RAGとは?仕組みやメリット、注意点などを徹底解説!
- 生成AI
RAG ( Retrieval - Augmented Generation )という言葉をご存知でしょうか?自然言語処理( NLP )の分野で注目されている手法の一つであり、複雑な質問応答や生成タスクにおいて、 AI のパフォーマンスを向上させるために用いられます。
本記事では、 RAG とは何かという基礎的な内容から、 RAG の仕組みやメリット、注意点など、あらゆる観点から一挙にご紹介します。 RAG について理解を深めたい方は、ぜひ最後までご覧ください。
RAG( Retrieval - Augmented Generation )とは?
まずは、 RAG( Retrieval - Augmented Generation )の基礎知識を理解しておきましょう。 RAG の概要とあわせて、混同しやすい言葉との違いについても解説します。
RAG の概要説明
RAG とは、生成 AI の品質・性能を向上させるための仕組みであり、主に自然言語処理の分野で注目を集めています。なお、自然言語処理とは、人間が読み書きするような自然な文章を AI が理解・生成するための処理を意味します。
RAG の特徴として、 AI が独自に情報を生成するのではなく、信頼性の高い情報源のデータを利用して回答を生成する点が挙げられます。例えば、ユーザーからのリクエストに対して、関連情報をデータベースや Web サイトから検索し、それらをもとにユーザーに返すための回答を生成します。
これにより、誤った情報が生成されることを回避し、より正確性の高い回答を得ることができます。そのため、 RAG を活用することで、生成 AI の品質を向上させることができ、結果として自社のビジネス成長や競合優位性に繋がります。
RAG とセマンティック検索の違い
セマンティック検索とは、検索エンジンが検索キーワードの意味を理解し、その意図に沿った結果を提供するための検索技術です。例えば、同義語や関連語、文脈などを考慮した検索が可能であり、ユーザーが求める情報を的確に返すことができます。
RAG とセマンティック検索は、 AI の精度向上に繋がる点は共通していますが、セマンティック検索は自然言語処理や機械学習をもとに適切な検索結果を抽出するのに対して、 RAG は、自然言語処理や機械学習に加えて、外部データを利用してユーザーの意図に沿った検索結果を抽出します。このように、外部データを利用するか否かが両者の大きな違いだということを覚えておきましょう。
以下、 RAG とセマンティック検索の違いを表にまとめます。
|
RAG |
セマンティック検索 |
|
|
目的 |
モデルの性能強化(正確性・信頼性の向上) |
検索キーワードに沿った適切な検索結果の抽出 |
|
特徴 |
自然言語処理と機械学習に加えて外部データを利用 |
自然言語処理と機械学習 |
|
生成 or 検索 |
生成・検索 |
検索 |
|
主な技術 |
自然言語処理、生成モデルと検索エンジン技術の組み合わせ |
ベクトル検索、クエリとドキュメントの意味的類似性の評価 |
|
出力内容 |
検索結果をもとにした新しいテキスト |
検索結果に基づく既存の文書・データ |
|
検索の焦点 |
情報生成に必要な関連データの取得 |
クエリと関連するデータの意味に基づいた検索 |
|
適用シーン |
対話型 AI 、カスタマーサポートの自動応答など |
ドキュメント検索、データベース検索など |
|
情報源 |
外部の知識ベースや検索エンジンから取得したデータ |
既存のデータベースに存在するデータ |
|
精度の向上手段 |
検索アルゴリズムや大規模な知識ベースを組み合わせることで精度が向上 |
言語モデルの改善やより広範なデータセットの活用で精度が向上 |
|
AI モデルの役割 |
質問に対してコンテキストに合った応答を検索・生成 |
クエリとドキュメントの意味的類似性を評価して関連情報を特定 |
|
情報のリアルタイム性 |
外部データの活用により、リアルタイムな情報を利用できる |
事前学習に利用するデータの鮮度に左右される |
RAG と LLM (大規模言語モデル)との関係性
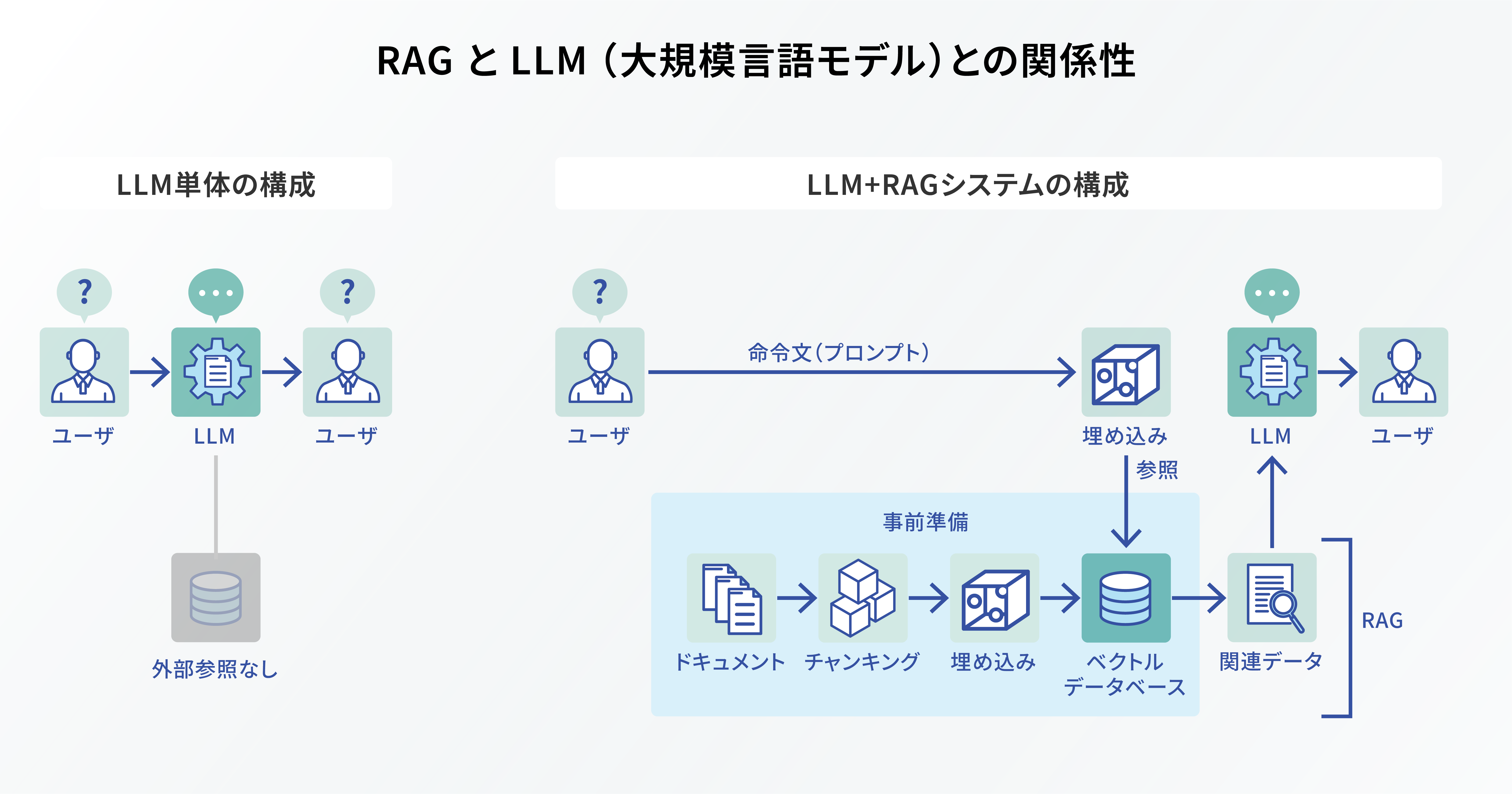
LLM (大規模言語モデル)とは、膨大なテキストデータをもとに学習し、それらの学習データと人間によるインプットを掛け合わせて、自然言語の生成・要約などを行う深層学習モデルです。学習データの例としては、 Web 情報や書籍、ニュース記事、会話ログなどが挙げられます。
しかし、 LLM は事前にインプットした学習用データを利用するため、常に最新のデータで学習を継続的に行わなければ、情報が古くなってしまうという課題がありました。そこで、この課題を解決するために RAG が有効な手段になります。
例えば、ユーザーが「最新のスマートフォンのレビューを教えて」と AI に質問するシーンを考えてみましょう。 LLM 単体では、訓練データが古い場合は最新情報を提供することは困難ですが、 RAG を利用すれば最新のレビュー記事などを検索し、その情報を LLM が取り入れて適切な回答を提供できます。
ただし、これは構築した RAG が最新データを取得できることが大前提となる話です。仮に、社内データをもとに RAG を構築した場合、 RAG を定期的に更新しないと、新たに投入された社内データは参照対象になりません。そのため、 RAG を使う場合は最新データを定期的に更新する仕掛け作りが重要なポイントの一つになります。
このように、 RAG と LLM を組み合わせて使うことで、リアルタイムの最新情報を LLM が利用できるようになり、 AI の利便性が大きく向上します。
以下、 RAG と LLM の違いを表にまとめます。
|
RAG |
LLM |
|
|
目的 |
モデルの性能強化(正確性・信頼性の向上) |
膨大な事前学習データをもとにしたテキスト生成 |
|
特徴 |
自然言語処理と機械学習に加えて外部データを利用 |
モデルが保有する知識の範囲内で回答を生成 |
|
生成 or 検索 |
生成・検索 |
生成 |
|
主な技術 |
自然言語処理、生成モデルと検索エンジン技術の組み合わせ |
トランスフォーマーベースの大規模モデル、トレーニングされた大量のパラメータ |
|
出力内容 |
検索結果をもとにした新しいテキスト |
大規模な事前学習データをもとにした新しいテキスト |
|
検索の焦点 |
情報生成に必要な関連データの取得 |
クエリ内容に沿った新たなテキストの生成 |
|
適用シーン |
対話型 AI 、カスタマーサポートの自動応答など |
高度な対話生成、テキスト生成、創作など |
|
情報源 |
外部の知識ベースや検索エンジンから取得したデータ |
モデルが事前に学習したデータ |
|
精度の向上手段 |
検索アルゴリズムや大規模な知識ベースを組み合わせることで精度が向上 |
モデルの再学習やファインチューニングにより精度が向上 |
|
AI モデルの役割 |
質問に対してコンテキストに合った応答を検索・生成 |
ユーザーの意図に沿ったテキスト情報を生成 |
|
情報のリアルタイム性 |
外部データの活用により、リアルタイムな情報を利用できる |
学習データに依存するため、リアルタイム性は低い |
LLM に関心のある方は以下の記事が参考になります。
関連記事:LLM (大規模言語モデル)の仕組みとは?生成 AI との違いや活用事例などを一挙に紹介!
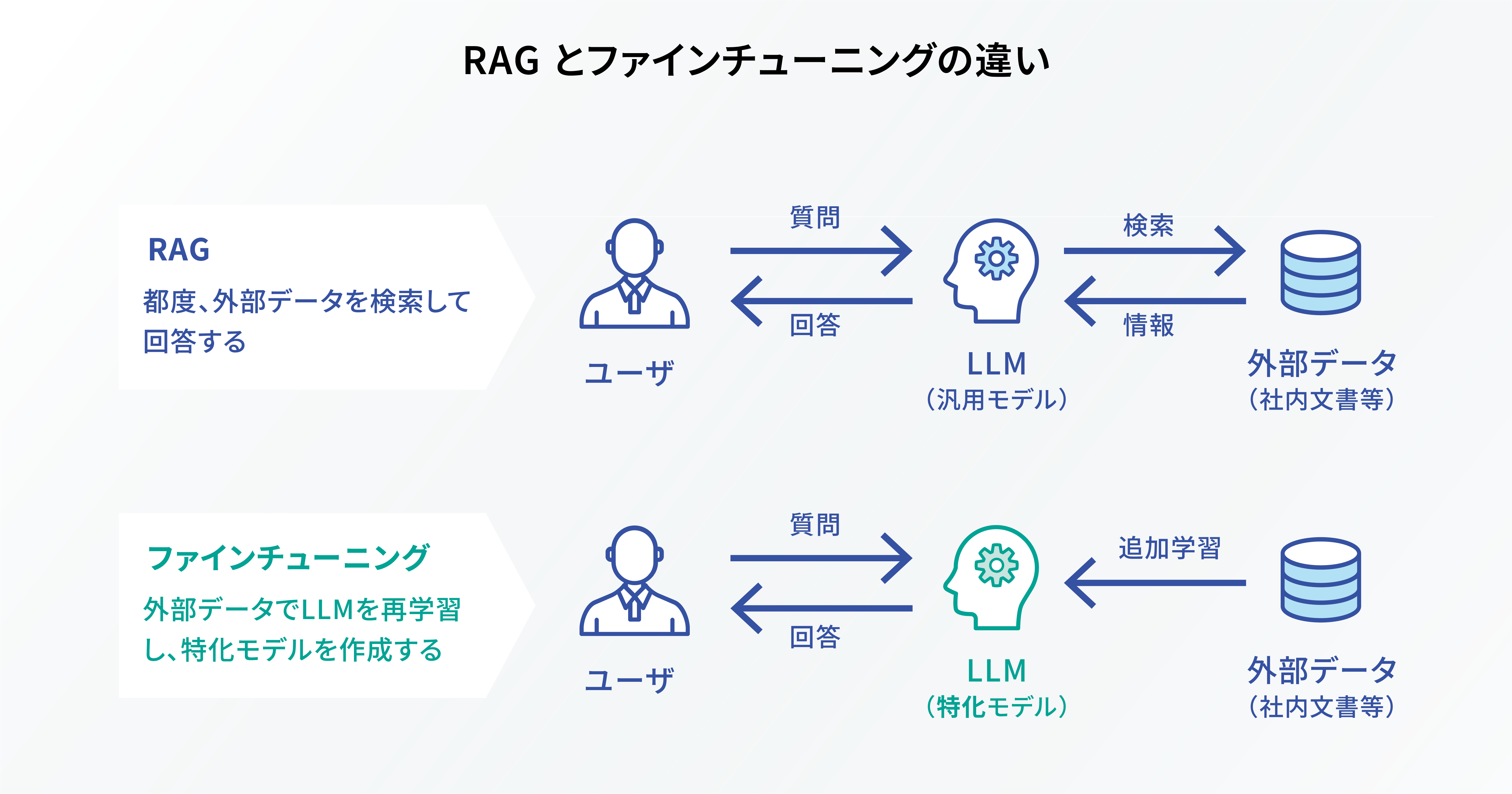
ファインチューニングとは、事前に訓練された大規模な AI モデルを特定タスクなどに最適化するために再訓練することです。例えば、医療に特化した AI モデルを作りたい場合、既存の LLM に医療関連のデータを追加で学習させることで、より専門性の高い回答を生成できるようになります。
このように、ファインチューニングは特定分野に特化した情報を事前に学習するため、 AI がリアルタイムに情報検索し、新たな回答を出力する RAG とは仕組みそのものが異なります。最新データが必要となる場合は RAG を活用し、特定ドメインの知識や言語スタイルの適応など、専門性が求められる場面ではファインチューニングを活用するなど、シーンによって使い分けるとよいでしょう。
以下、 RAG とファインチューニングの違いを表にまとめます。
|
RAG |
ファインチューニング |
|
|
目的 |
モデルの性能強化(正確性・信頼性の向上) |
モデルの性能強化(特定用途への対応) |
|
特徴 |
自然言語処理と機械学習に加えて外部データを利用 |
既存の LLM に再学習を行うことで最適化 |
|
生成 or 検索 |
生成・検索 |
生成 |
|
主な技術 |
自然言語処理、生成モデルと検索エンジン技術の組み合わせ |
トランスフォーマーモデルのパラメータ調整、特定タスクに対するデータセットを用いた再学習 |
|
出力内容 |
検索結果をもとにした新しいテキスト |
特定のタスクやドメインに最適化された新しいテキスト |
|
検索の焦点 |
情報生成に必要な関連データの取得 |
検索機能なし(生成に特化) |
|
適用シーン |
対話型 AI 、カスタマーサポートの自動応答など |
特定業界向けのカスタマーサポート、専門文書の作成など |
|
情報源 |
外部の知識ベースや検索エンジンから取得したデータ |
特定タスクに合わせて用意した専門的な再学習データ |
|
精度の向上手段 |
検索アルゴリズムや大規模な知識ベースを組み合わせることで精度が向上 |
ドメインに特化したデータを用いてモデルを再学習することで精度が向上 |
|
AI モデルの役割 |
質問に対してコンテキストに合った応答を検索・生成 |
特定のタスクに対して適切なテキストを生成 |
|
情報のリアルタイム性 |
外部データの活用により、リアルタイムな情報を利用できる |
学習データに依存するため、リアルタイム性は低い |
ファインチューニングの仕組みなどに関心のある方は以下の記事が参考になります。
関連記事:ファインチューニングとは? AI モデルをカスタマイズするための方法を徹底解説!
RAG 活用のメリット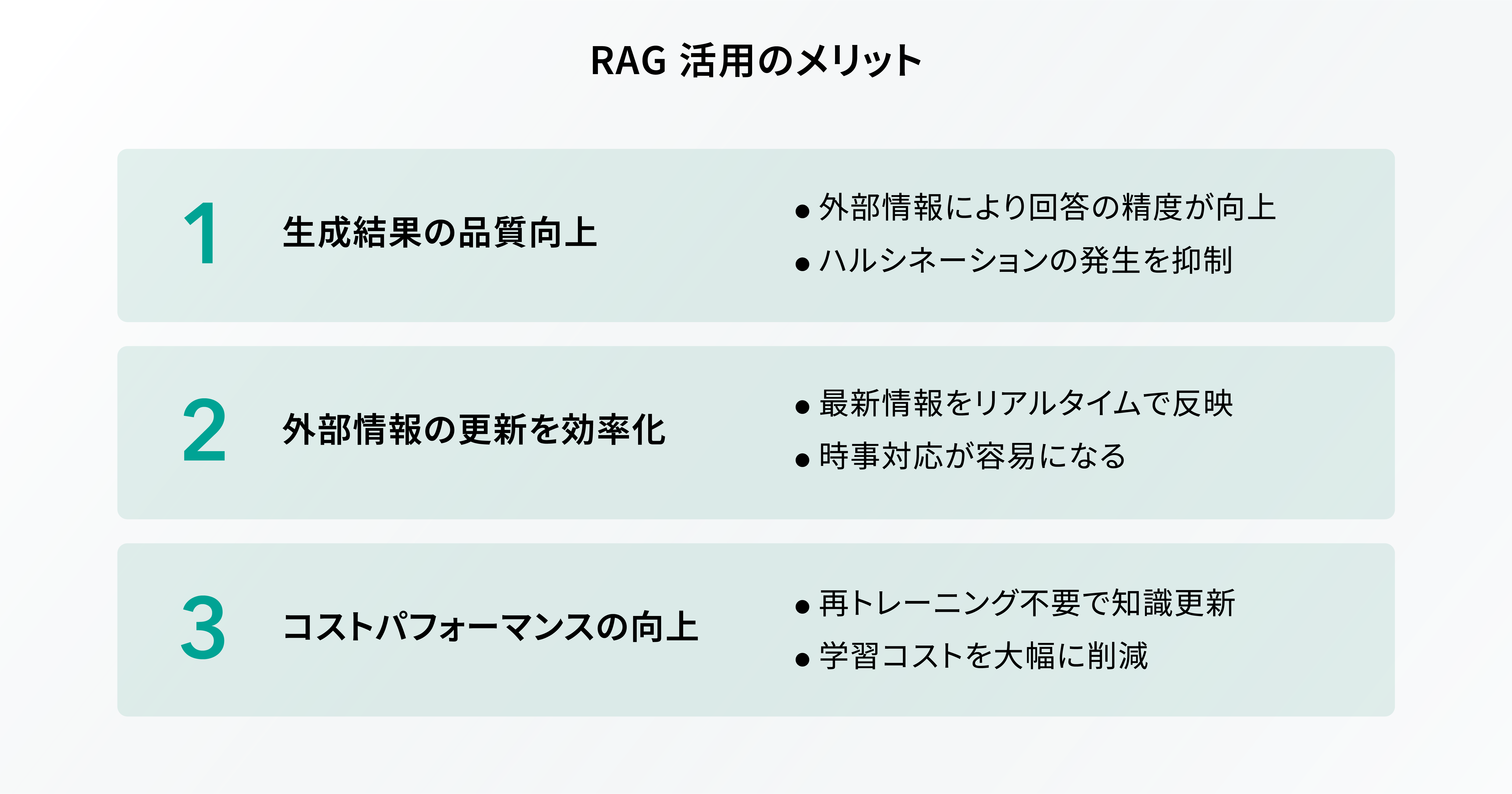
企業が RAG を活用することで、どのような恩恵を受けられるのでしょうか?本章では、 RAG の代表的なメリットを 3 つご紹介します。
生成結果の品質向上に繋がる
RAG の大きなメリットの一つとして、生成結果の品質向上に繋がる点が挙げられます。従来の LLM では、データセットに存在しない情報や曖昧な質問に対して、誤った情報を生成する AI ハルシネーションという現象が発生するリスクがありました。
一方、 RAG は関連情報を外部ソースから検索することで、正確かつ信頼性の高いデータに基づいた回答を生成できます。このプロセスにより、ユーザーに提供される情報の精度は大幅に向上し、 AI ハルシネーションの発生リスクを最小限に抑えられます。
ただし、 RAG を利用する場合には外部データの信憑性に気を配る必要があります。記事後半で詳しく触れていますので、詳細はこちらをご参照ください。
AI ハルシネーションについては以下の記事で詳しく解説しています。
AI 活用の落とし穴? AI ハルシネーションの原因・対策をわかりやすく解説!
外部情報の更新を効率化できる
外部情報の更新を効率化できる点も RAG の代表的なメリットの一つです。従来の LLM は学習時点のデータに依存するため、新しい情報や最新の知識を反映させるのが難しいという課題がありました。
その点、 RAG は外部の情報源からデータをリアルタイムに取得できるため、常に最新の情報を提供することが可能になります。これにより、日々変化する社会問題や時事ニュースなどにおいても、ユーザーにとって価値のある最新情報を迅速に提供することが可能になります。
ただし、 RAG の精度は情報源の更新頻度や検索システムの性能などに依存します。そのため、必ずしも正確かつ最新の情報を取得できるわけではないので、この点には注意しておきましょう。
AI のコストパフォーマンスを高められる
RAG は AI のコストパフォーマンス向上にも役立ちます。本来、 LLM のトレーニング・更新には膨大な時間とリソースが求められますが、 RAG を活用することでその負担を軽減できます。当然ながら、 RAG の場合も外部データを検索して処理するための計算コストが発生しますが、 LLM の大規模な再トレーニングと比較すれば、コストを大幅に抑えることが可能です。
なぜなら、 RAG はすべての情報をモデル内で生成するのではなく、外部の信頼できる情報源からデータを取得するため、トレーニングデータの管理・更新の頻度を減らせるからです。また、最新の情報を取り入れることで、モデルの再トレーニングが不要になるため、結果的にコストの削減にも繋がります。ただし、モデルの基本的な能力を維持・向上させるための定期的な更新が求められる場合があるので、この点は覚えておきましょう。
RAG の主要コンポーネント
本章では、 RAG の主要なコンポーネントについて見ていきましょう。
ここでは、
- プロセスフロー
- 技術コンポーネント
- データ管理
の 3 つのカテゴリに分けて、 RAG にどのようなコンポーネントが含まれているのか、具体的な内容をご説明します。
プロセスフロー
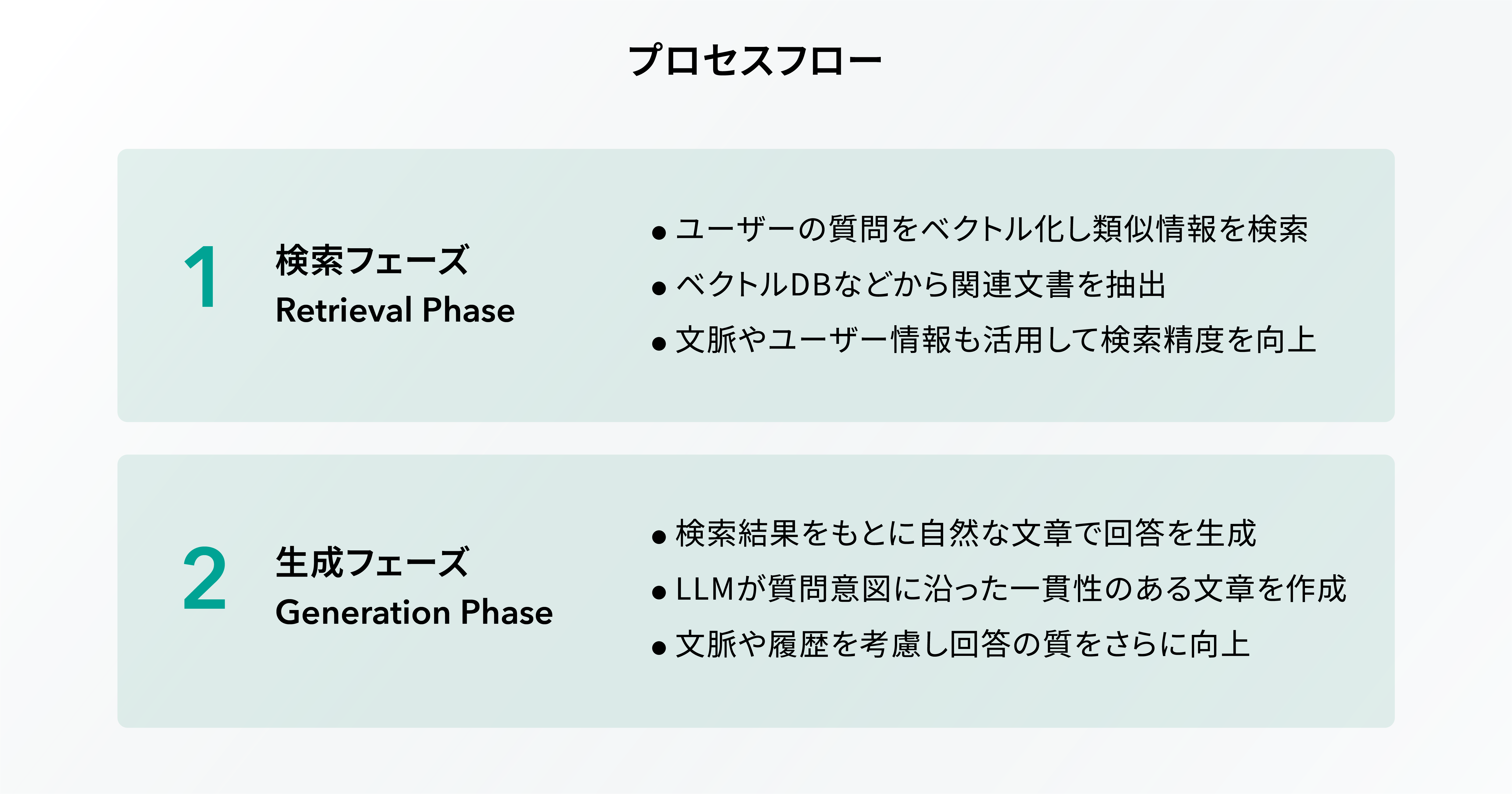
Retrieval Phase (検索フェーズ)
RAG の第一段階は Retrieval Phase (検索フェーズ)であり、このフェーズではユーザーの入力内容に基づいて関連する情報を探し出します。具体的には、大規模データベースやインターネットなどの情報源から、質問に対する回答に役立つコンテンツを検索します。
技術的には、質問の意味を深く理解するために、エンベディング技術を用いて質問を数値ベクトルに変換し、ベクトルデータベース上で類似のベクトルを持つ文書を検索します。 この際、過去の会話履歴やユーザーのプロファイルなどのコンテキスト情報を考慮することで、よりパーソナライズされた検索結果を得ることができます。
このように、 Retrieval Phase (検索フェーズ)では、質問の意図を正確に理解し、最も関連性の高い情報を抽出することが求められます。これにより、生成される回答の精度が大きく左右されるため、とても重要なフェーズであると言えるでしょう。
Generation Phase (生成フェーズ)
RAGの第二段階はGeneration Phase(生成フェーズ)であり、このフェーズでは、Retrieval Phase(検索フェーズ)で収集された情報を基に、具体的な回答が生成されます。ここでは、ユーザーの質問に対して最も関連性の高い情報を元にして、AIが自然言語で分かりやすい回答を作り出します。
技術的には、LLM(大規模言語モデル)が活躍し、検索された情報を自然な文章として整形します。単なる情報の羅列ではなく、ユーザーの意図や質問に即した、整合性のある一貫した回答を生成することが求められます。また、文脈やユーザーの過去の質問履歴を考慮することで、より精度の高い回答が提供されます。
このように、Generation Phase(生成フェーズ)では、単に情報を出力するのではなく、ユーザーにとって最も有用で意味のある形に変換することが重要なポイントです。これにより、 RAG は高品質な回答を生成し、ユーザーのニーズに的確に応えることができます。
技術コンポーネント
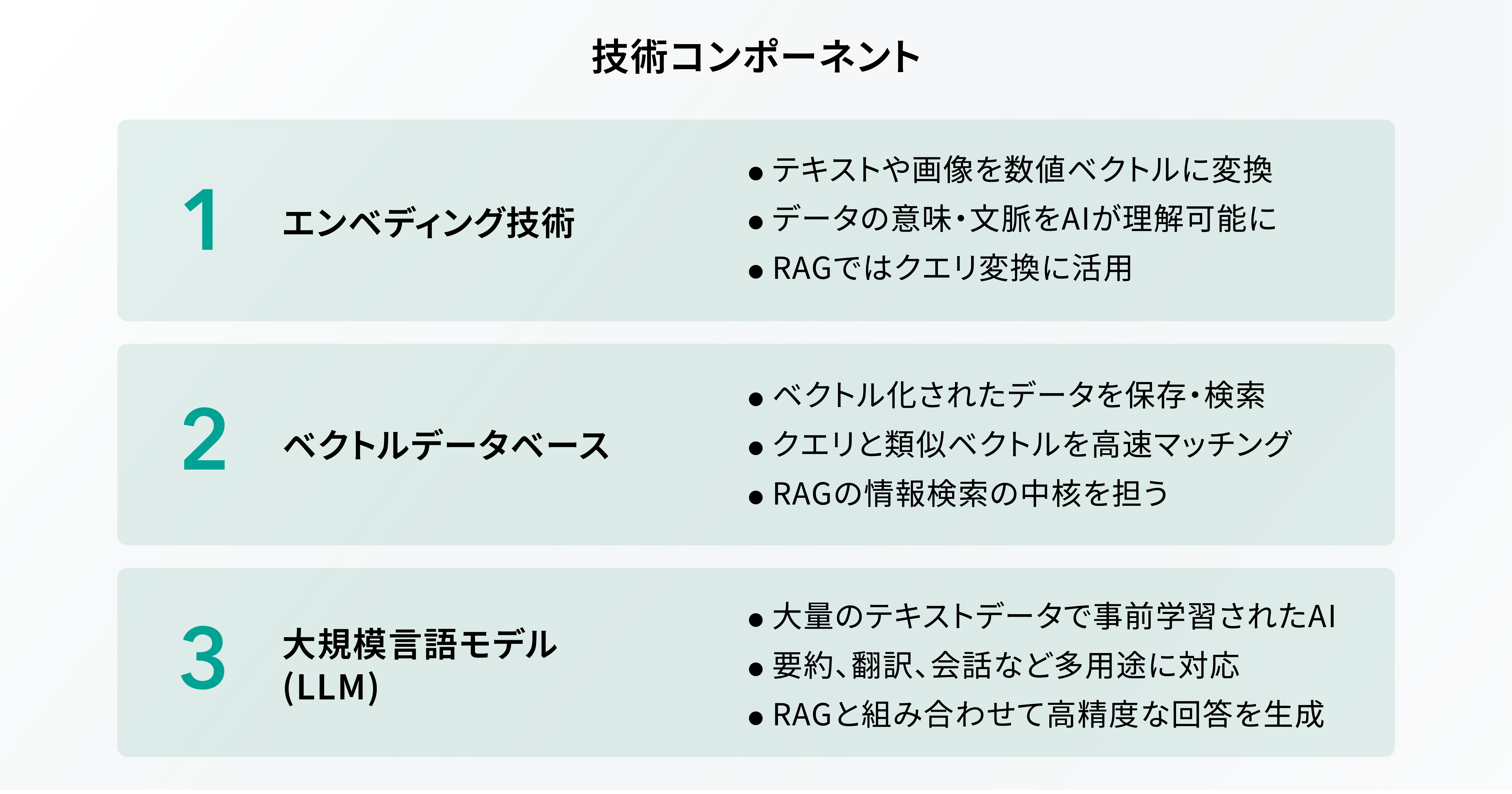
エンベディング技術
エンベディング技術とは、テキストや単語、画像などのデータを数値のベクトルに変換するための技術です。データをベクトルで表現することで、 AI がデータの意味や文脈を正しく理解できるようになります。
RAG では、ユーザーのクエリ(質問やリクエスト)を数値ベクトルに変換すると前項でご説明しましたが、このプロセスにおいてエンベディング技術が使われています。このように、ベクトルデータベースと同様、エンべディング技術も RAG にとって必要不可欠な要素の一つだと言えるでしょう。
ベクトルデータベース
ベクトルデータベースとは、データを数値ベクトル(座標のようなもの)として保存し、これらのベクトル間の類似性をもとにデータを検索するためのデータベースです。通常、テキストや画像などのデータは、その内容や意味を表す数値ベクトルに変換され、このベクトルを使って検索が行われます。
そして、ベクトルデータベースは RAG の仕組みにおいて重要な役割を担います。 RAG では、ユーザーのクエリ(質問やリクエスト)が数値ベクトルに変換され、このベクトルをもとにベクトルデータベース内のデータと類似性を比較することで、関連性の高い情報を素早く検索・取得できる仕組みとなっています。
例えば、「最新の AI 技術の動向を教えてほしい」と AI に質問した場合、 RAG はこの質問をベクトルデータに変換し、そのベクトルをもとにベクトルデータベース内に存在する AI 関連の最新記事や論文を検索します。そして、見つかった情報をもとに AI が具体的かつ信頼性の高い回答を生成します。
このように、ベクトルデータベースは RAG の仕組みを語るうえで欠かせない存在であることを覚えておきましょう。
関連記事;ベクトル検索とは?類似性検索との違いやメリット、ユースケースまで徹底解説!
大規模言語モデル( LLM )
LLM は「 Large language Models 」の略であり、日本語では「大規模言語モデル」と呼ばれています。大規模言語モデルという名前の通り、 LLM は非常に大規模なデータをもとに学習を行います。
具体的な学習データの例としては、 Web 上のコーパス(自然言語の文章・使い方などを広く収集し、コンピューターで検索できるように整理されたデータベース)や書籍、ニュース記事、会話ログなどが挙げられます。
昨今、 LLM の活用シーンは多岐にわたり、
- 情報検索の精度向上
- テキストの自動要約
- 会話エージェントの開発
- 翻訳の支援
など、あらゆる場面で LLM の活用が進んでいます。
そして、 LLM と RAG を組み合わせて使うことで、大規模データで学習したモデルに対して、リアルタイム性の高い最新情報を付加できるようになります。このように、 RAG を有効活用するうえでは、 LLM による事前学習が重要な要素の一つだと言えます。
関連記事:LLM (大規模言語モデル)の仕組みとは?生成 AI との違いや活用事例などを一挙に紹介!
データ管理
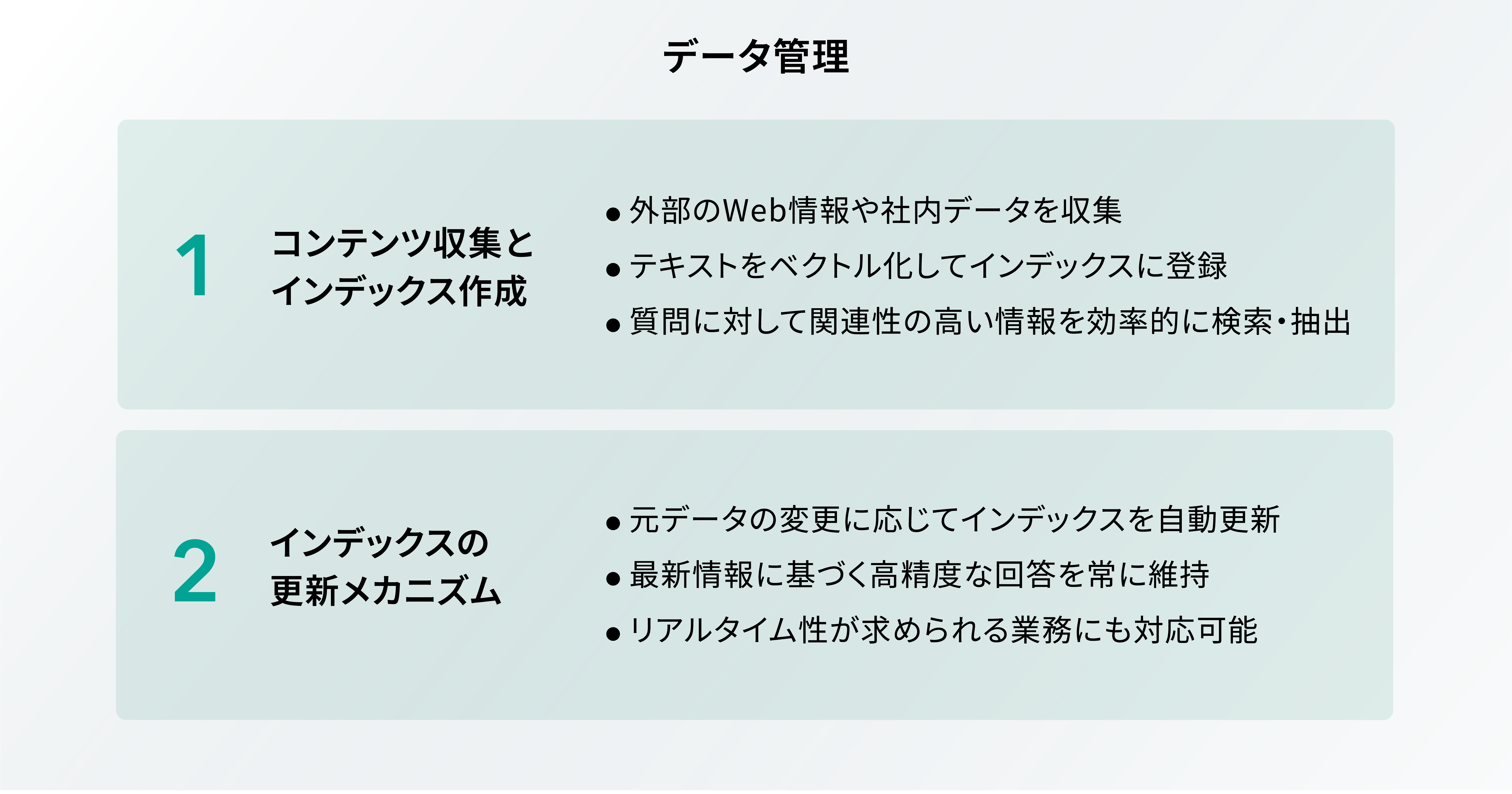
コンテンツ収集・インデックス作成
RAG におけるデータ管理の基盤となるのが、コンテンツ収集とインデックス作成です。このプロセスでは、外部のデータソースから情報を取得し、その情報を効率的に検索できるように整理します。
具体的には、 Web 上の膨大なデータや企業の内部データベースなどからテキスト情報を収集し、それらをベクトル形式に変換してインデックスに格納します。 RAG では、このインデックスが質問に対して関連性の高い情報を素早く検索できるように設計されているため、結果として精度の高いコンテンツ生成に繋がります。
更新メカニズム
通常の検索エンジンやデータベースと同様に、 RAG は常に新しい情報を取り込み、インデックスをアップデートすることが求められます。 RAG の更新メカニズムでは、外部のデータソースが更新される度にインデックスも適宜再構築されるため、最新の情報に基づいた応答が生成できます。これにより、ビジネスの現場やユーザーサポートなど、リアルタイム性が重要なシーンにおいても高い効果を発揮できる点が RAG の大きな特徴となっています。
RAGの精度を高めるには?
本章では、 RAG の精度を高めるための方法について解説します。検索方法とベクトル化の 2 つに分けて、具体的な内容を見ていきましょう。
検索方法
RAG は必要情報を検索して回答を生成する仕組みであるため、状況に応じて最適な検索方法を選択することで精度の向上に繋がります。
以下、代表的な RAG の検索方法の一覧です。
- キーワード検索:キーワードが含まれる情報を検索する
- ベクトル検索:検索クエリ・検索対象文書をベクトルに変換し、両者の類似度をもとに情報を検索する
- ハイブリッド検索:キーワード検索とベクトル検索を組み合わせて情報を検索する
- セマンティック検索:検索クエリの意味や意図を理解し、それらをもとに情報を検索する
また、 Microsoft は検索方法ごとの精度の違い(セマンティック検索は除く)を数値化し、自社サイト上で公開しています。下表で数字が大きいほど、精度が高いことを意味しています。
|
クエリタイプ |
キーワード検索 |
ベクトル検索 |
ハイブリッド検索 |
|
抽象的なクエリ |
39.0 |
45.8 |
46.3 |
|
特定の答えがあるクエリ |
37.8 |
49.0 |
49.1 |
|
検索対象ドキュメントの部分文字列の検索 |
51.1 |
41.5 |
51.0 |
|
Web検索のようなクエリ |
41.8 |
46.3 |
50.0 |
|
特定単語のみのクエリ |
79.2 |
11.7 |
61.0 |
|
質問とは異なる単語・フレーズを回答に求める検索 |
23.0 |
36.1 |
35.9 |
|
スペルミスのあるクエリ |
28.8 |
39.1 |
40.6 |
|
20 トークン以上のクエリ |
42.7 |
41.6 |
48.1 |
|
5 ~ 20 トークンのクエリ |
38.1 |
44.7 |
46.7 |
|
5 トークン未満のクエリ |
53.1 |
38.8 |
53.0 |
※参考: Microsoft 公式サイト:Azure AI Search: ハイブリッド検索とランキング機能により、ベクター検索を上回るパフォーマンスを実現
このように、 RAG は使用する検索方法によって精度が変わります。自社の状況に合わせて、最適なものを選択するように意識してください。
ベクトル化
RAG の精度を高めるためには、検索方法とあわせてベクトル化の工夫を行うことも重要なポイントになります。
テキストデータのベクトル化で有名な手法として、 Google が 2013 年に公開した Word2Vec が挙げられます。 Word2Vec は単語をベクトル化するための仕組みでしたが、 2014 年に考案された Doc2Vec では機能が改良され、文書全体をベクトル化することが可能になりました。
そして、現在は上記以外にも様々なベクトル化ツールが開発されています。ただし、ツールごとに処理速度やコストが異なるため、複数のツールを比較・検討し、自社に最適なものを選択するように意識しましょう。
さらに、最近はデータベース自体がベクトルデータを保持・活用できるように進化しており、一つのデータベースでベクトルデータを含めたすべての情報を管理することも可能です。これにより、自社の工数削減や生産性向上に直結するため、ベクトル化ツールとあわせて、使用するデータベースも慎重に検討することをおすすめします。
RAG の活用シーン
ここまで、 RAG について詳しく解説してきましたが、具体的にどのような場面で使われているのでしょうか?本章では、 RAG の具体的な活用シーンを 3 つご紹介します。
専門的な文書の作成
専門的な文書を作成したい場合、 RAG が心強い武器になります。例えば、医療や法律などの分野では、正確かつ最新の情報が求められます。
そこで、 RAG を活用すれば、上記のような専門知識が必要なテーマについても、信頼性の高い外部ソースから適切なデータを検索し、それらに基づいた正確な文章を生成できます。これにより、専門家が時間をかけて調査を行う必要はなくなり、高品質な文書を迅速に作成することが可能になります。
なお、情報キュレーションサービスなどを提供している Gunosy 社では、業務支援特化の生成 AI サービスである「ウデキキ」の一部機能に RAG を活用しています。例えば、ユーザーが PDF ファイルをアップロードすると、ウデキキがテキスト内容を要約して重要なポイントを抽出してくれるため、時間・労力の節約に繋がります。
問い合わせ対応の効率化
RAG はカスタマーサポートや問い合わせ対応にも大きな効果を発揮します。通常、顧客からの質問に対して適切な回答を返すためには、広範な知識と迅速な対応が求められます。
その点、 RAG を利用することで、回答に必要な情報を素早く取得し、それらに基づいた回答を自動生成できるため、問い合わせ対応にかかる時間を大幅に短縮できます。さらに、 AI ハルシネーションのリスクも低減されるため、顧客に対して正確かつ信頼性の高い回答を提供でき、結果として顧客満足度の向上に繋がります。
なお、経費精算などの SaaS パッケージを提供している Layer X 社では、顧客向けにセキュリティチェックシート(顧客が Layer X のサービスを利用する際にセキュリティ面の問題がないかを確認するための質問集)を用意していますが、顧客からの返答に対する一次回答を RAG で生成し、業務負荷の軽減を実現しています。
社内向けの FAQ サイト
RAG は社内向けの FAQ サイトにも有効的に活用できます。一般的な企業においては、日常的に多くの質問が発生しており、社員が効率的に業務を遂行するためには、迅速かつ正確な情報提供が求められます。
そこで、 RAG を活用した FAQ サイトを構築すれば、外部および内部のデータソースから関連情報を自動的に収集し、最新の FAQ を生成することが可能になります。これにより、社員は必要な情報に迅速にアクセスでき、業務効率の向上やナレッジ共有の促進に繋がるため、組織全体のパフォーマンスが飛躍的に向上することでしょう。
RAG を LLM に実装する方法
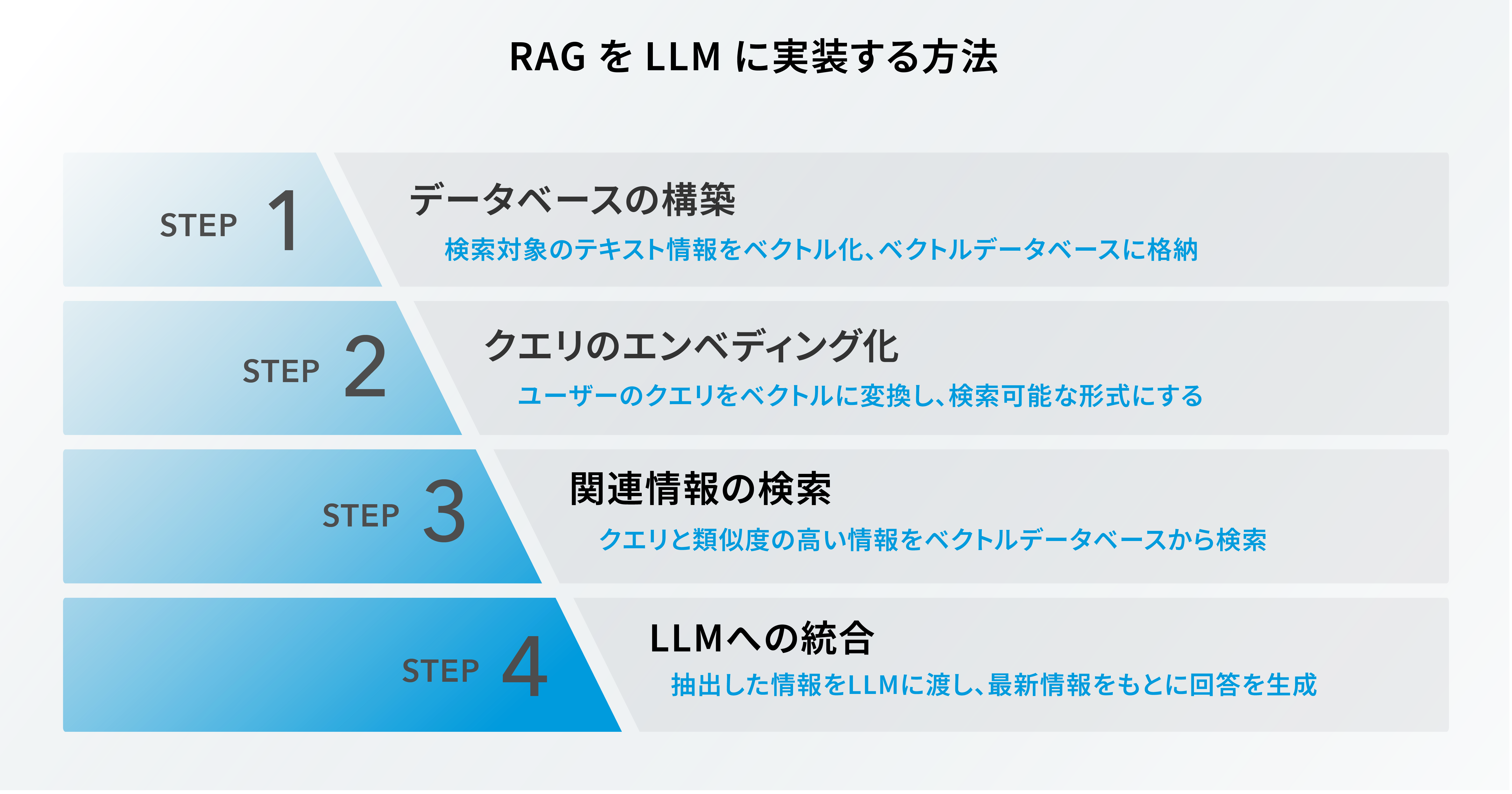
本章では、 RAG を LLM に実装する方法について解説します。どのような手順で RAG を実装するのか、具体的なステップを理解しておきましょう。
Step.1:データベースの構築
まずは、外部から取得する情報を格納するためのデータベースを用意しますが、ここではベクトルデータベースを使用するのが一般的です。ベクトルデータベースで大量のテキストデータを数値ベクトルに変換して格納し、 RAG を利用するための下準備を行います。このベクトルデータベースには、関連する文書や記事、その他のテキストデータなど、様々な情報が保管されます。
Step.2:クエリのエンベディング化
次に、ユーザーからのクエリ(質問やリクエスト)をエンベディング技術を使ってベクトルに変換します。前述した通り、エンベディングとはテキストや単語、画像などのデータを数値のベクトルに変換するための技術です。これにより、クエリをベクトルデータベース内のデータと比較できるようになります。
Step.3:関連情報の検索
クエリをエンベディング化した後は、それらのクエリを使用してベクトルデータベース内の関連情報を検索します。このステップでは、クエリとデータベース内の情報との類似性が計算され、最も関連性の高い情報が選択されます。そして、この情報は LLM が回答を生成する際に使用されるため、とても重要なステップになります。
Step.4:LLMへの統合
最後に、関連情報を LLM へ統合します。これにより、 RAG で取得された情報が LLM に備わり、事前学習データだけではなく、最新の情報をもとに AI が具体的かつ高精度な回答を生成できるようになります。生成 AI の精度向上を実現するためには、 RAG の活用がポイントの一つであると言えるでしょう。
RAG を利用する際の注意点
RAG はとても便利である一方で、実際に使う場合には意識すべき点がいくつか存在します。最後に、 RAG を利用する際の注意点について解説します。
外部情報の信憑性をチェックする
RAG は外部情報を取り込んでコンテンツを生成する仕組みであるため、情報の信憑性を確認することが重要なポイントです。仮に、信頼性の低い情報ソースを使用した場合、誤った情報がコンテンツに含まれてしまうリスクがあります。そのため、情報源の出典や最新性などを事前にチェックし、信頼できるソースを使用して信憑性を確保するように心がけましょう。
機密情報・個人情報の取り扱いに注意する
RAG を使用する際には、機密情報や個人情報の取り扱いについて注意を払う必要があります。万が一、これらの機密データが外部に漏洩した場合、取り返しのつかない事態に発展するリスクがあるため、コンテンツ内に機密情報や個人情報が含まれていないかを入念に確認することが大切です。なお、必要に応じて、データ匿名化やフィルタリングなどを行うことで、より安全な環境で AI を運用できるようになります。
独自性の高いコンテンツ生成には不向きな場合がある
RAG は既存の情報をもとにコンテンツを生成する仕組みであり、独自性の高いコンテンツを作りたい場合には不向きなケースも存在します。例えば、独創的なアイデアなどが求められるケースでは、人間によるクリエイティブな視点の介入が必要不可欠です。そのため、独自性を重視する際には、 RAG を補完的なツールとして活用し、人間の視点や知識を取り入れることで、より質の高いアウトプットを得られるようになります。
まとめ
本記事では、 RAG の仕組みやメリット、注意点など、あらゆる観点から一挙にご紹介しました。
企業が RAG を活用することで、生成結果の品質向上や AI のコストパフォーマンス向上など、様々なメリットを享受できます。この記事を読み返して、具体的な活用シーンや利用時の注意点など、重要なポイントを理解しておきましょう。
G-genは、Google Cloud のプレミアパートナーとして Google Cloud / Google Workspace の請求代行、システム構築から運用、生成 AI の導入に至るまで、企業のより良いクラウド活用に向けて伴走支援いたします。
サービスを見る
サービス資料をダウンロードする
無料で相談する
本記事を参考にして、 RAG の活用を検討してみてはいかがでしょうか?
関連記事

Contactお問い合わせ

Google Cloud / Google Workspace導入に関するお問い合わせ