- ホーム
- お役立ち
- Google Service
- 【 Google Cloud 入門編・第11回】 Google Cloud Dataproc を使ってデータを解析しよう!
【 Google Cloud 入門編・第11回】 Google Cloud Dataproc を使ってデータを解析しよう!
- Cloud
- GCP入門編

大量のデータを解析したい、そんな時に MapReduce でおなじみの Hadoop や、オンメモリでデータを高速に処理可能な Spark を使いたくなるケースはあるのではないかと思います。しかし、 Hadoop クラスターの設定には十分な計算リソースと、相応の労力と時間がかかることもあり、実際に Hadoop を使ってデータの解析を行うには二の足を踏んでしまう、そんな方もいらっしゃるのではないでしょうか。
Google Cloud Platform (GCP) では、そんな時に気軽に利用できるサービスとして、 Google Cloud Dataproc を提供しています。 Google Cloud Dataproc は "Managed Spark & Hadoop" と銘打たれているように、データ解析の分野では広く普及している Hadoop や Spark をすぐに利用できるサービスとなっています。クラスターの立ち上げは Google Compute Engine でインスタンスを立てるくらいの気軽さで行えるため、本当にやりたい解析の前に労力を割いてクラスターを設定することは必要ありません。
この記事では、 Google Cloud Dataproc についての解説、 Google Cloud Dataproc を使用してクラスターを展開し、 Spark を利用してジョブを走らせるデモを行います。手元にデータがあるけれど、時間がなくて解析が行えない、クラスターを立ち上げるハードルが高くて Hadoop や Spark を試していない、そんな方は是非 Google Cloud Dataproc を使用してみてください。
目次
この記事の目的
- Google Cloud Dataproc について理解しよう。
- Google Cloud Dataproc を使用してクラスターを展開し Spark を利用してジョブを走らせてみよう。
Google Cloud Dataproc とは
Google Cloud Dataproc は、 GCP 上で手軽に Hadoop や Spark のクラスターを立ち上げ、データの解析を行うサービスです。最大の特徴としては、5分から30分程度でクラスターの設定を行い、利用可能な状態にできるということです。通常、 Hadoop や Spark のクラスターを設定するには、ネットワークの設定やサーバーの設定など、様々な作業が必要です。 Google Cloud Dataproc はこのクラスターの立ち上げを非常に簡単にすることで、データ解析を行うときにユーザーが本当にやりたい仕事に集中できるようにします。動作するのは Hadoop や Spark そのままですので、これまでオンプレ環境で Hadoop や Spark を使ってきた方も簡単に乗り換えることが可能です。
Hadoop とは
Apache 財団が開発する Hadoop は、Google の開発した MapReduce の論文を参考に開発された、オープンソースのデータ解析基盤です。
Google では大量のデータの解析を行うために、分散ファイルシステムである Google File System (GFS) 、解析環境である MapReduce 、分散ロックサービスの Chubby などを開発し、 Google 社内で使用していました。
2004年に論文でこれらのシステムが発表され、それぞれがオープンソースで開発されることで現在の Hadoop エコシステムが出来上がりました。
Hadoop エコシステムでは、 GFS が Hadoop File System (HDFS) に、 MapReduce が Hadoop に、 Chubby が Zookeeper に対応しています。これにより、 Google でなくとも Google と同じように、大量のデータを複数のサーバー上の分散ファイルシステムに置き、データの解析処理をスケールアウトさせることができるようになりました。
Spark とは
Spark はこの Hadoop プロジェクトのサブプロジェクトであり、データを分散ファイルシステムである HDFS に置く代わりに、分散したメモリ上に置かれた分散データセット ( RDD ) の上に置くことで、データ解析にかかる時間を飛躍的に向上させたソフトウェアです。公式サイトでは、 Hadoop に比べて100倍高速であると謳われています。もちろん、データをメモリ上に置くわけですから、 Hadoop に比べれば同一サイズのクラスター上で扱えるデータは比較的小規模なものになります。メモリに乗りきらないデータは Hadoop で処理し、メモリに乗る比較的小規模なデータは Spark で高速に処理するといった使い分けが可能でしょう。
Spark の解析ジョブは Java だけでなく、 Scala、 Python、 R で記述することが可能です。そのため、 Java に親しくないデータ解析を主な業務とする人でも解析ジョブを簡単に書くことが可能となっています。
Hadoopで使われる概念について
Hadoop を使う時は、これらで使われる概念について知っていると理解が早いと思います。ここでは、以降の部分に頻繁に登場する Hadoop で使われる概念について解説します。
まず ノード という単語ですが、これは Hadoop エコシステムが動作するように設定された一群のサーバーを構成する、一つ一つのサーバーのことを指します。
ノードが所属する一群のサーバーのことをまとめて クラスター と呼びます。クラスターは マスターノード と ワーカーノード から構成されています。マスターノードは HDFS のメタデータを管理する機能やリソースの管理といったクラスターの管理を担っており、ワーカーノードは HDFS のファイルストレージやデータの処理を実際に行う機能を担っています。
クラスターの上で実行される計算は ジョブ と呼ばれており、例えばファイル中に出現する単語をカウントして合計する、といった処理のまとまりを指します。
Google Cloud Dataproc を使ってみる
それでは、早速 Google Cloud Dataproc を使ってみましょう。ここからのデモでは、 Google Cloud Dataproc を使用したクラスターの立ち上げ、 Spark のサンプルジョブの実行を行います。
まず、 GCP のコンソールを開き、左側のメニューの "Dataproc" をクリックします。
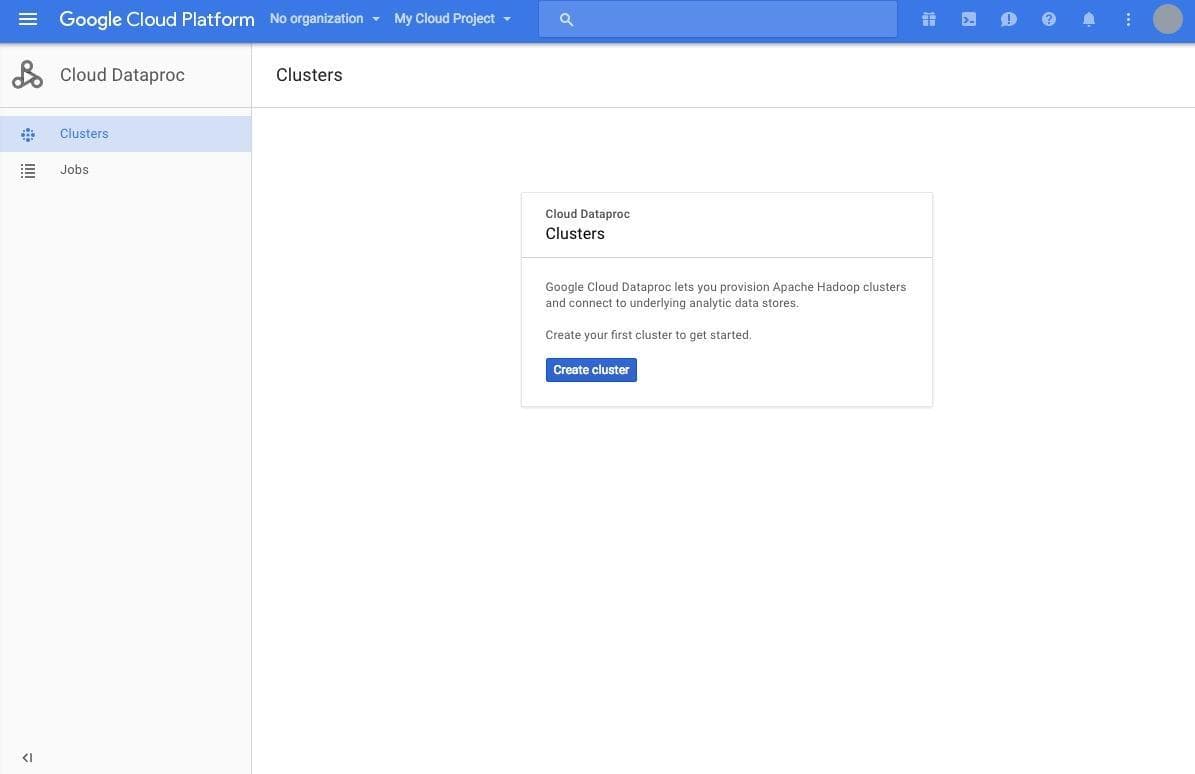
上の画面のように、 Cloud Dataproc のコンソールが開きます。初期状態では、 [Create cluster] というボタンのみが見えるかと思います。このボタンをクリックし、クラスターの作成画面を開きましょう。
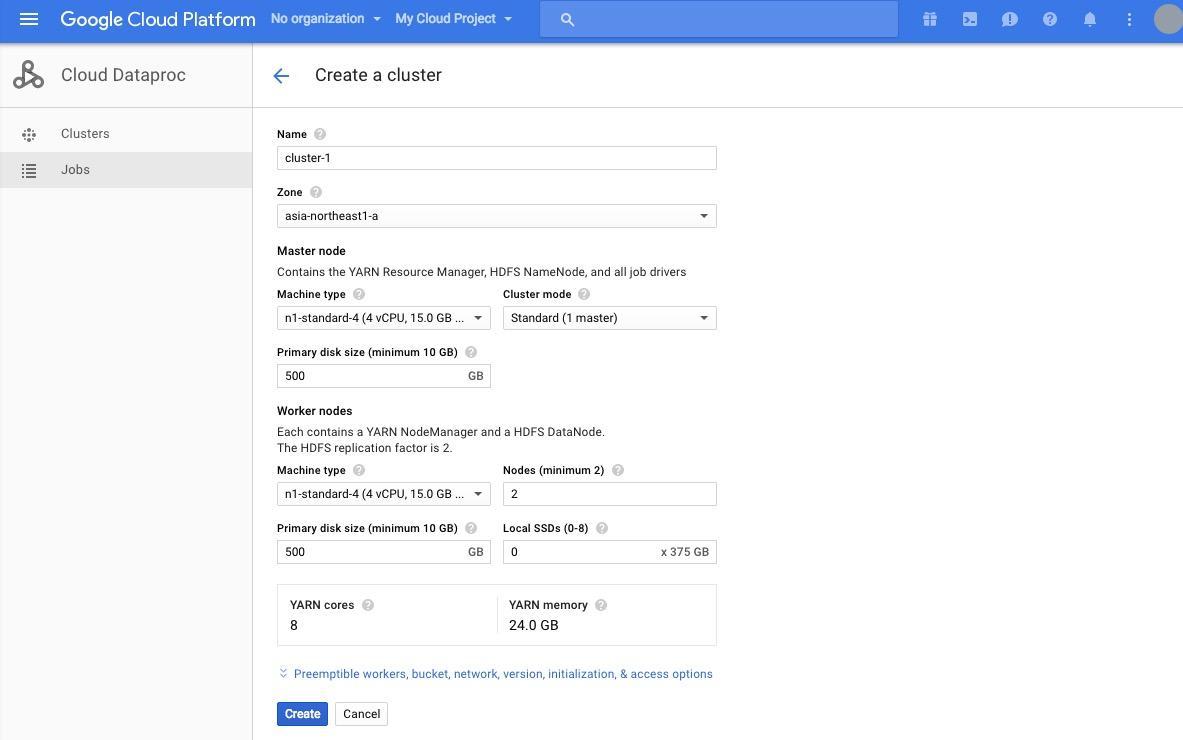
Name はデフォルトの cluster-1 に、 Zone は asia-northeast1-a を選択します。 Master Node の下に表示されている Machine Type はクラスターのマスターとなるノードの性能、 Cluster mode は高可用モードにするかどうか、 Primary disk size はディスクサイズとなっています。このデモではマスターの性能はそれほど求められませんので、 Machine Type は n1-standard-1 を選択します。
次に、 Worker nodes の下に表示されている Machine Type を n1-standard-2 に設定します。これはワーカーとなるマシンの性能の設定となります。 Nodes はノードの数を表しており、ここは2に設定しましょう。
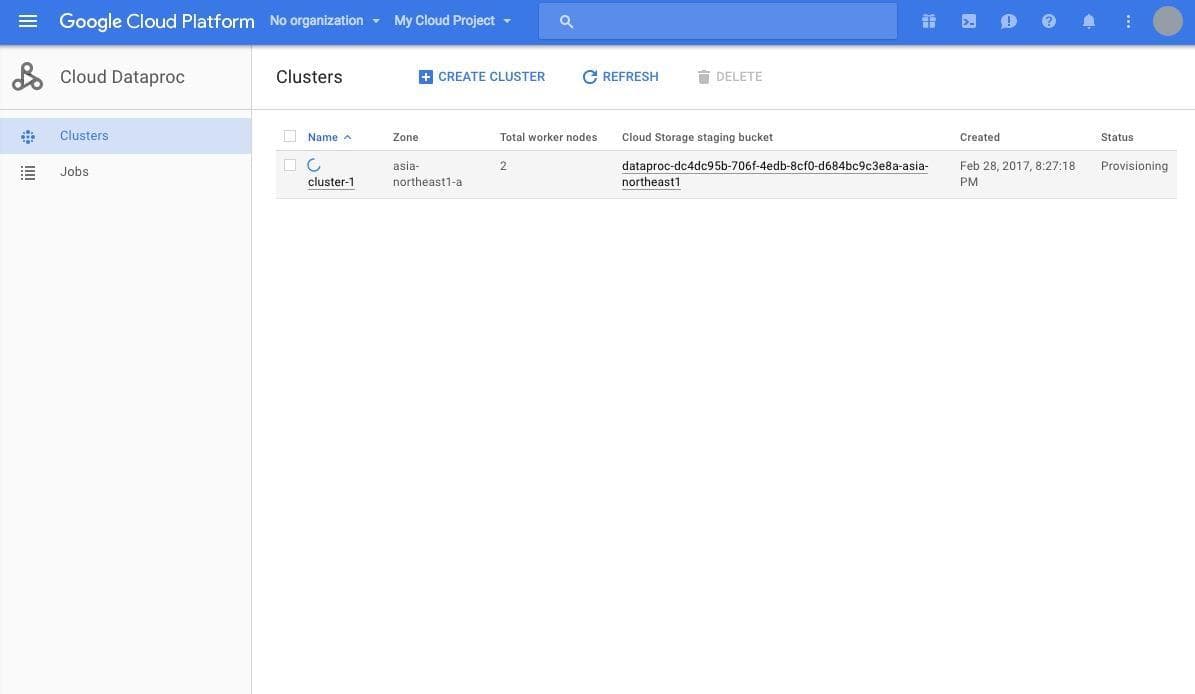
[Create] をクリックすることでクラスターの展開が開始されます。 Status が Provisioning から Running になれば、クラスターの準備は完了です。実際に Spark を使ってジョブを投げ、利用できるかどうか試してみましょう。
クラスターに対してジョブを投げるには、左側のメニューの "Jobs" をクリックします。こちらも先ほどと同様に、何もジョブが作られていないため、 [Submit Job] のボタンのみが表示されています。
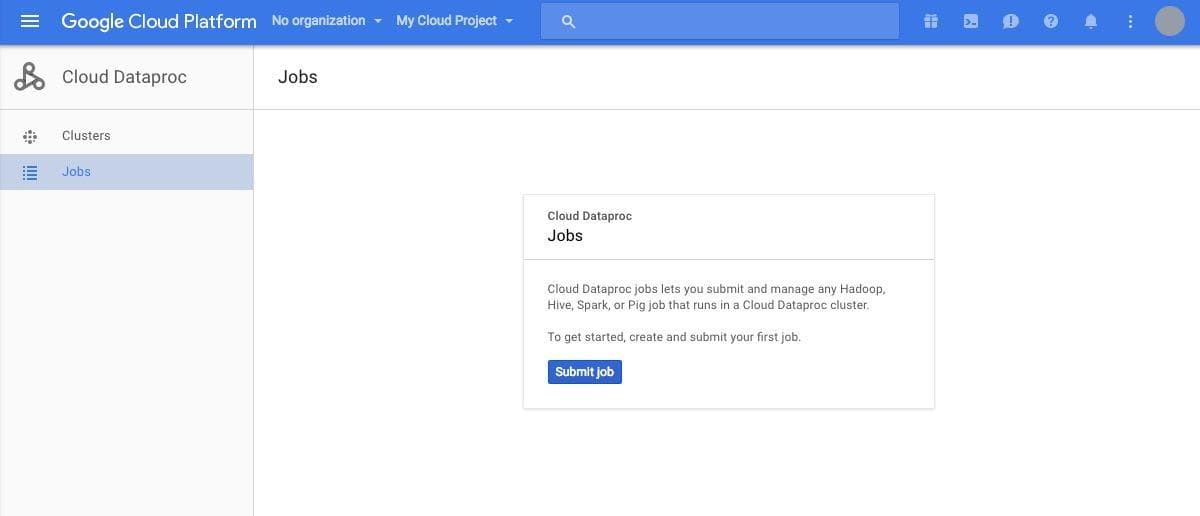
[Submit job] をクリックし、ジョブの作成画面を開きます。
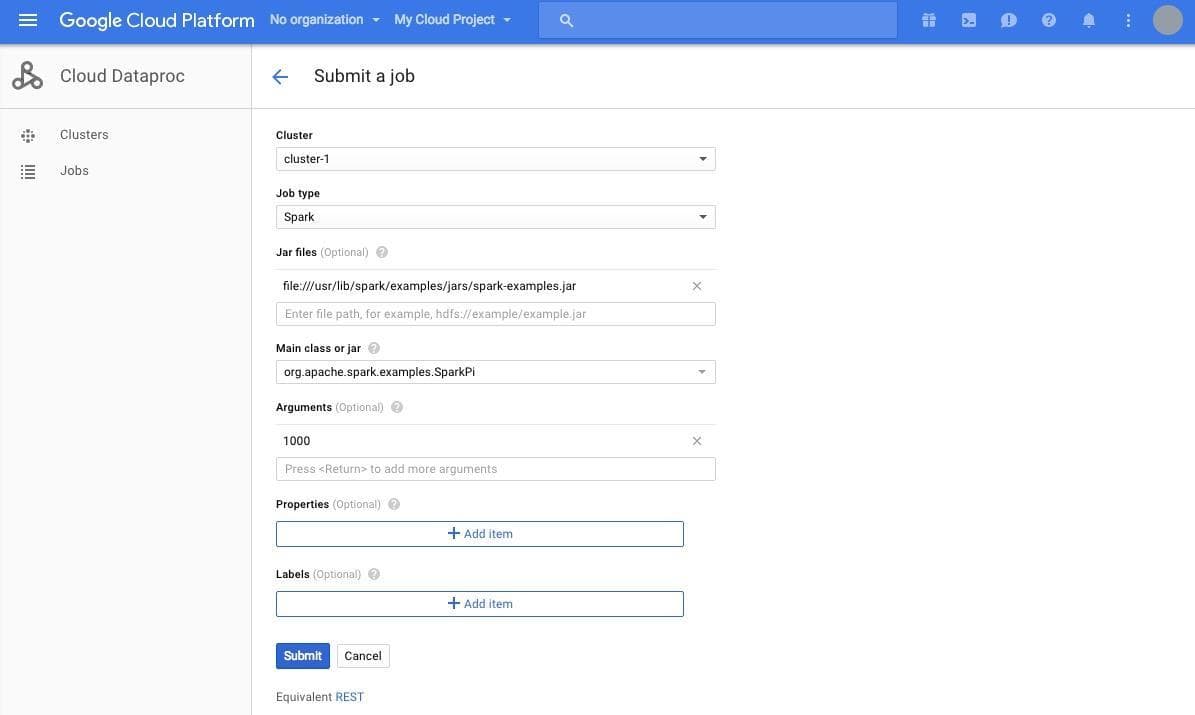
ジョブを投げる先である Cluster には先ほど作成したクラスターが表示されているかと思います。 Job Type はクラスターに対して投げるジョブの種類を指定します。今回は Spark のジョブを投げますので、 Spark を選択します。 Jar files は投げるジョブが書かれた Jar ファイルを指定します。今回は Spark に標準で付属する円周率計算のサンプルを使用します。このサンプルは円周率をモンテカルロ法を使って近似するサンプルです。 Arguments に指定した数値の数だけランダムに(0, 0), (1, 1)の正方形の中に点を打ち、中心が(0.5, 0.5), 半径が0.5の円の中に入る点の数を使って円周率を求めます。詳しくはこちらのドキュメントをご覧ください。
ここには、 "file:///usr/lib/spark/examples/jars/spark-examples.jar" と入力しましょう。 Main class or jar にはジョブのクラスを指定します。こちらは、 "org.apache.spark.examples.SparkPi" と入力します。ジョブの引数である Arguments には 1000 を指定します。
ここまで指定ができたら、 [Submit] をクリックします。
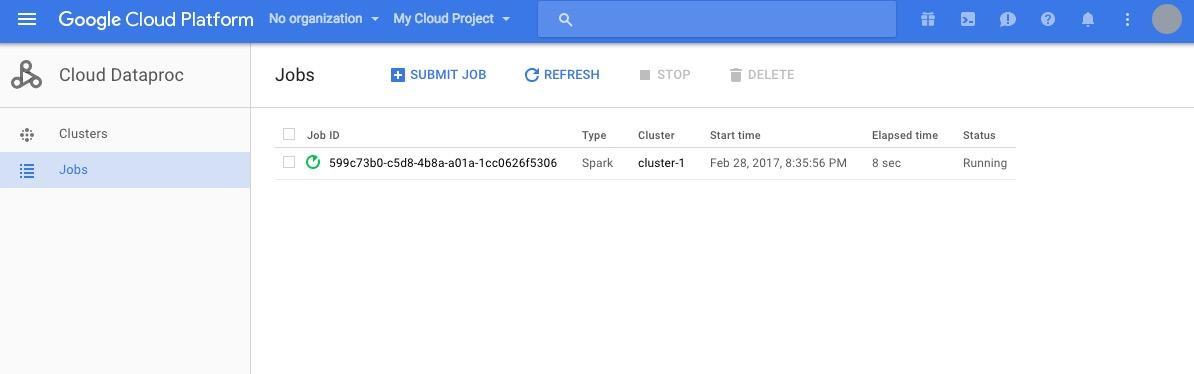
上の画面のように、ジョブが実行されます。実行中のジョブの Job ID をクリックすると、ジョブの実行ログが表示されます。
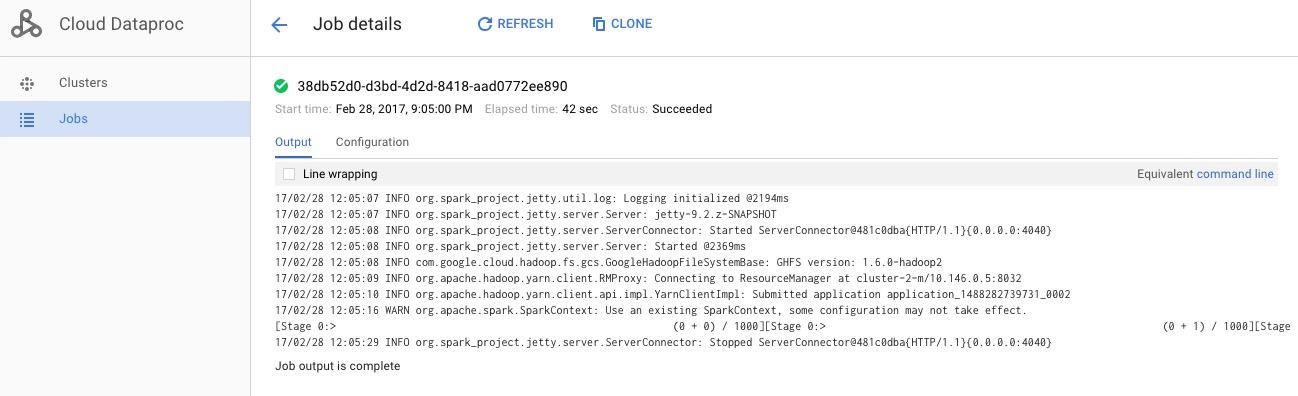
おわりに
いかがでしたでしょうか。かなり簡単にクラスターを起動し、ジョブを投げられることが実感できたのではないかと思います。このように、 Cloud Dataproc を使用すれば、ほぼ何も設定をしていない状態からものの数分でジョブを投げることができる状態になります。 Spark や Hadoop を試してみる目的にも、かなり使えるサービスなのではないでしょうか。
G-genは、Google Cloud のプレミアパートナーとして Google Cloud / Google Workspace の請求代行、システム構築から運用、生成 AI の導入に至るまで、企業のより良いクラウド活用に向けて伴走支援いたします。
関連記事


Contactお問い合わせ

Google Cloud / Google Workspace導入に関するお問い合わせ