満足度を高めるためのアクションに繋げられます。これにより、顧客の購買行動を促進できるため、自社の利益最大化を目指す上では大切な要素になります。
このように、企業が保有するデータ量が増加し、顧客ニーズが高度化かつ多様化している現代においては、リアルタイム分析の必要性は年々高まっていると言えるでしょう。
リアルタイム分析のアーキテクチャ
次に、リアルタイム分析を実現するためのアーキテクチャをご説明します。
SoE 分析のアーキテクチャ
SoE は「 Systems of Engagement 」の略であり、 IoT データやモバイルアプリケーションのログなどが SoE の代表的な例になります。
以下、 SoE をリアルタイムに分析する際のアーキテクチャを示した図です。
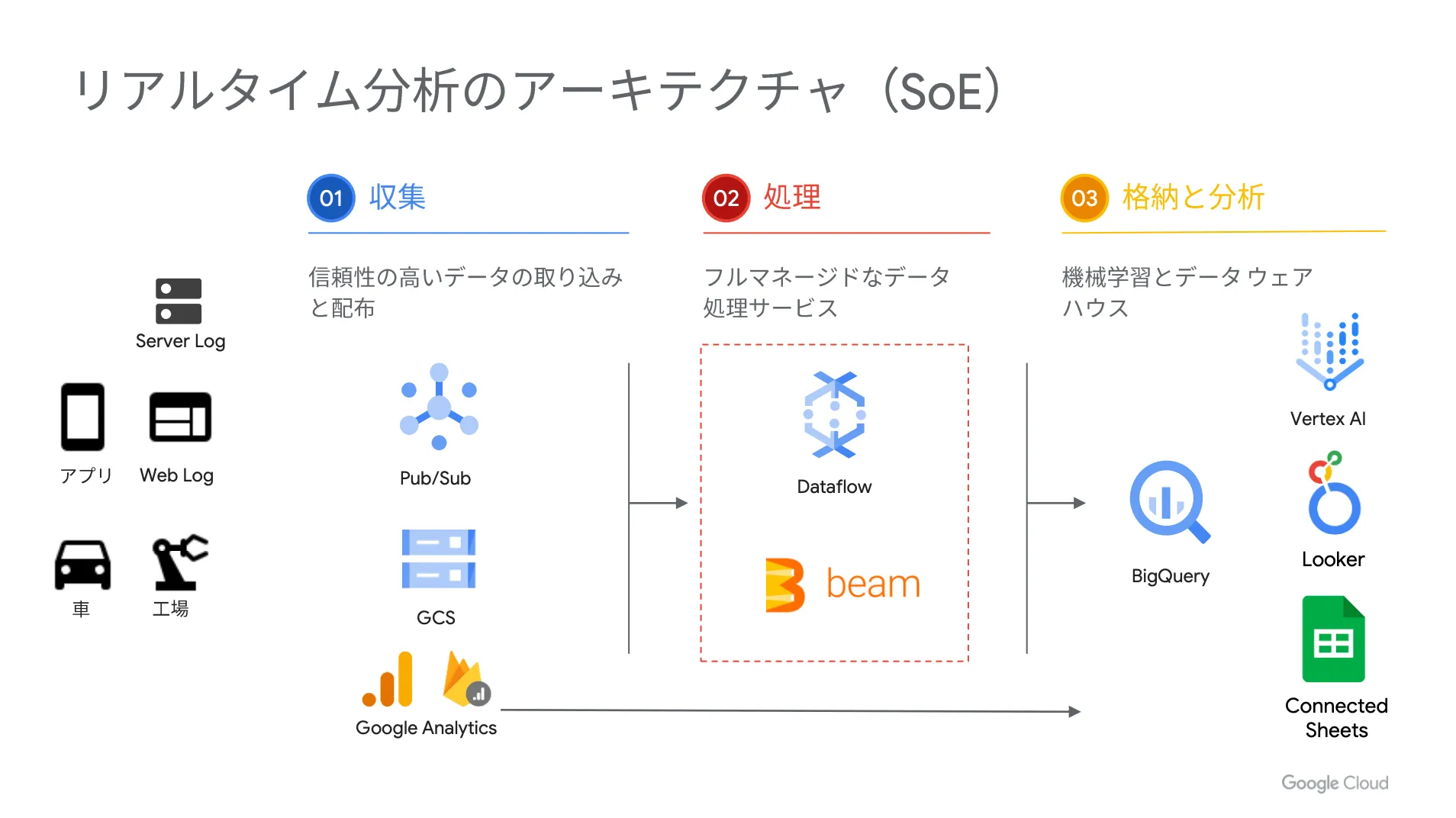
まずは、 Pub / Sub と呼ばれるメッセージングサービスにログを配信し、そのデータを Dataflow と呼ばれるデータ処理サービスで変換して BigQuery に連携します。そうすることで、 BigQuery のデータを Google スプレッドシートや BI ツールなどで分析可能になります。
さらに、 Google Analytics を使っている場合は、 Google Analytics のデータをリアルタイムに BigQuery に連携できます。この点は Google Cloud (GCP)ならではのリアルタイム分析のアーキテクチャだと言えます。
SoR 分析のアーキテクチャ
次に SoR 分析のアーキテクチャをご説明します。 SoR は「 Systems of Record 」の略であり、基幹系のシステムから発生するデータを意味しています。
以下、 SoR をリアルタイムに分析する際のアーキテクチャを示した図です。
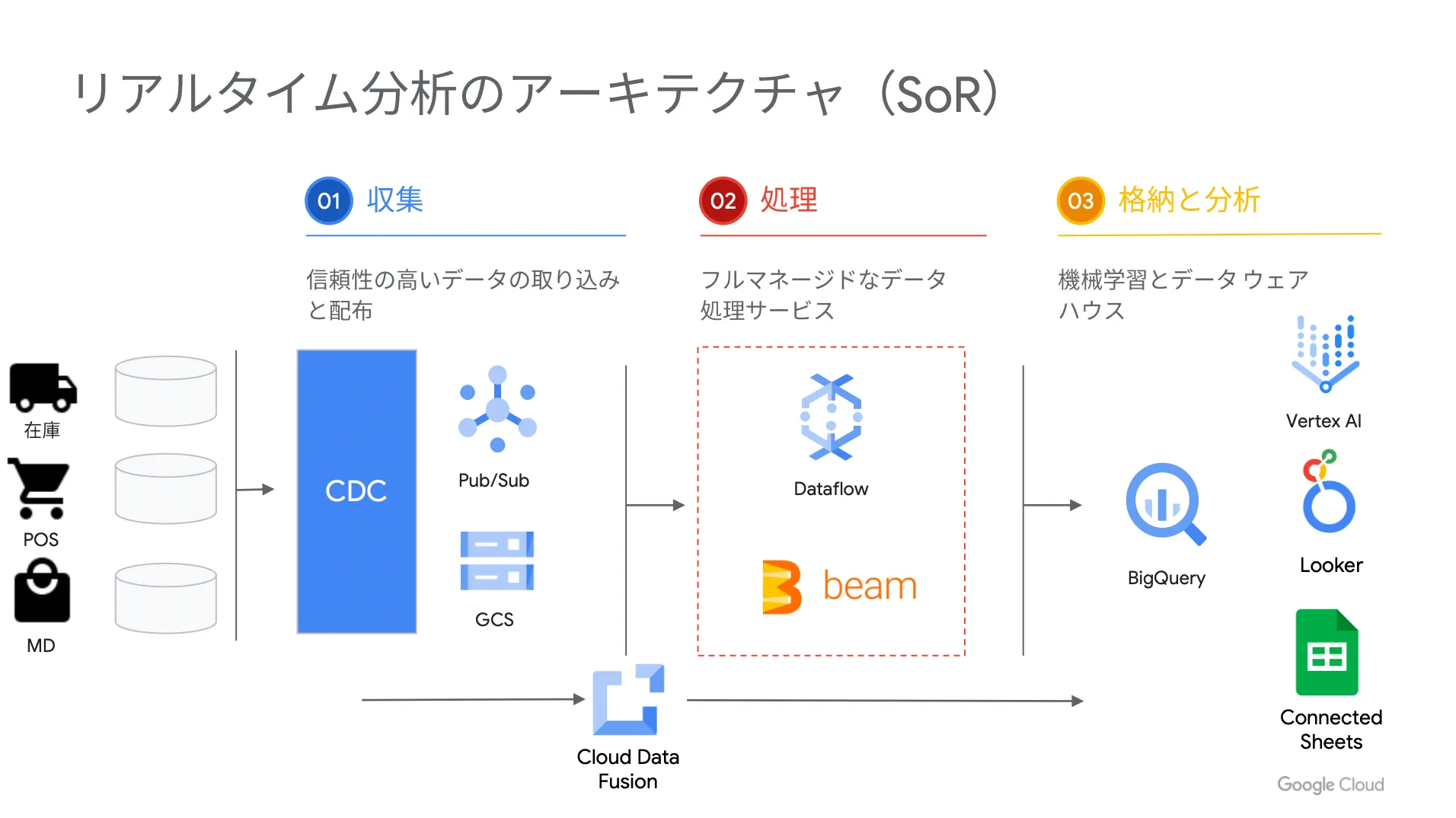
これらのデータをリアルタイムに連携して SoE のデータと組み合わせることで、より深い洞察を得ることができます。ただし、基幹系のデータベースには負荷をかけられないため、夜間にバッチでデータを連携するような方法が一般的であり、リアルタイム性の実現が難しいのが実情です。
このような場合、データベースに負荷をかけることなく、リアルタイムでレプリケーションをするために利用されるのが CDC というソリューションです。次章以降では、 CDC などを活用したレプリケーション方法について、詳しくご紹介します。
CDC とは?
CDC は Change Data Capture の略であり、 Wikipedia では 「 CDC とはデザインパターンのセットであり、変更されたデータを特定および追跡し、変更されたデータを利用し、何らかのアクションを取れるようにするものである」と定義されています。

CDC を使うことで、変更データをキャプチャし、その後のアクションに繋げることが可能になります。例えば、最新データを分析に利用することで迅速な意思決定を実現したり、異なる機種間でデータレプリケーションを行うことでダウンタイムを抑えた形でのデータベース移行やハイブリッドクラウド構成を実現できたりします。

次章以降では、 CDC を活用して BigQuery へレプリケーションを行う際の具体的なやり方をご紹介します。
Google Cloud (GCP)でレプリケーションを行うための方法は、主に以下の3パターンに分けられます。
- Datastream と Dataflow によるレプリケーション
- Datastream と Data Fusion によるレプリケーション
- Data Fusion によるレプリケーション
- Debezium と Dataflow によるレプリケーション
それぞれのやり方について詳しく見ていきましょう。
BigQuery へのレプリケーションのやり方( Datastream と Dataflow によるレプリケーション)
Datastream とは?
まずは Datastream というサービスを簡単にご紹介します。 Datastream はサーバレスかつスケーラブルな CDC サービスです。ユーザー側の管理はほとんど必要なく、手間なく利用できる点が大きな特徴となっています。
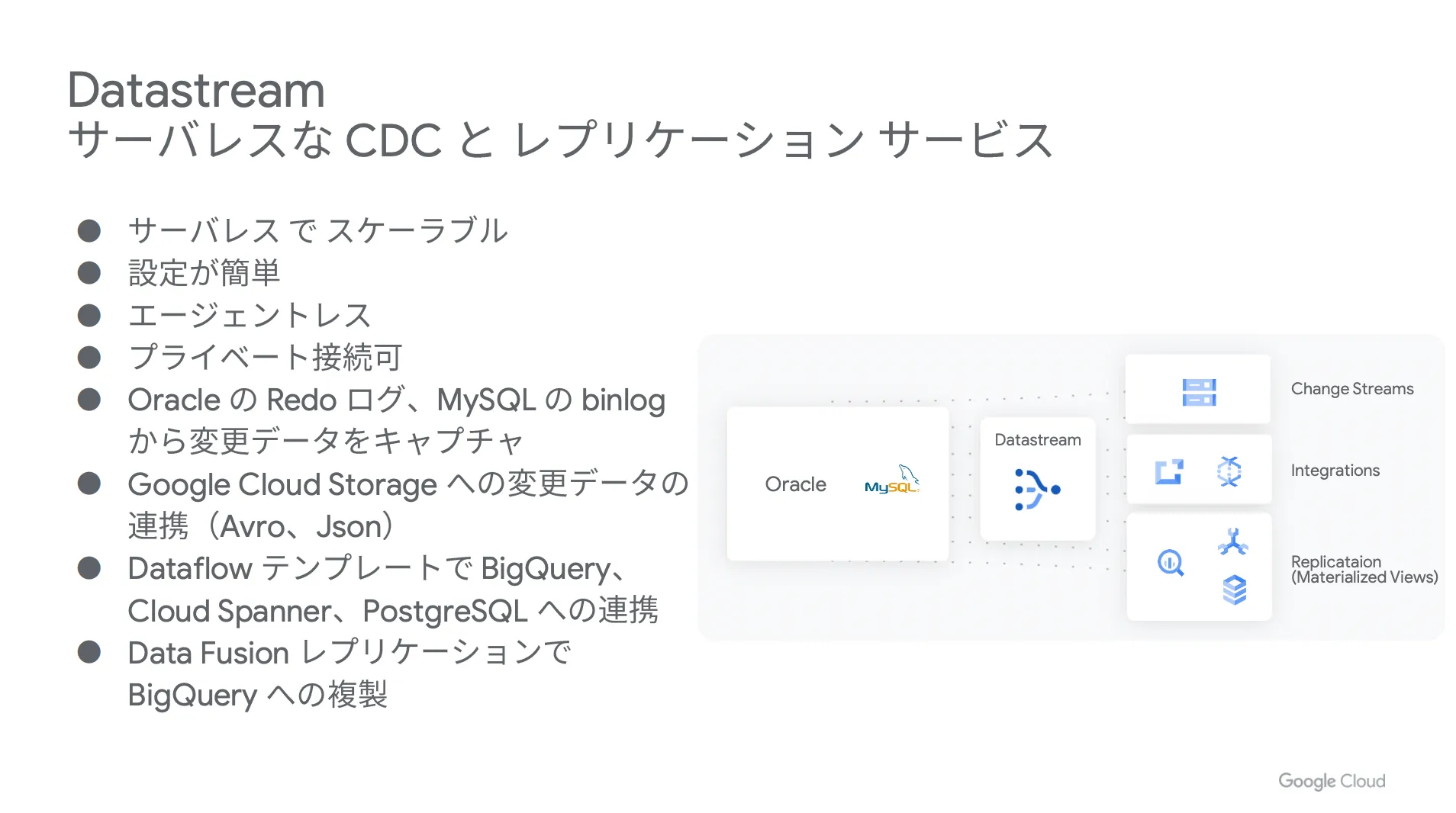
以下、 Datastream の実際の設定画面です。コンソールから簡単に設定を行うことができ、 Google が提供する Dataflow のテンプレートで BigQuery へのレプリケーションをノーコーディングで実現できます。

レプリケーションの流れ
まずは Datastream で Oracle の Redo ログ( MySQL の場合は binlog )から変更データを抽出し、それを変換して Google Cloud Strage (GCS)に変更データを出力します。その後、 Pub / Sub にファイル出力の通知が届き、 Dataflow が Google Cloud Strage (GCS) から変更データを読んで BigQuery に書き込みを行い、 Merge 文で適用するという流れです。
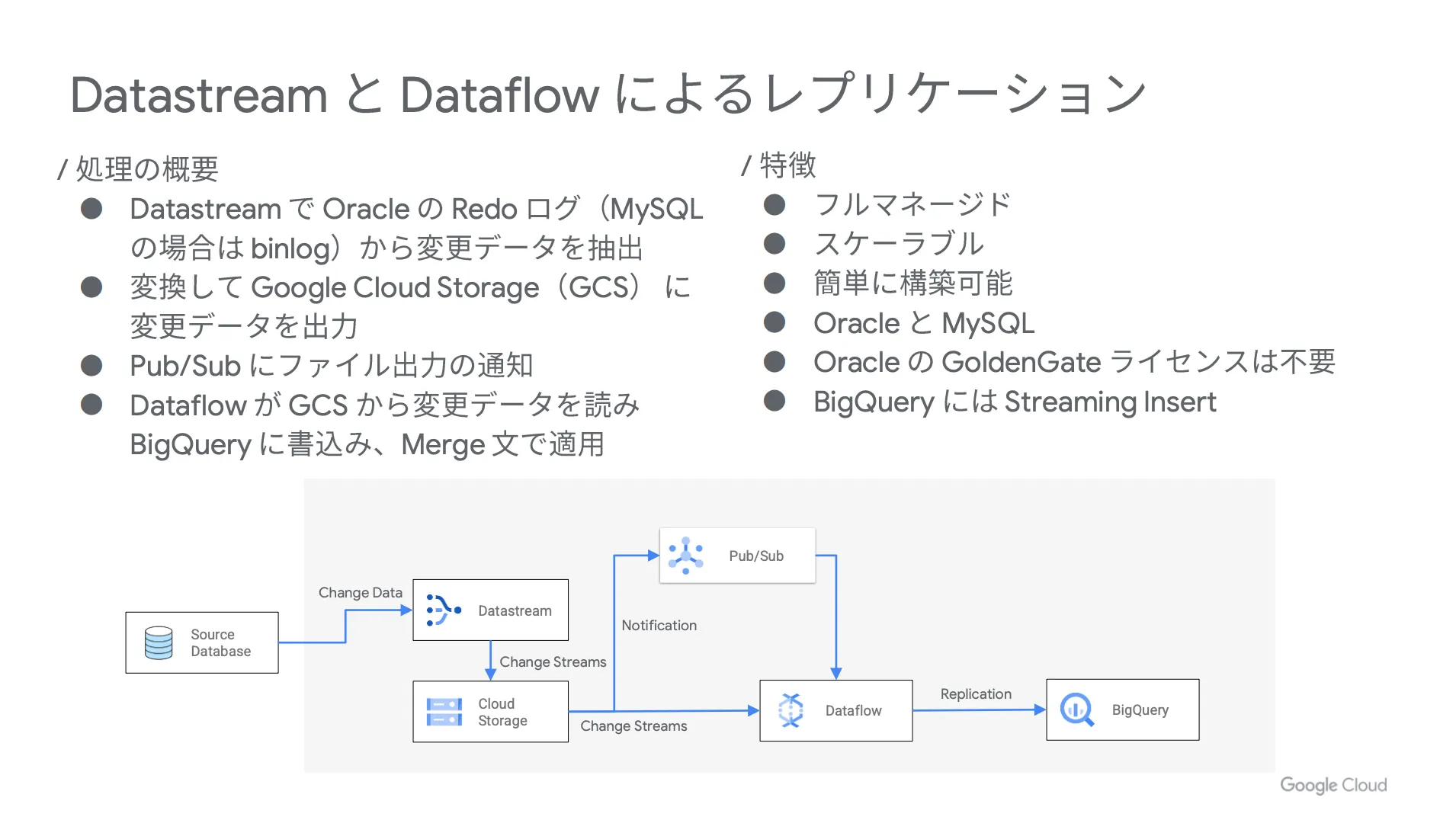
具体的な構成
以下、各サービスの詳細設定を掲載しておきます。構成を検討する際の参考にしてください。

CDC で生成される変更データ
次に CDC で生成される変更データを見ていきましょう。
たくさんの項目がありますが、レプリケーションで利用されるのは下図の青字の部分がメインになります。例えば、「 source_timestamp 」というソース側で変更された時間や「 change_type 」というオペレーションのタイプを示す項目などが挙げられます。
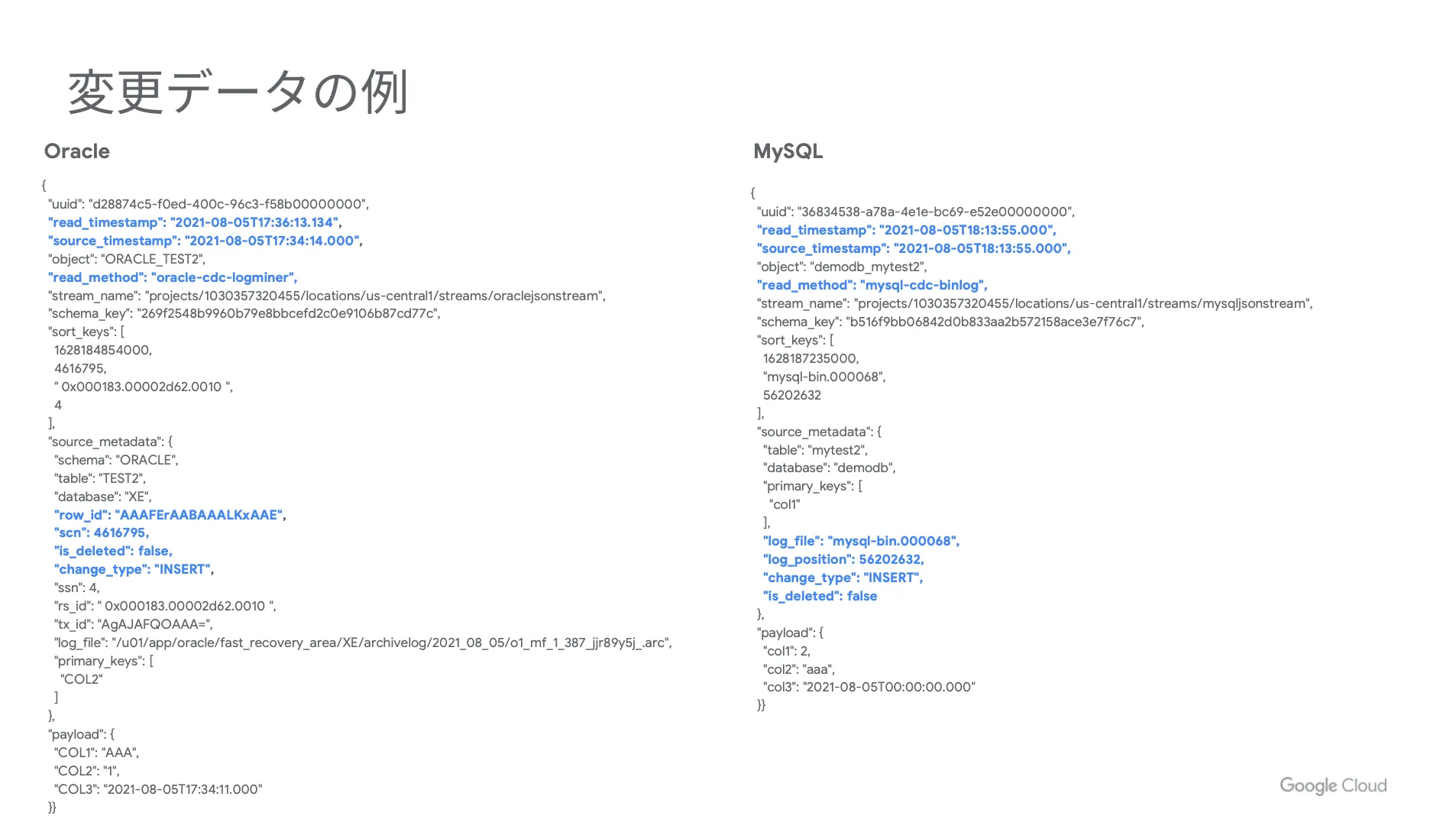
これらを踏まえて、実際の BigQuery のデータの中身を見ていくと、合計2つのデータセットが存在しています。イベントログをそのまま入れるステージング用のデータセットと、ログを適用した実テーブルが入っているレプリカ用のデータセットです。
そして、下図で青色に囲んでいる部分がメタデータに該当し、このメタデータを使って最新のデータログを適用するような Merge 文を書き、テーブルに適用するような流れになります。

実際の Merge 文
以下、参考までに実際の Merge 文を掲載しておきます。ポイントとなる部分を青字で示しています。

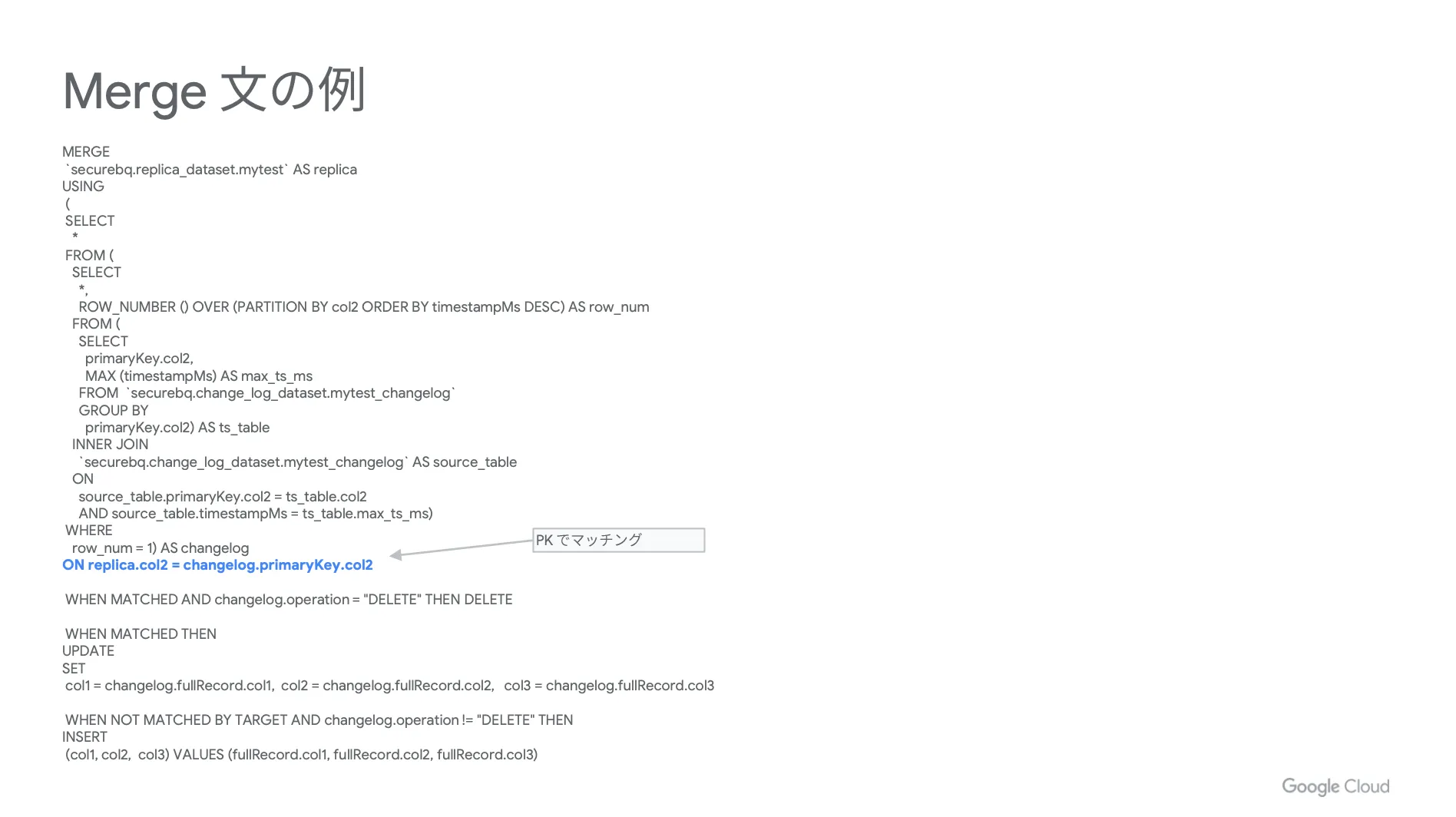
大前提として、 Merge 文の考え方はどのレプリケーションパターンでも共通しています。同じ PK を持つデータが実テーブルとステージングのテーブルに入っており、ステージングに入っている最新のログが削除となる場合は実テーブルから削除します。また、削除とならない場合はアップデートを行い、マッチングしない場合はインサートを行います。
主な制限( Datastream )
最後に、本構成における制限をご紹介します。 Datastream を活用する上で注意すべきポイントになりますので、事前に理解しておいてください。

BigQuery へのレプリケーションのやり方( Datastream と Data Fusion によるレプリケーション)
次に、 Datastream と Data Fusion を活用したレプリケーションのやり方をご紹介します。
レプリケーションの流れ
まずは Datastream で Oracle の Redo ログから変更データを抽出し、それを変換して Google Cloud Strage (GCS)に変更データを出力します。その後、 Data Fusion が Google Cloud Strage (GCS) から変更データを読んで BigQuery にロードを行い、 Merge 文で適用するという流れです。
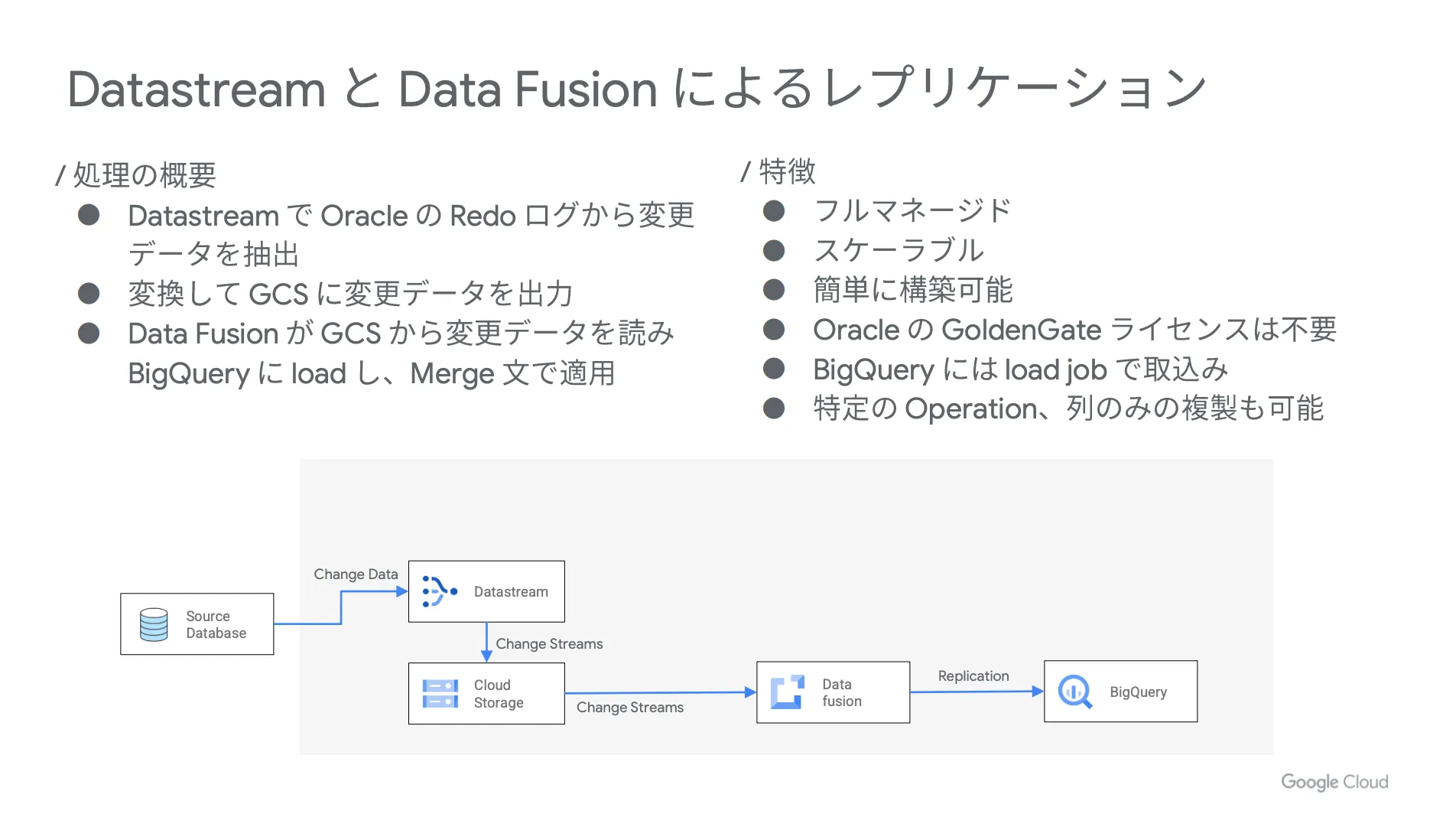
具体的な構成
以下、各サービスの詳細設定を掲載しておきます。構成を検討する際の参考にしてください。

実際の Merge 文
以下、参考までに実際の Merge 文を掲載しておきます。ポイントとなる部分を青字で示しています。

主な制限(一部)
最後に、本構成における制限をご紹介します。事前にチェックしておきましょう。

BigQuery へのレプリケーションのやり方( Data Fusion によるレプリケーション)
続いて、 Data Fusion で CDC から適用まですべてを完結するレプリケーションのパターンをご紹介します。
レプリケーションの流れ
まずは Data Fusion が MySQL の binlog ( SQL Server の場合は変更テーブル)から変更データを抽出し、それを変換して BigQuery にロードを行い、 Merge 文で適用するという流れです。
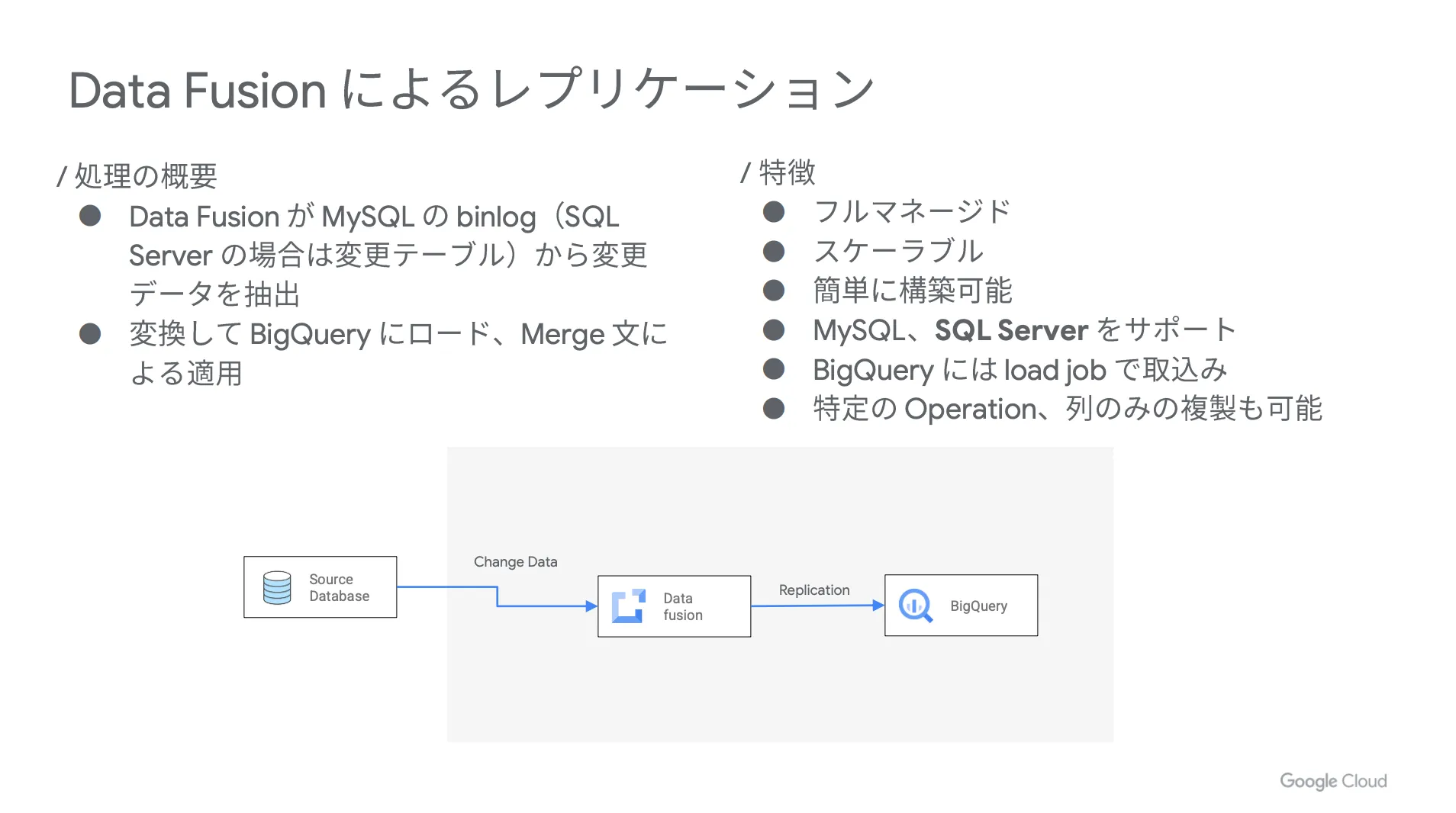
具体的な構成
以下、各サービスの詳細設定を掲載しておきます。構成を検討する際の参考にしてください。

実際の Merge 文
以下、参考までに実際の Merge 文を掲載しておきます。ポイントとなる部分を青字で示しています。

主な制限(一部)
最後に、本構成における制限をご紹介します。事前にチェックしておきましょう。

BigQuery へのレプリケーションのやり方( Debezium と Dataflow によるレプリケーション)
最後に、 Debezium と Dataflow を活用したレプリケーションのやり方をご紹介します。
レプリケーションの流れ
まずは Debezium で MySQL の binlog から変更データを抽出し、 Pub / Sub に配信します。また、スキーマ情報は Data Catalog に保存される形になり、それを Dataflow で変換して BigQuery に書き込み、 Merge 文で適用するという流れです。
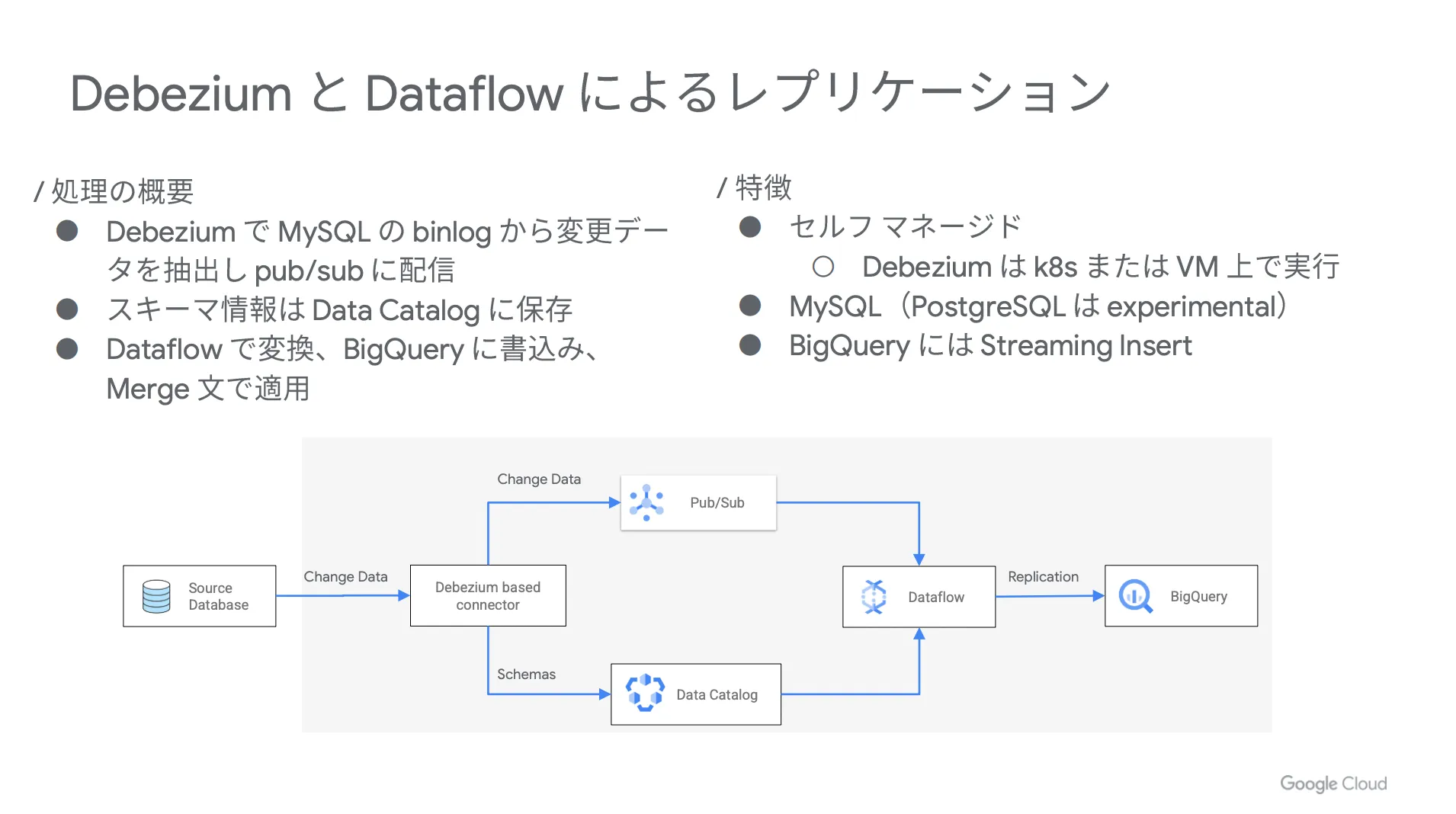
具体的な構成
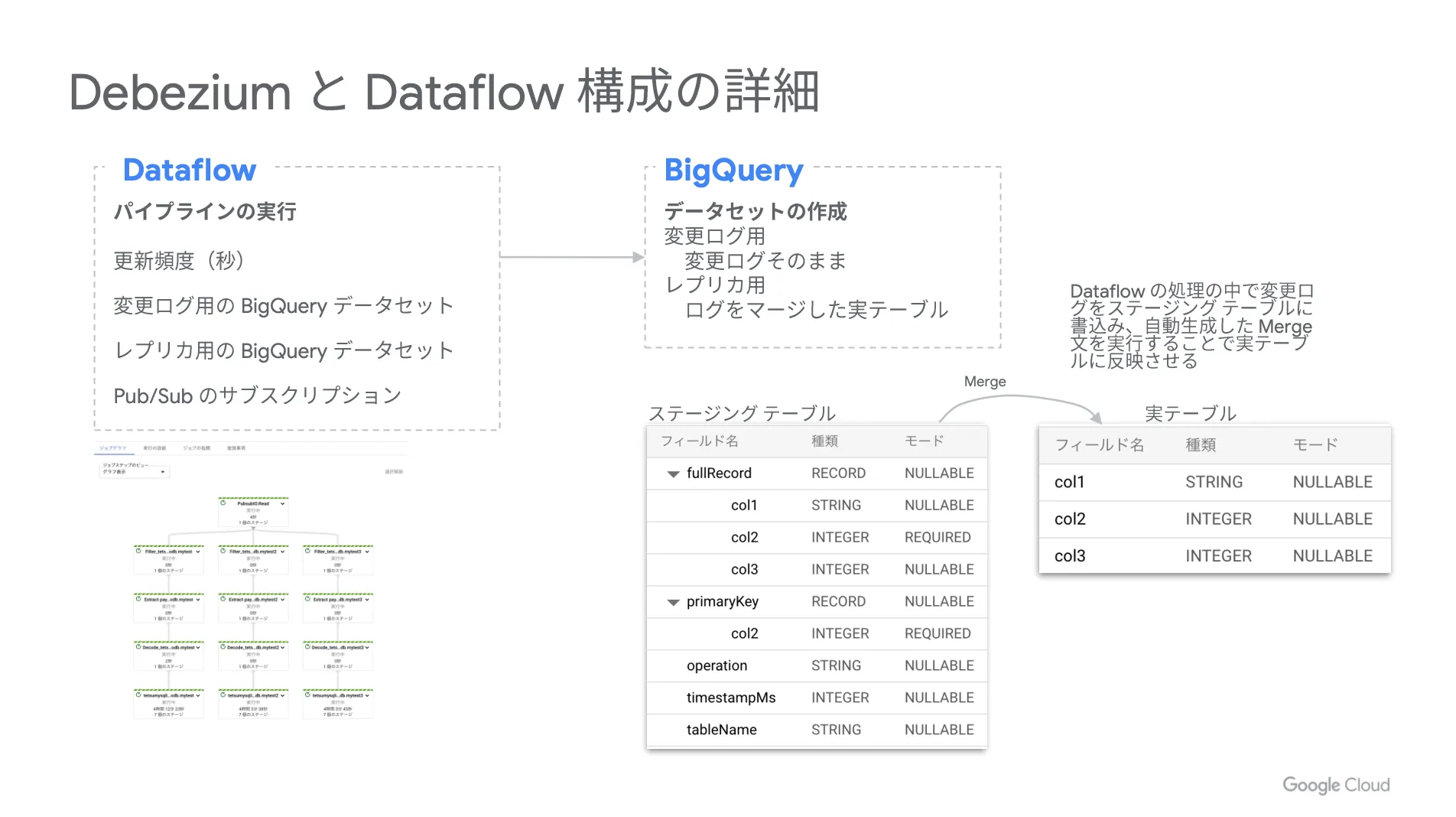
以下、各サービスの詳細設定を掲載しておきます。構成を検討する際の参考にしてください。

続いて、 Dataflow の設定は以下の通りです。
実際の Merge 文
以下、参考までに実際の Merge 文を掲載しておきます。ポイントとなる部分を青字で示しています。
主な制限(一部)
最後に、本構成における制限をご紹介します。事前にチェックしておきましょう。

まとめ
本記事では、トランザクション系のデータベースと BigQuery をリアルタイムでどのように連携していくのか、という観点で具体的な内容をご説明しました。各パターンにおけるレプリケーションのやり方をご理解いただけましたでしょうか。
最後に、今回ご紹介したレプリケーションのパターンを表にまとめます。
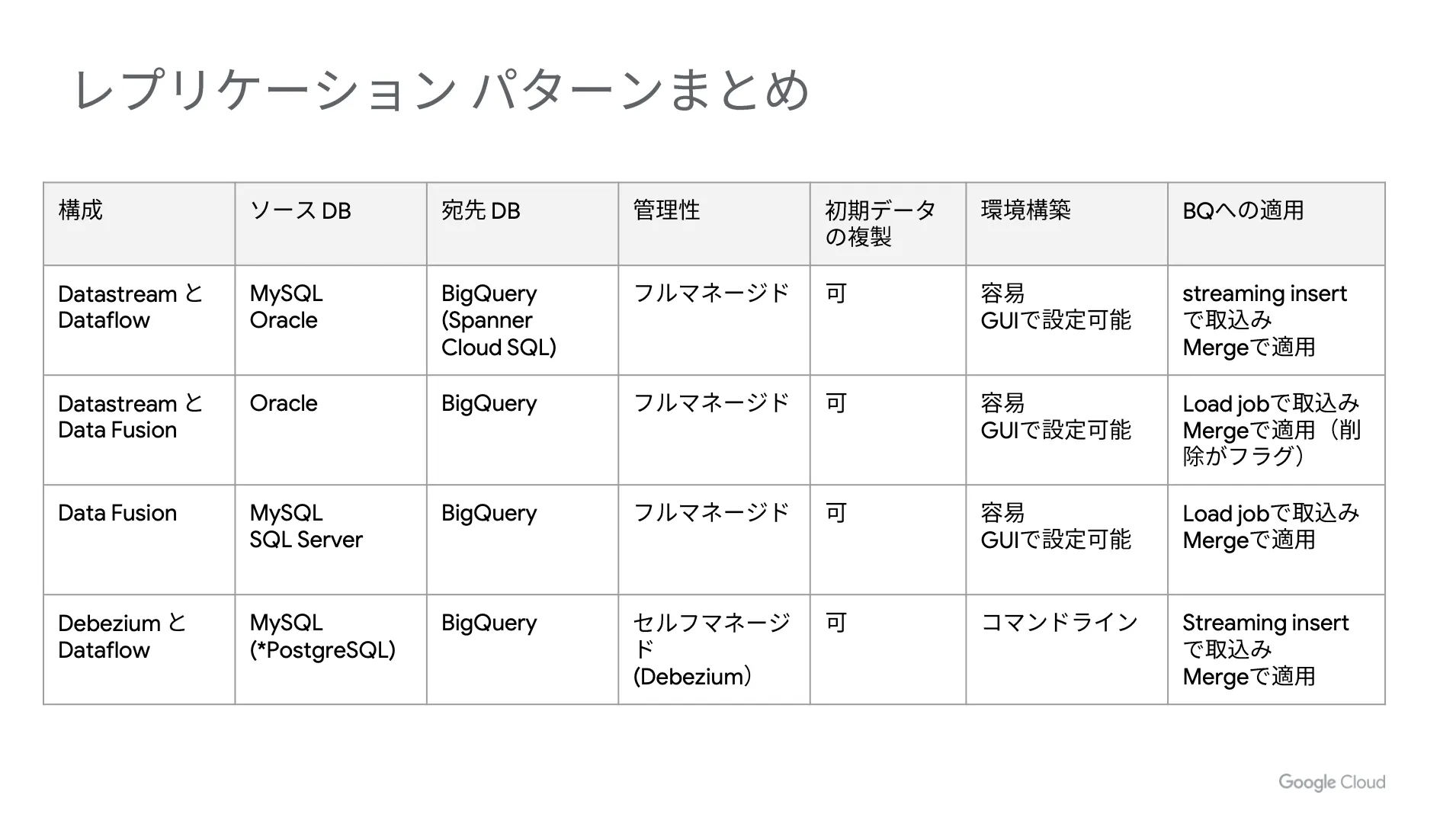
どのパターンも基本的な処理の流れは同じなので、まずは「どのソース DB を使うか」という点をベースに考えてみてください。その後は、構築の容易性や管理性という観点で、要件に合わせて最適なパターンを選択しましょう。
ここまでご説明したように、 CDC を利用することでトランザクション系のデータベースをリアルタイム分析のデータソースとして利用でき、より素早く深い洞察を得ることができます。本記事を参考にして、 Google Cloud (GCP)でのレプリケーションをご検討ください。
G-genは、Google Cloud のプレミアパートナーとして Google Cloud / Google Workspace の請求代行、システム構築から運用、生成 AI の導入に至るまで、企業のより良いクラウド活用に向けて伴走支援いたします。
関連記事


Contactお問い合わせ

Google Cloud / Google Workspace導入に関するお問い合わせ