- ホーム
- お役立ち
- Google Service
- 「Kaggleで勝つデータ分析の技術」著者が語るGCPを活用してKaggleで勝つためのポイント
「Kaggleで勝つデータ分析の技術」著者が語るGCPを活用してKaggleで勝つためのポイント
- AI
- Google Cloud Day
- kaggle

Googleが開催するイベントのGoogle Cloud Dayでは、Google Cloudの最新ソリューションを学ぶことができます。
2020年はCOVID-19の影響もあり、リモートでの開催となりました。
この記事では数あるセッションの中から、Kaggleに関連するセッションを取り上げ、機械学習のモデリング技術を競い合うKagglerと呼ばれる人の中の1人である、「Kaggleで勝つデータ分析の技術」著者「平松 雄司」氏がどのように GCP を活用するかについてご紹介します。
目次
この記事でご紹介するセッション
この記事ではGoogle Cloud Dayで公開された下記のセッションを参考に、GCPにおけるKaggleの活用方法についてご紹介します。
Kaggleで勝つGCPの活用方法
取り上げる主な Google Cloud 製品 / サービスは以下になります。
- AI Platform
- Compute Engine
- BigQuery
- AutoML
Kaggleとは

世界中のデータサイエンティスト・機械学習エンジニア向けのコミュニティで、様々なデータデータ分析コンペティションが開催されています。
コンペの評価指標に基づいて優劣を争います。メダルに応じた称号システムや賞金があり、Kaggleでの成績を人材採用の参考にする企業も増えてきています。
そういった流れから、Kaggleの話題をメディアで目にする機会も増えてきています。
称号システム(Kaggle Progression System)
Kaggleには称号システムがあり5つのTierに分かれています。メダルの色や数によって昇格する仕組みとなっています。
- Grandmaster
- Master
- Expert
- Contributor
- Novice
このうちKaggle Masterはデータサイエンティストの目標とされることが多いです。
Cloud AI NotebooksでKaggleワークフローをパワーアップ
Notebooksと使用時の課題
NotebooksはKaggleに用意されているブラウザ上の実行環境で、学習を行い予測を提出することもできます。
Notebooksは無料で利用できますが、以下のような課題もあります。
- Computingリソースは自由に構成できない
- 計算量が多いタスクは学習に時間がかかる
- アイドル時間が長い時のセッション切れ
AI Platform Notebooks(CAIP Notebooks)とは
AI Platform NotebooksはJupyterLab統合開発環境を提供するマネージドサービスです。以下のような特徴があります。
- 最新の機械学習フレームワークが設定済みの環境をワンクリックでデプロイ完了
- 簡単にスケールアップ/ダウンが可能
- NotebooksからGCPリソースにアクセス可能
- モデルの構築・学習・デプロイまで機械学習のライフサイクルをサポート
AI Platform Notebooksの仕組み

- Notebooksインスタンスはプロジェクト内のGCEとして存在しているので、ハードウェアの選択が可能で必要に応じてスケールアップやスケールダウンが可能です。
- Notebooks内からシンプルな記述でGCSやBigQueryにアクセスが可能です。
- 好きなフレームワークを選択するだけでインスタンスが作成・起動できます。
- 一度作成したインスタンスでも、CPUコア数やメモリを変更可能です。
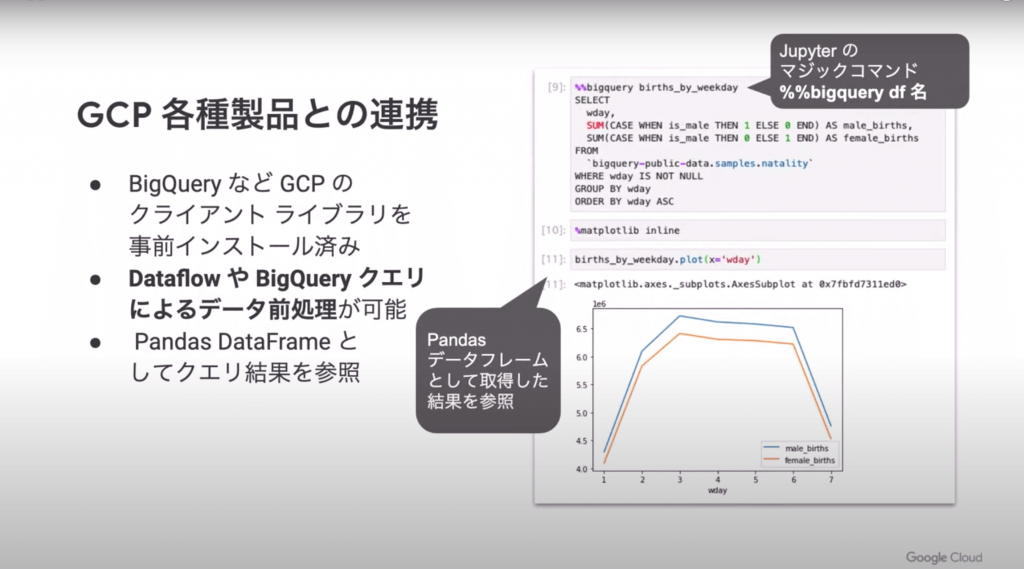
BigQueryとの連携イメージ。BigQueryの結果をPandasデータフレームとして参照しています。
gcloudコマンドでもインスタンスを起動可能で、GPUインスタンスやTPUインスタンス、プリエンティブルインスタンスも作成可能。
ただし、プリエンティブルインスタンスは安価だが、Google側から予告なく削除されることがあるので注意が必要です。
実演
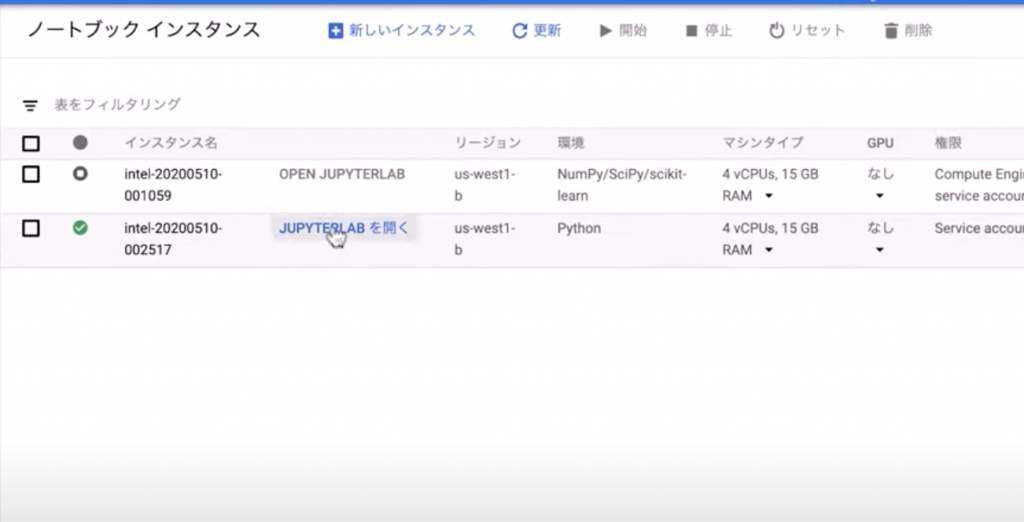
セッションでは実際にインスタンスを作成し、環境に接続する様子がデモンストレーションされました。
インスタンス作成後、画像のように「JUPYTERLABを開く」をクリックするだけで簡単にNotebooks環境に接続できます。
プラットフォームの比較
Kaggle NotebooksやColaboratoryは無料で利用できるのがメリットです。一方、Cloud AI Platform Notebooksはマシンタイプを自由に構成でき、GPUタイプを4種類選べるのがポイントです。利用時間の制限がないなど、エンタープライズ向けの環境が整っており、本格派の環境といえます。
| Cloud AI Platform Notebooks | Kaggle | Colaboratory | |
|---|---|---|---|
| ハードウェア構成 | 自由に構成 | CPU(4core, 16GB RAM), GPU(13GB RAM) | 2core, 13GB RAM |
| GPU Spec | Nvidia K80, T4, P4, P100から選択 | Tesla P100 | 選択不可※GPU/TPUの選択は可能 |
| 利用時間制限 | なし | Sumit時の時間制限およびGPU使用時時間制約 | 連続12時間 |
| 対応言語 | Python, R | Python, R | Python |
| SSHアクセス | ○ | × | △ |
| セキュリティ | △(IPによる制限) | × | △ |
| 無料コンピューティング | × | ○ | ○ |
KaggleにおけるGCP活用例

GCPをKaggleで活用した事例を二つ紹介します。
01 Table Data - Home Credit Default Risk
このコンペはHome Credit Groupが開催したコンペで、個人のクレジットの情報や過去の申請履歴から、債務不履行になる確率を予測するタスクです。テストデータに対する予測結果をCSVファイルで提出する形式のコンペでした。
コンペの概要
- 消費者金融Home Credit Groupが開催
- 貸し倒れの予測をするタスク
- 参加人数が非常に多く、7200チーム。Kaggle史上2番目に大規模だったコンペ
- 作成する予測モデルに制約がないコンペ
データについて
- マルチテーブルデータ
- 2.5GB
- 過去の履歴や外部機関のデータを現在のデータに集約する必要があった
- 集約作業を通して作成する特徴量の数は膨大
- 評価指標はAUC
- 訓練データと評価データ間で共変量シフトがあった
- Leader Boardと手元のCross Validationの相関が取りにくかった
登壇者のソリューション
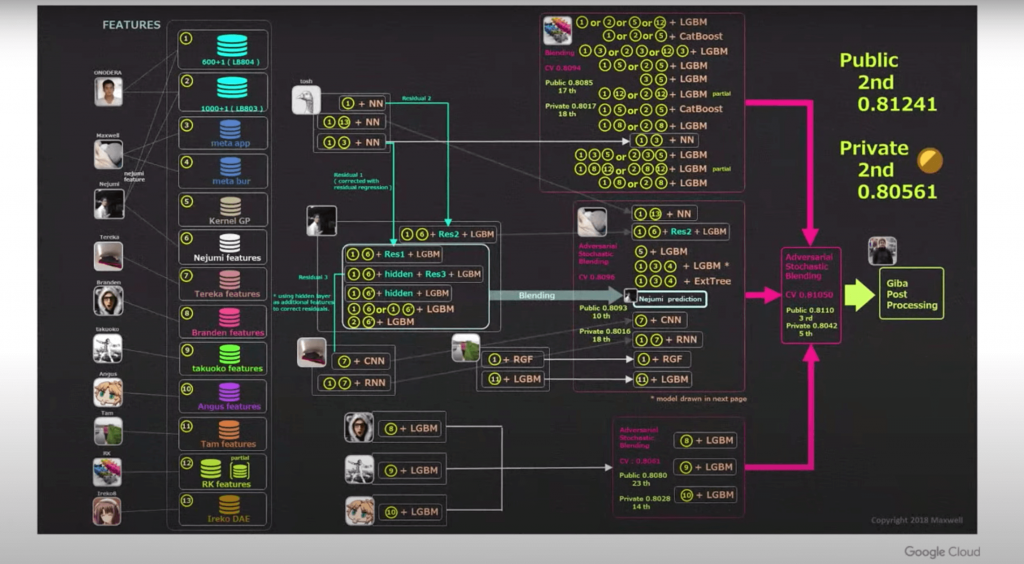
- 全参加チーム中2位
- 50個以上の単体モデルを含む巨大モデル
- モデルに制約がなかったので、チームがどんどん巨大化
- 特徴量を作成するためのコストも含めて膨大な計算コスト
なぜたくさんのモデルを作るのか
No Free Lunch Theorem
「全てのデータやタスクにおいて、常に他よりも優れているモデルは存在しない」という定理です。
新しいコンペに参加する都度、どのようなモデルが良いかを毎回探ることになります。
GBDTやニューラルネットワークなどがある。可能性がありそうなモデルをしらみつぶしに試すだけのスケーラブルな計算環境が必要になります。
最終的には精度が高いモデルをアンサンブルすることで、さらに良い精度に到達するケースが多々あります。
02 Image Data Bengali.AI Handwritten Grapheme Classification
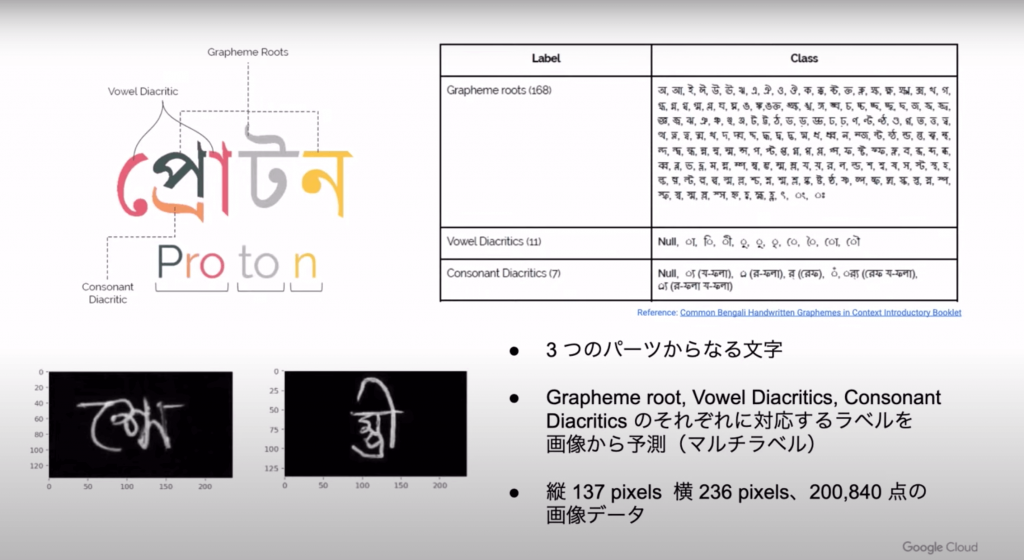
バングラディシュに拠点を置く非営利組織Bengali.AIが開催したコンペで、ベンガル文字の画像を識別するタスクです。モデルの推論時間に制限があるコンペでした。
制限
- モデルの学習には制限なし
- モデルの評価には制限あり
- 推論はKaggle Kernelと呼ばれるKaggleのサーバで実行しなければならない
- 推論時間はGPU環境で2時間以内
- 2CPUs, 13GB RAM, TeslaP100 16GB
このコンペで計算量が多くなった点
クロスバリデーションにかなり時間がかかりました。
- ハイパーパラメータの決定
- ロバストなモデル評価
- テストデータの予測におけるバリアンス低減
発表者オススメの計算環境
Kaggleでオススメの計算環境は「ローカル計算環境」と「GCE」の組み合わせとのこと。
コンペの開始初期はパイプラインの土台作り初期検討をし、勘所を掴めて上位が狙えそうになったらGCEの活用を検討するといった戦略をとっているようです。
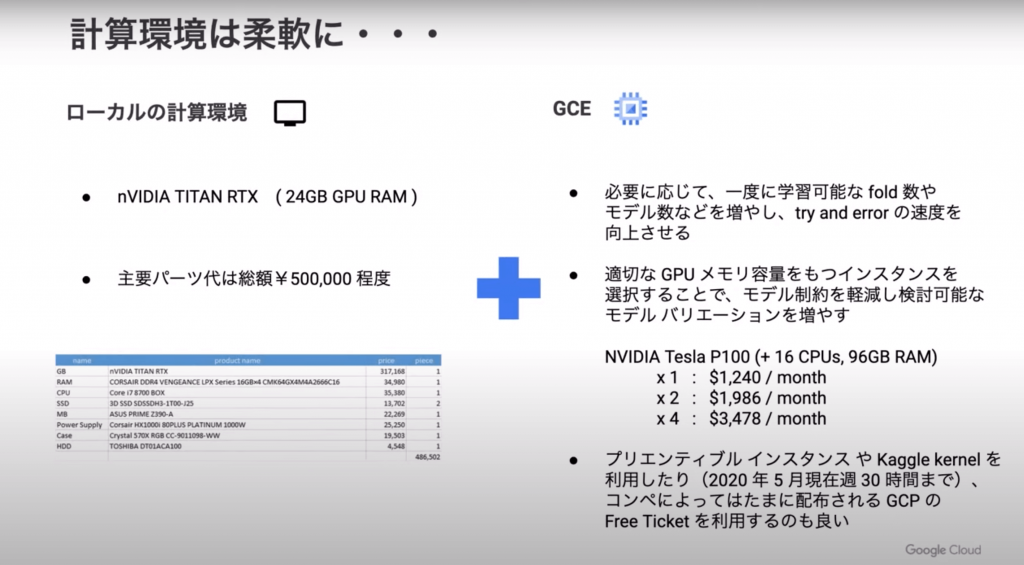
テーブルデータのコンペをやっていると計算量が大きくなるケース
以下の4つのステップは計算量が大きいです。
- 特徴量エンジニアリング・・・大量に特徴量を生成、選択に必要がある
- モデル・・・先述の通り
- パラメータチューニング・・・自動でも手動でも多くのパラメータを試す必要がある
- アンサンブル・・・Fold Averaging, Seed Averaging, Stacking
Case1. 特徴量エンジニアリング
元のデータが大きいほど計算コストは大きくなります。
「01 Talbe Data - Home Credit Default Risk」を例に挙げます。
- Home Credit Default Risk・・・2.5GB
- TalkingData AdTracking・・・10.4GB
Pandasの開発者によると取り扱うデータの5~10倍のRAM容量が推奨されています。
処理速度向上のためにさらに並列化すると、さらにメモリが必要となります。
- GCEのVMインスタンスを利用
- 最大96CPUs、624GBRAMスペック内で設定可能。
- BigQueryを利用
- CPUやRAMのスペックを気にする必要はない。
- 特徴量作成に適している
Case2. モデル
コンペ中はトライアンドエラーをなんども回すことになります。Kaggleにおいてテーブルデータに対するモデルはLightGBMがデファクトスタンダードです。
LightGBMはCPUによる並列計算の恩恵を受けやすいため、CPUのコア数がポイントとなります。
まとめ
この記事ではGoogle Cloud Dayで公開された下記のセッションを参考に、GCPにおけるKaggleの活用方法についてご紹介しました。
メダルに応じた称号システムや賞金があったり、Kaggleでの成績を人材採用の参考にする企業も増えてきていたりします。
昨今のKaggleはデータサイズが大きいコンペが多くなってきておりますので、コンペに参加する際はGCPと共に挑んでみてはいかがでしょうか?
G-genは、Google Cloud のプレミアパートナーとして Google Cloud / Google Workspace の請求代行、システム構築から運用、生成 AI の導入に至るまで、企業のより良いクラウド活用に向けて伴走支援いたします。
関連記事



Contactお問い合わせ

Google Cloud / Google Workspace導入に関するお問い合わせ