- ホーム
- お役立ち
- Google Service
- 2022年Google発表の新サービス紹介 〜第2回 ストレージエンジン「BigLake」でデータ活用を推進!
2022年Google発表の新サービス紹介 〜第2回 ストレージエンジン「BigLake」でデータ活用を推進!
- Big Lake

2022年にGoogleが発表した新サービス紹介の第2回目はストレージエンジンBigLake。組織内のデータ活用を推進する上でBigLakeが提供するソリューション内容を解説します。
BigLakeの概要
BigLakeはDWH(データウェアハウス)とデータレイクを統合することで、データ制限を撤廃するストレージエンジンです。
組織内でデータが肥大化かつ複雑化し広範囲に拡散するとサイロが出現し、データを連携し分析を行うにはリスクや費用が増大します。
データ移動が必要な際には、リスク・費用の問題が更に大きくなります。
そういった問題へのソリューションとして登場したのがストレージエンジン「BigLake」です。
BigLakeを活用することで基盤となるストレージ形式やシステムを意識することなくデータ分析が可能となり、データのコピー・移動が不要になります。
組織内で分散されたデータに対し統一されたアクセス制御を行い、DWHとデータレイクを複数のクラウド間で統合。
Google Cloud(GCP)のDWHであるBigQuery や AWS と Azure 上のマルチクラウドデータレイク全体にわたる細かいアクセス制御、Google Cloud(GCP)とオープンソース エンジン全体で一貫したセキュリティを確保することで、データに統合的にアクセスできるようになります。
これまでのシステム上の問題から生まれていたデータ活用への壁を超え、全社データを資産として有効活用することに役立てることができます。
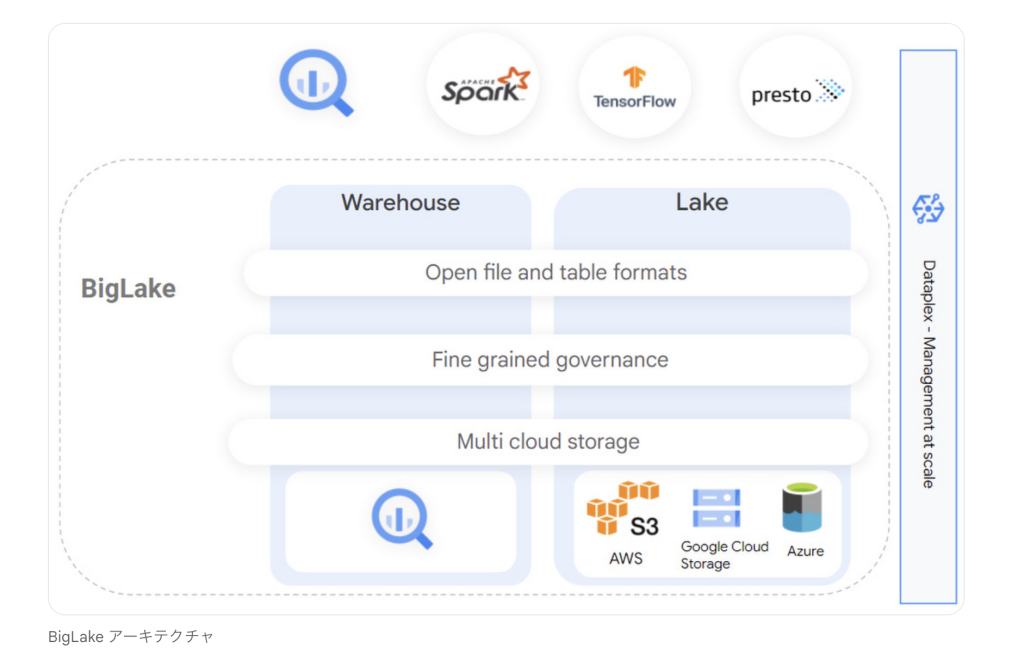 引用:Google Cloud blog
引用:Google Cloud blog
保存場所や形式によるデータ活用の縛りを軽減
よくある全社データ活用への壁
- 組織のデータが部署や拠点ごと等に分散し保存・管理され、それぞれのデータ自体も増え続けている
- 分析したいデータがマルチクラウド上でデータレイク、デーエタウェアハウス、ファイル形式も異なる
- こうしたデータを一元管理することのできるデータ分析基盤を構築することが難しい
オープンファイル形式での安全なマルチクラウドデータレイクを構築
BigLakeを導入することでデータの保存場所や方法に関係なく、分散し保存されたデータを一元管理し分析することを可能にします。
データレイクやデータウェアハウス上などに保存された各データへきめ細かいアクセス制御と共にセキュアなデータ分析環境を実現。
- 全体で統一された機能
マルチクラウドのデータレイクやデータウェアハウスなどデータの保存場所や方法に関係なく分散データの分析が可能になる - きめ細かいアクセス制御とマルチクラウドガバナンスを提供
エンドユーザーにファイルレベルのアクセス権を付与する必要がなくなりBigQueryと同様のテーブル、行、列レベルのセキュリティポリシーを適用する。Dataplexと統合して大規模な管理機能を提供 - オープンソースの分析ツールとオープンファイル形式をシームレスに統合
Google Cloud(GCP)とBigQuery、Vertex AI、Dataflow、Sparkなどのオープンソースで統一的にデータにアクセスできる。Parquet、ORC、Avro などの一般的なオープンデータ形式にアクセスできる
データの移動なしで、ストレージ形式を気にせず異なるシステム同士のデータを一元管理しデータ分析に専念できる環境構築を実現します。
費用
BigLakeの料金はデータソースがどこにあるか?どこからのクエリかにより課金される体系となっています。
- BigLakeテーブルに対してはBigQueryの料金と同じ料金体系を適用
- Amazon S3 と Azure Data Lake Gen2で定義されたBigLakeテーブルに対するクエリにはBigQuery Omniの料金を適用
例)BigQuery Omni は現在、クエリのコストが予測可能な定額料金制を提供。$2500/100スロット AWS US-East-1(北バージニア) - Apache Spark、Trino、Apache Hiveなどのオープンソース エンジンからのクエリは BigQuery Storage API を使用し、対応する料金を適用(バイト数の読み取りと下りの料金が請求されます)
・バッチ読み込み
例)共有スロットプールの使用は無料(データが BigQuery に読み込まれると、ストレージの料金が発生します。)
・ストリーミング
例)$0.010 per 200 MB
まとめ
事業活動を行う中で財務・会計・生産・販売データなどに加え、営業活動で得た顧客データ、更に自社WEBサイト上のユーザーの行動履歴など日々多くのデータが組織内に蓄積されてゆきます。
それらを社内各部門から必要なデータを必要な時に抽出し全社横串のデータ分析まで行えるようなデータ統合基盤が整っていれば、営業戦略立案やマーケティング施策の実施など大きなアドバンテージと共にビジネスを行うことが可能となります。
しかし、組織内でデータが複数の場所に分散し保存され全社データを一括処理するには手間と時間がかかるなど問題を抱えているケースも多いのではないでしょうか。
BigLakeは安全でパフォーマンスの高いデータレイクの実行や大規模な統合ガバナンスと管理の実現など、組織内のサイロ化した環境下であらゆるデータ制限を排除し細かなアクセス制御を可能とします。
BigLakeの導入により、組織内で分散し保管されているデータを連携し分析環境を構築することで社内データを最大限活用することを可能とし業務効率化など組織全体のコスト削減と生産性向上を実現します。
データ活用を推進する上で課題を抱えているなどあれば是非導入を検討してみてはいかがでしょうか。
G-genは、Google Cloud のプレミアパートナーとして Google Cloud / Google Workspace の請求代行、システム構築から運用、生成 AI の導入に至るまで、企業のより良いクラウド活用に向けて伴走支援いたします。
関連記事


Contactお問い合わせ

Google Cloud / Google Workspace導入に関するお問い合わせ