- ホーム
- お役立ち
- Google Service
- Cloud Spanner で性能調査をするためのポイントとは? RDBMS の一般的な観点も交えて徹底解説!
Cloud Spanner で性能調査をするためのポイントとは? RDBMS の一般的な観点も交えて徹底解説!
- Key Visualizer
- RDBMS
- 分散データベース
- 性能調査
本記事は、2021年9月9日に開催された Google の公式イベント「データクラウドサミット」において、データベーススペシャリストの佐藤貴彦氏が講演された「 Cloud Spanner で性能調査をするための5つのポイント」のレポート記事となります。
今回は Cloud Spanner の特徴をご紹介しつつ、 Cloud Spanner で性能調査をするためのポイントを詳しくご紹介します。 Cloud Spanner 特有の観点と RDBMS の一般的な観点の両面から解説していますので、ぜひ最後までご覧ください。
なお、本記事内で使用している画像に関しては、データクラウドサミット「 Cloud Spanner で性能調査をするための5つのポイント」を出典元として参照しております。
また、参考動画のタイトルには「5つのポイント」と記載がありますが、本記事では大きく4つのポイントに分けて全体を構成しています。動画の内容を踏まえて、ポイントを4つに分類した方が理解が深まると感じましたので、この点はあらかじめご了承ください。
それでは、早速内容を見ていきましょう。
Cloud Spanner とは?
Cloud Spanner は Google が提供しているリレーショナルデータベース(以下 RDB と記載)です。 RDB とはデータベースの一種であり、日本語では「関係データベース」と呼ばれることもあります。
RDB はデータを複数の表として管理し、それぞれの関係を定義することで複雑なデータ処理を可能にします。RDB は規模を問わずに利用されており、個人用途から大企業の社内システムまで、幅広いシーンで活躍しています。
Cloud Spanner は ACID に準拠した RDB データベースであり、様々な処理を自動で行うことができます。そのため、シーンに応じた最適な処理を実現することが可能になります。
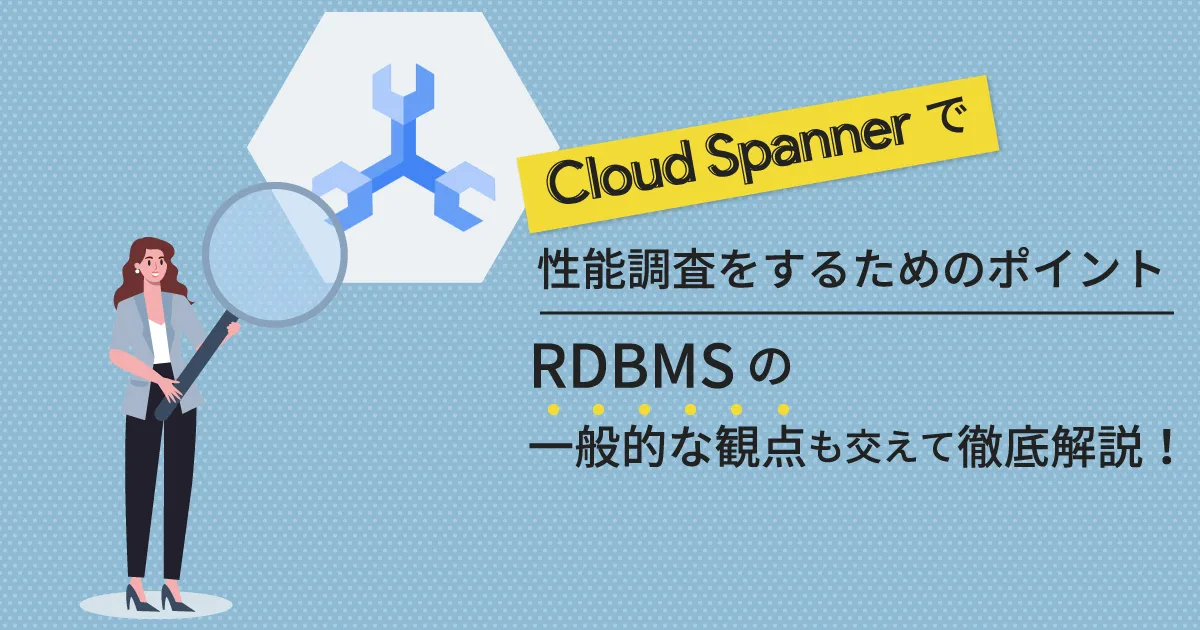
以下、 Cloud Spanner の特徴をまとめました。
Cloud Spanner の大きな特徴として、運用が簡単なフルマネージド RDBMS (リレーショナルデータベース管理システム) である点が挙げられます。最大で 99.999% の高い可用性を誇り、自動シャーディングによる無制限のスケーラビリティも忘れてはいけないポイントです。
Cloud Spanner に関心のある方は以下の記事がオススメです。
Google のリレーショナルデータベース Cloud Spanner とは?概要、特徴、メリット、活用事例まで一挙に紹介!
異なる DBMS から効率的に Cloud Spanner へ移行!ツールを活用したマイグレーション方法を徹底解説!
Cloud Spanner と Cloud SQLの比較をした記事もありますので、あわせてご覧ください。
Cloud Spanner と BigQuery を活用してリアルタイム分析する方法について解説した記事もありますので、あわせてご覧ください。
BigQuery から Cloud Spanner に直接クエリを実行し、トランザクションデータをリアルタイムに分析しよう
Cloud Spanner で性能調査をするためのポイント1.分散データベース Cloud Spanner の特徴を把握する
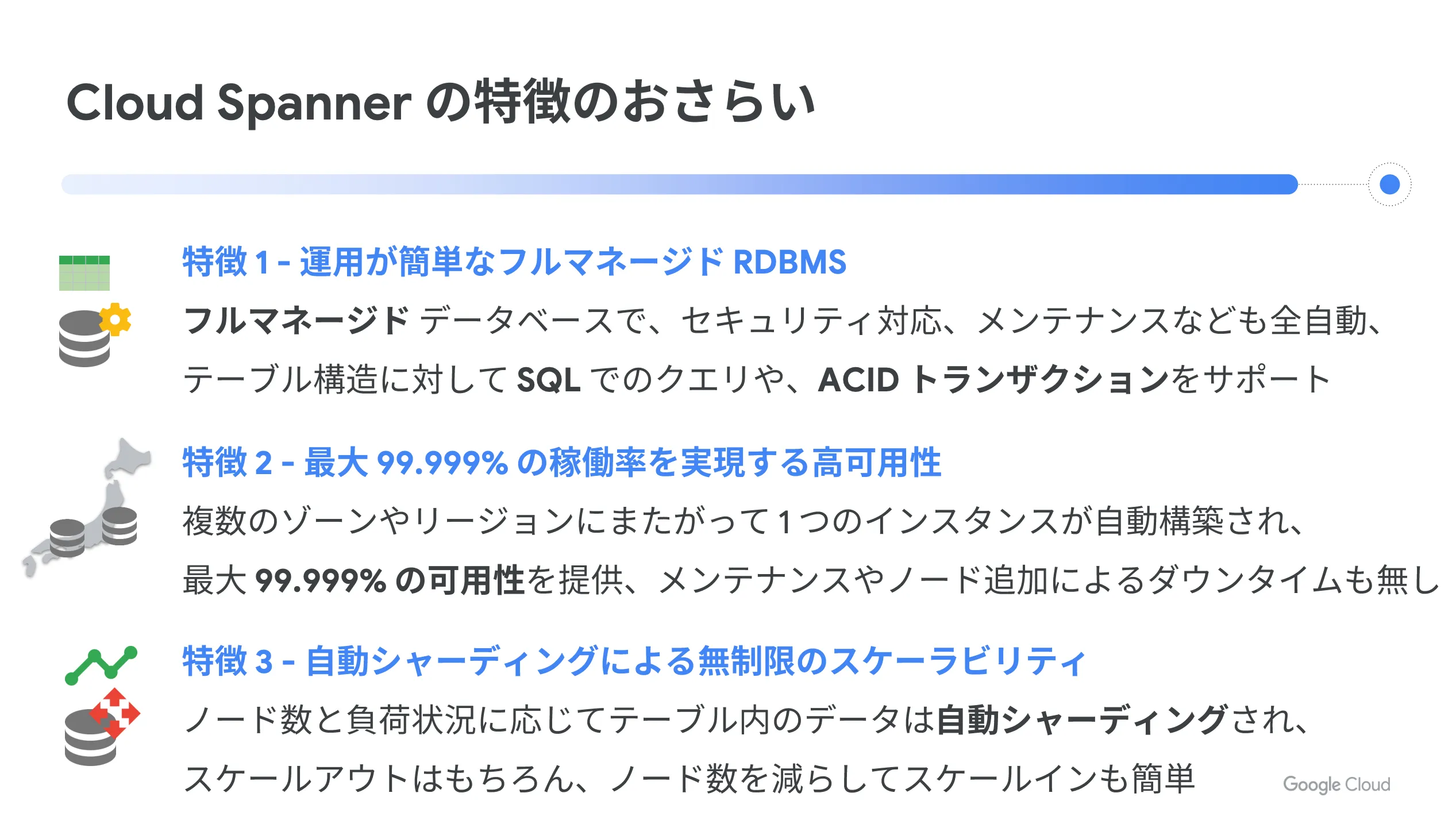
Cloud Spanner はノードを追加することで性能が向上します。 Cloud Spanner はテーブルの自動シャーディング機能と、シャードに対する問い合わせを自動ルーティングする機能を持っています。ノードを増減させた場合でも、それに合わせてテーブルを自動的に水平分割するため、ノードを増やすほど性能を向上させることが可能になります。
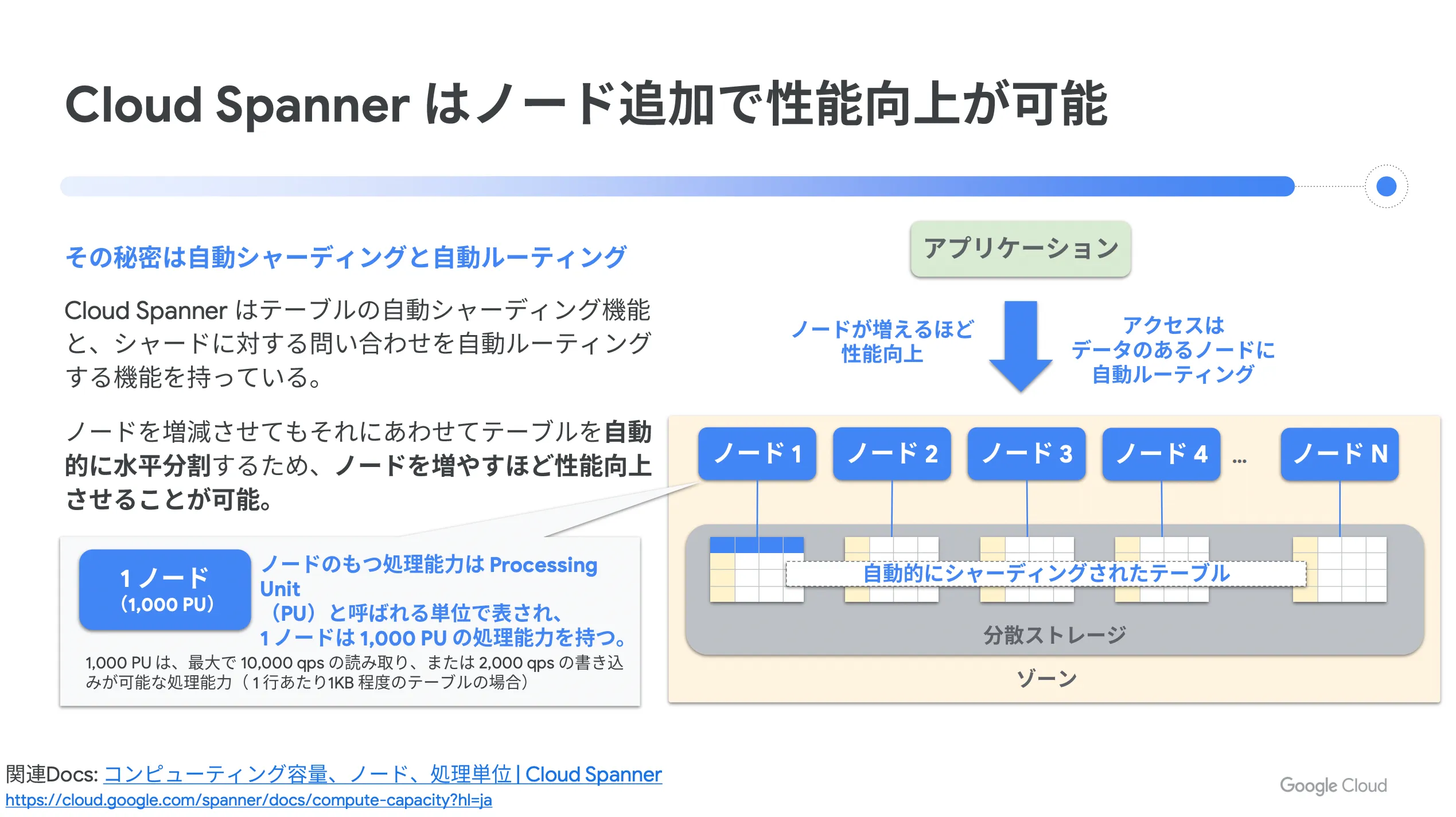
Cloud Spaner はテーブルの PK (主キー)のレンジで自動シャーディングをしているため、 PK へのアクセスが常に偏り続けることは、特定のシャードにアクセスが偏ってしまうことになります。これは一般的な RDBMS のシャーディングにおいて特定シャードへアクセスが偏っているのと同じことですが、 Cloud Spanner は偏った負荷に対処する仕組みを持っています。
また、 Cloud Spanner は現在の負荷に最適化してシャーディングをし続けます。ある程度負荷が偏った場合でも、アクセスされているテーブルや行範囲をさらに分割したり、他のノードに移動したりして、動的にシャーディングし直してくれるため、ある程度の偏りは問題ないと言えます。
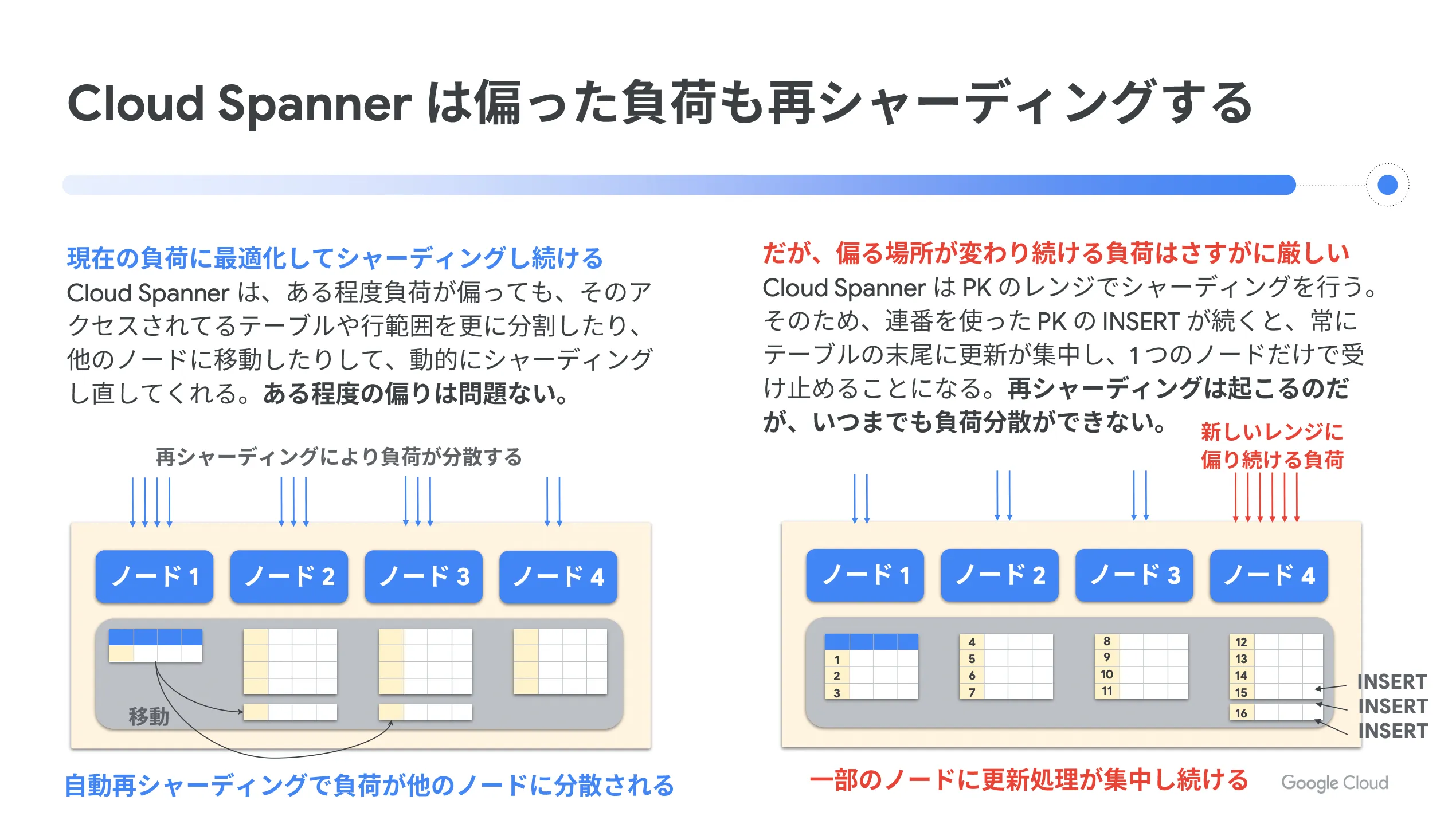
そして、 Cloud Spanner の性能を発揮するためには、ベストプラクティスに従うことが大切です。ドキュメントに記載のあるベストプラクティスに従うことで、 Cloud Spanner の特性を考慮した設計となり、 Cloud Spanner が得意としないパターンを避けることができます。
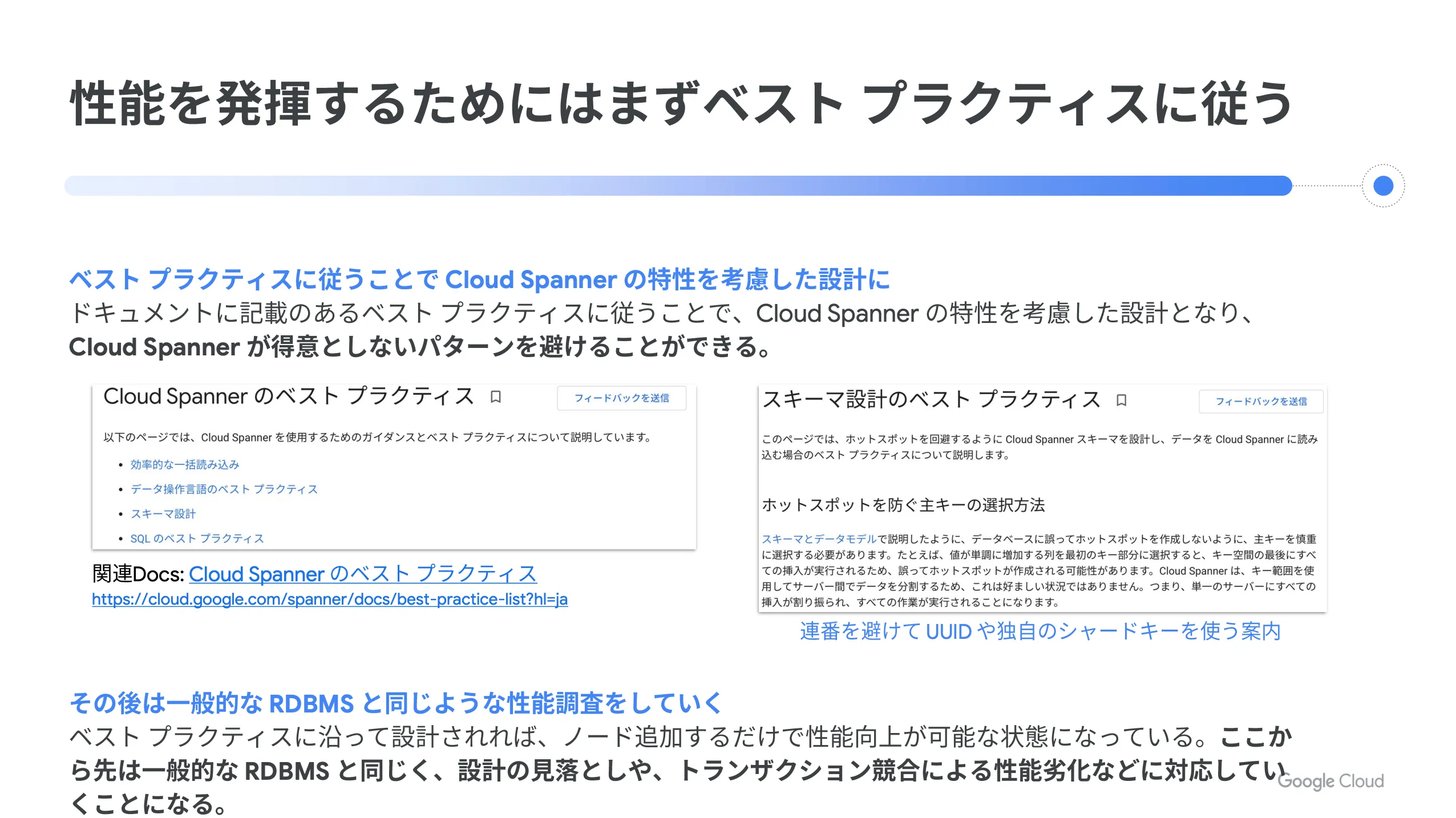
設計した後は一般的な RDBMS と同じような性能調査を実施します。ベストプラクティスに沿って設計されていれば、ノード追加を行うだけで性能向上が可能な状態になっています。この先は、設計の見落としやトランザクション競合による性能劣化などに対応していくことになります。
Cloud Spanner で性能調査をするためのポイント2. CPU 使用率を確認し、必要に応じてノードを足す
Cloud Spanner の性能を向上させるためには、インスタンスやデータベース全体の状態を把握して、リソースが不足している場合はノードを足す、というのが基本的な考え方になります。
以下、実際の Cloud Spanner の CPU 使用率の画面です。
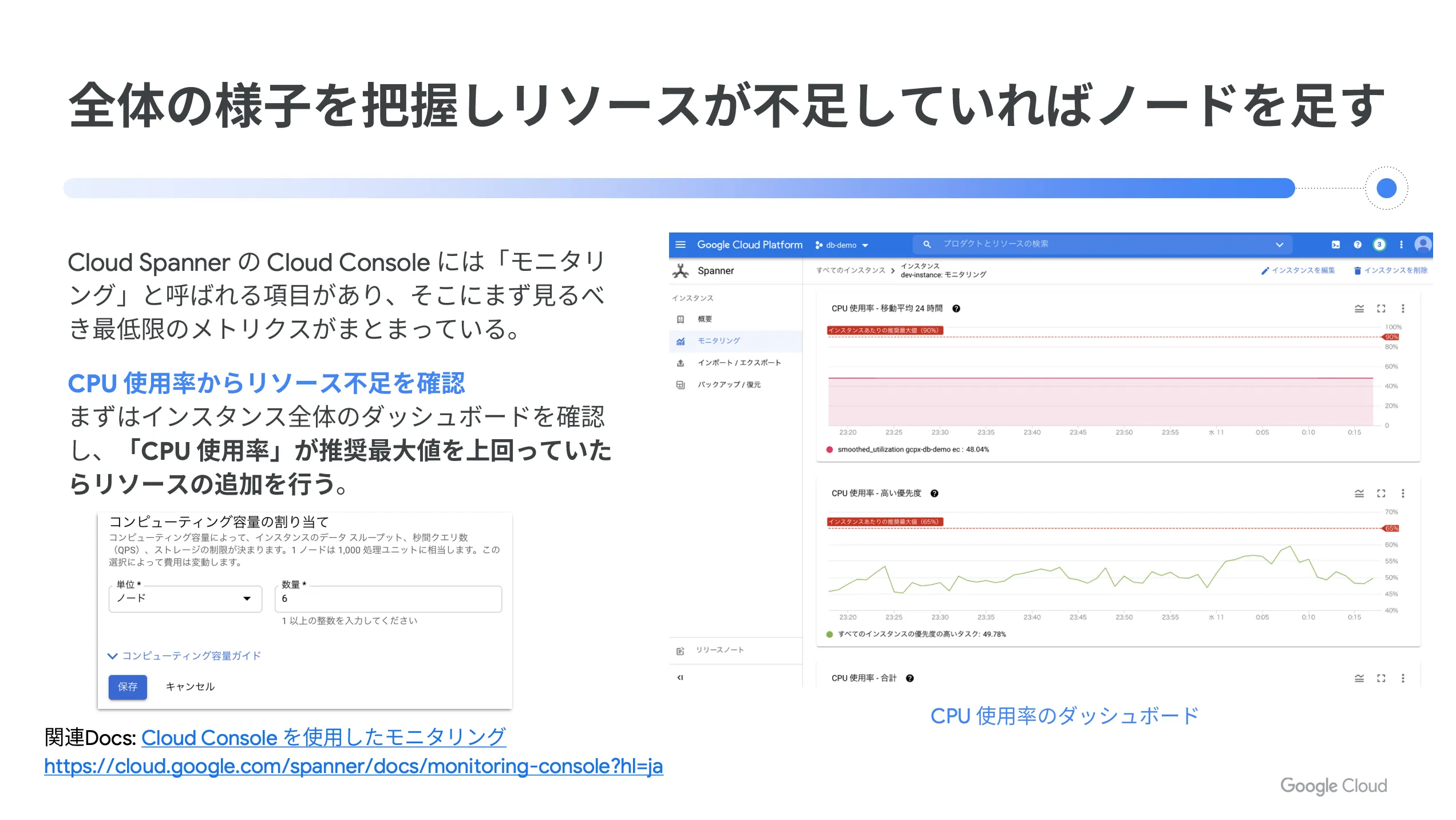
Cloud Spanner の Cloud Console には「モニタリング」と呼ばれる項目があり、そこに最低限の見るべきメトリクスがまとまっています。まずはインスタンス全体のダッシュボードを確認し、「 CPU 使用率」が推奨最大値を上回っていたらリソースの追加を行います。
また、テストではノード追加でスループットが向上することを確認してください。データベースの一般論として、闇雲に性能を追い求めるのではなく、目標となる性能指標を満たせているかどうかが重要になります。そのため、まずはスループット( ops )やレイテンシ( ms )などが目標通りに出ているのかを確認しましょう。
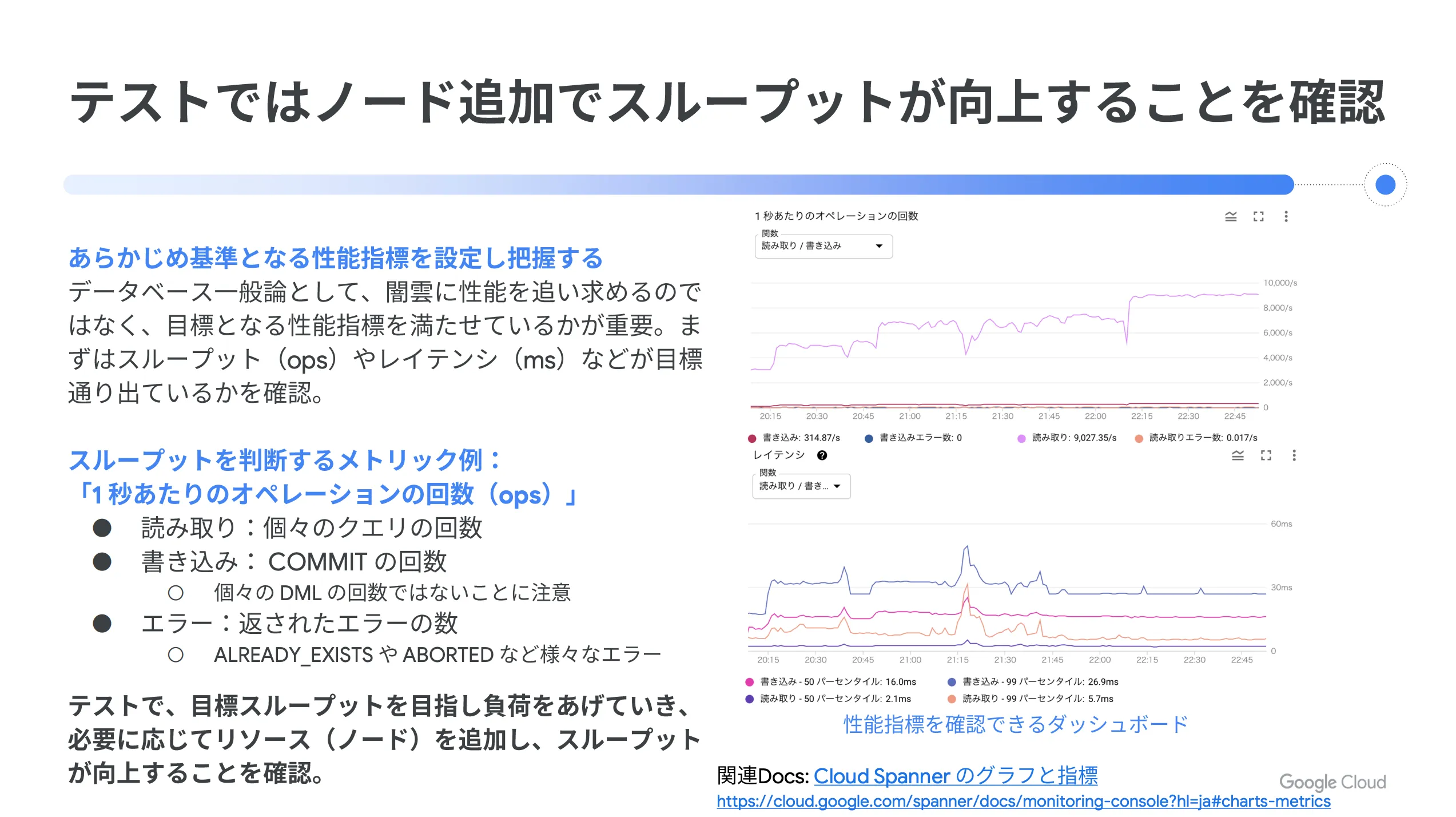
そして、 CPU 使用率の判断は推奨最大値を超えているかどうかで行ってください。 CPU 使用率には2種類の指標があり、グラフに推奨値が波線で表されているので、双方のグラフで閾値を超えていないかを確認します。
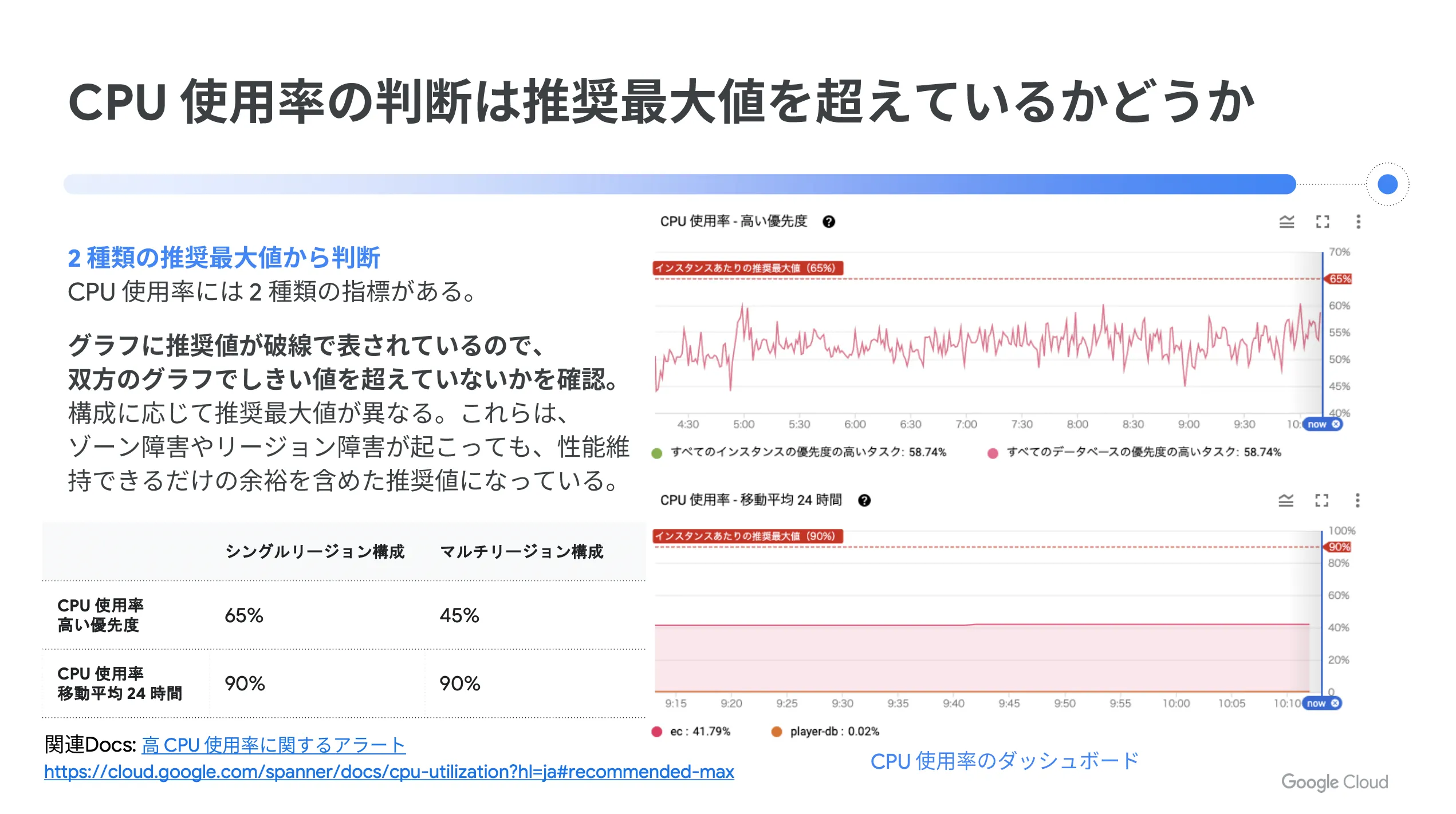
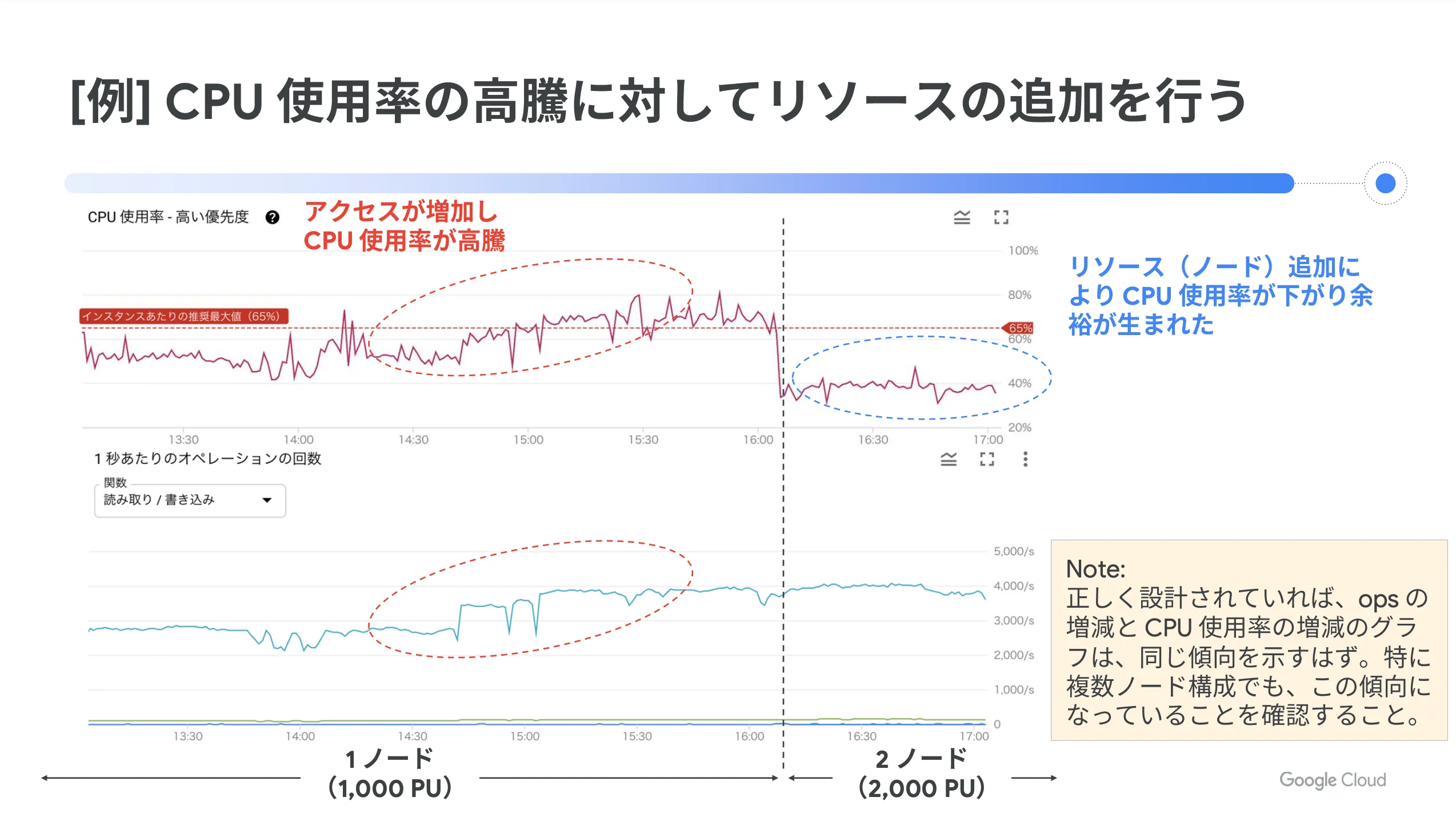
一例として、 CPU 使用率の高騰に対してリソース追加を行う場合の図を以下に示します。正しく設計されていれば、スループットの増減と CPU 使用率の増減のグラフは同じ傾向になるので、その点も一つの確認ポイントになります。
Cloud Spanner で性能調査をするためのポイント3.処理の内訳やテーブルアクセスの偏りを確認
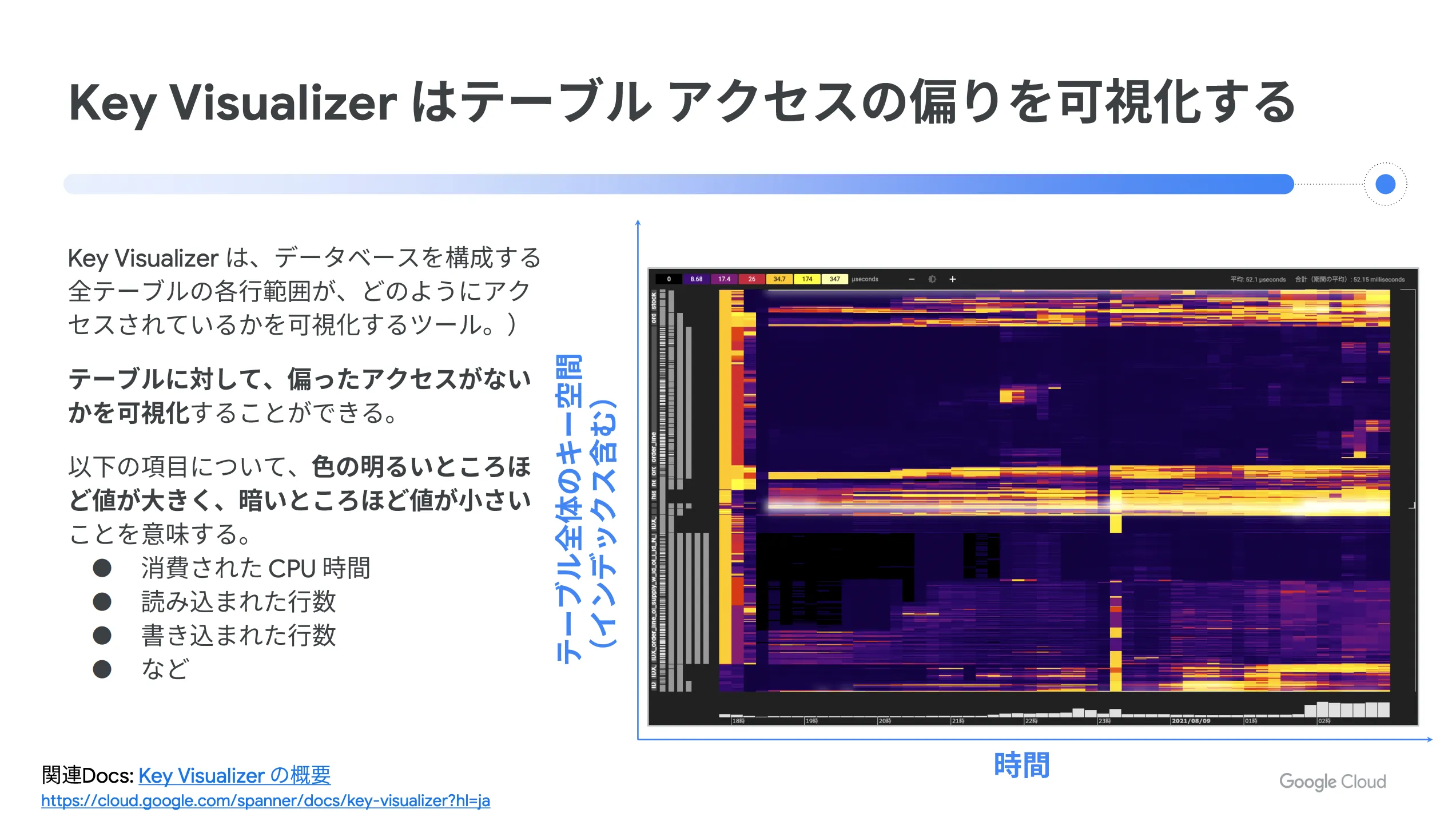
次に、処理の内訳やテーブルアクセスの偏りを確認します。 Cloud Spanner には Key Visualizer という機能が搭載されており、これを使うことでテーブルアクセスの偏りを可視化することができます。
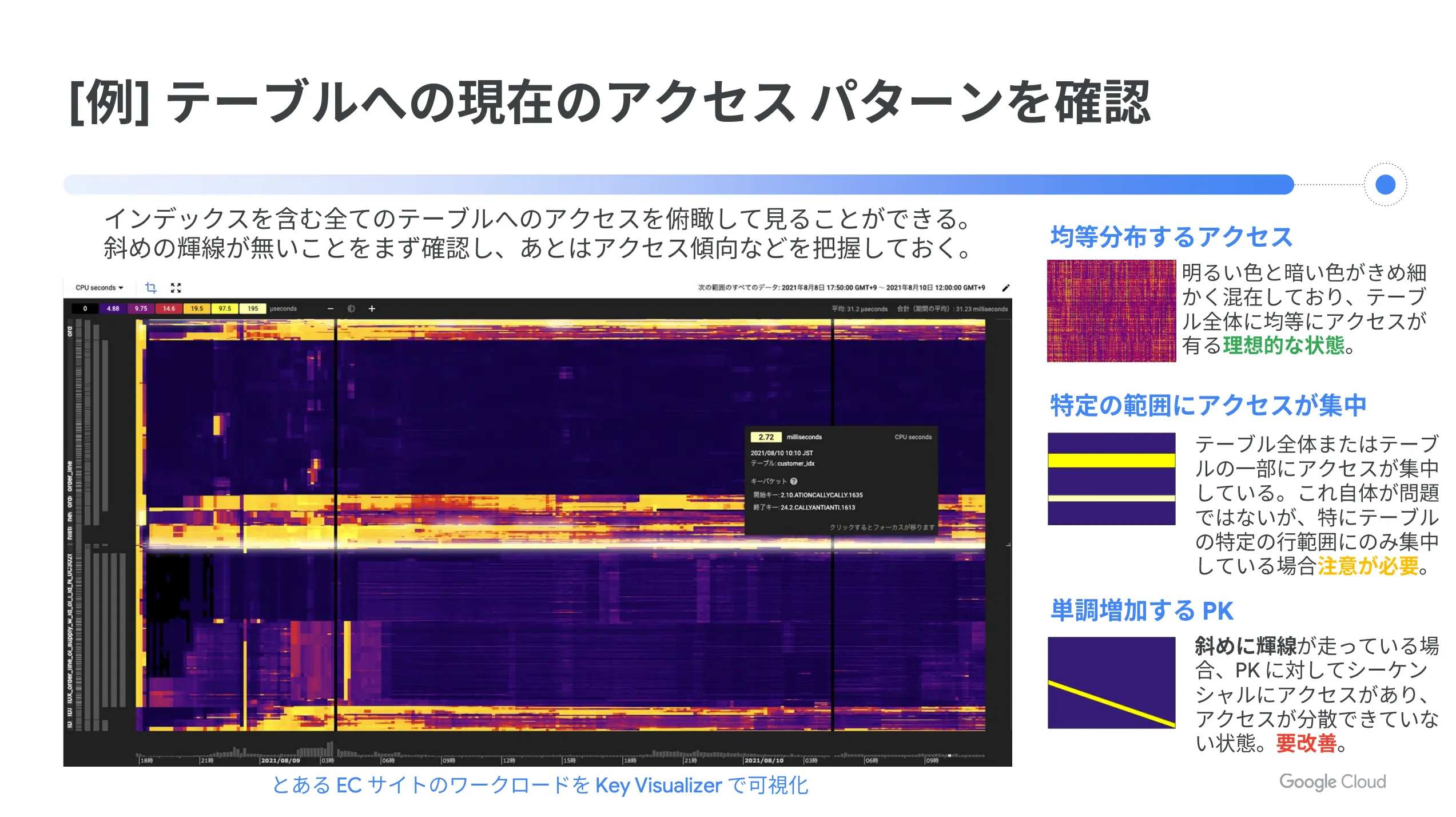
例えば、テーブルへの現在のアクセスパターンを確認してみましょう。下図のように、インデックスを含むすべてのテーブルへのアクセスを俯瞰して見ることができます。まずは斜めの斜線がないことを確認し、あとはアクセス傾向などを把握します。
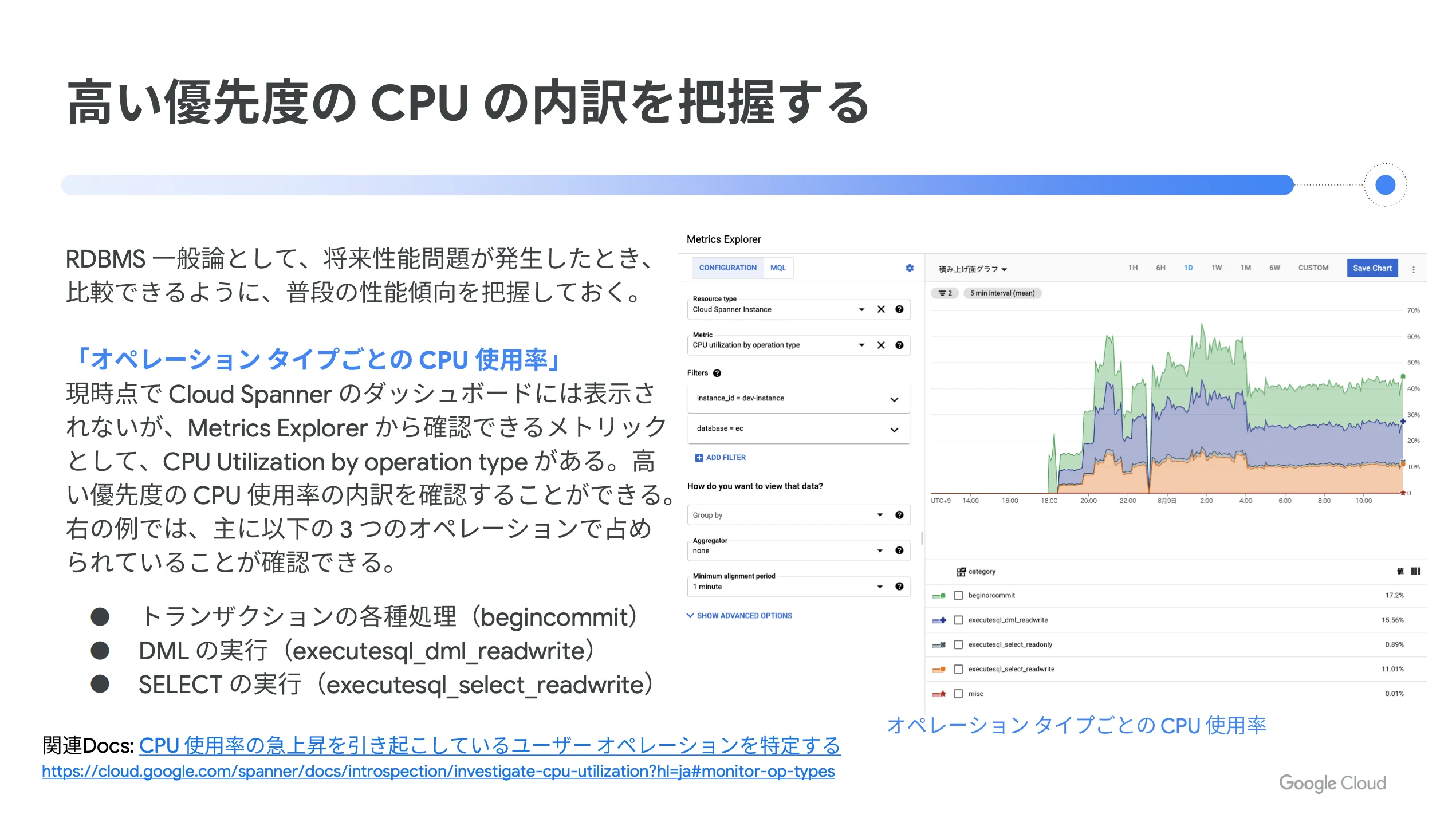
また、 RDBMS の一般論として、将来性能問題が発生した時に比較できるように、普段の性能傾向を把握しておく必要があります。オペレーションタイプごとの CPU 使用率は、現時点では Cloud Spanner のダッシュボードには表示されませんが、 Metrics Explorer から確認できるメトリクスとして CPU Utilization by operation type があります。
これにより、高い優先度の CPU 使用率の内訳を確認することが可能になります。例えば、下図の右側の部分では、「トランザクションの各種処理」、「 DML の実行」、「 SELECT の実行」という3つのオペレーションで占められていることが確認できます。
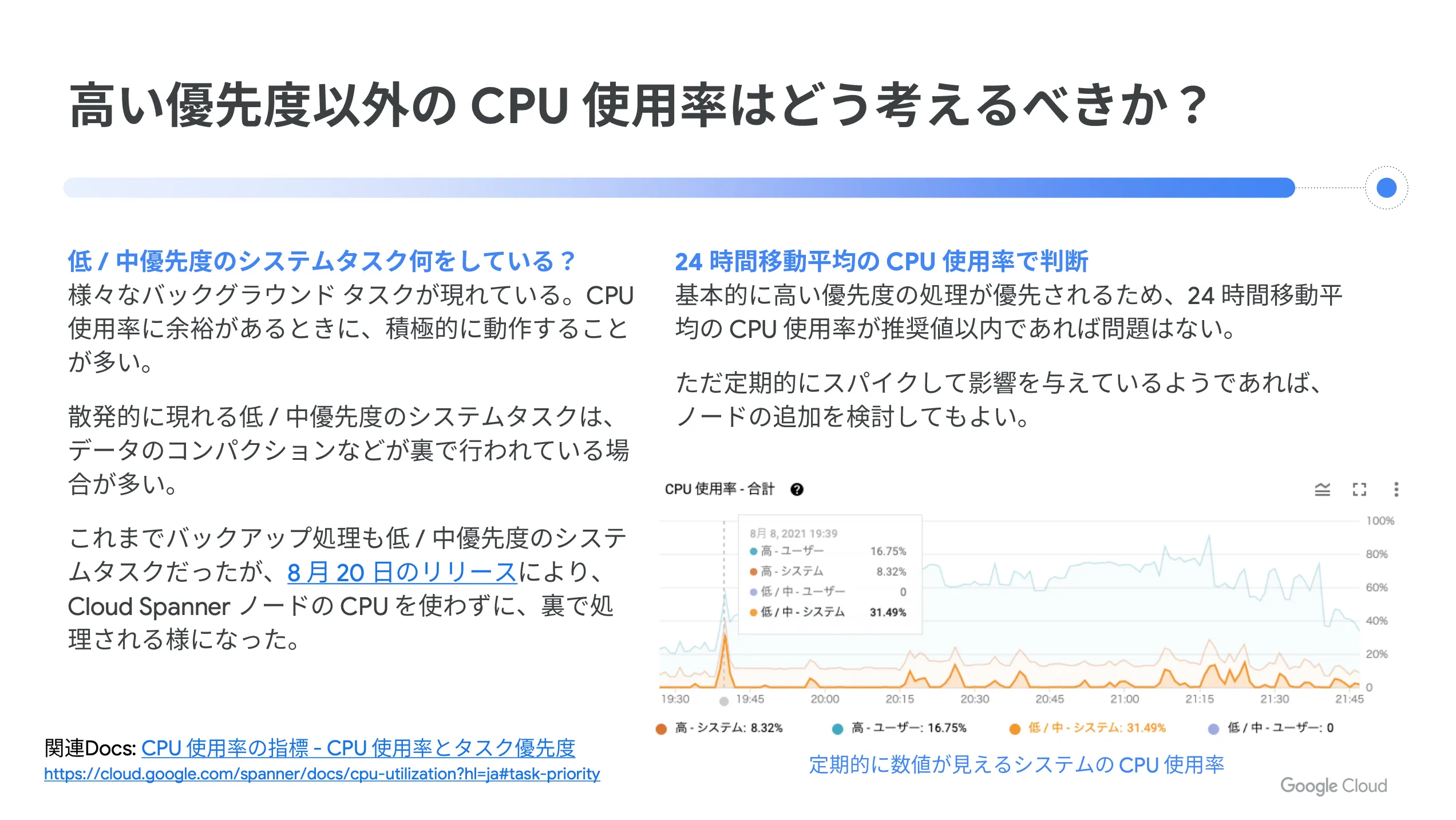
ここで、高い優先度以外の CPU 使用率について考えてみましょう。散発的に現れる低中優先度のシステムタスクはデータのコンパクションなどが裏で行われている場合が多く、これまではバックアップ処理も低中優先度のシステムタスクでしたが、2021年8月20日のリリースにより、 Cloud Spanner のノード CPU を使わずに裏で処理されるようになりました。
基本的には高い優先度の処理が優先されるため、24時間移動平均の CPU 使用率が推奨値以内であれば問題はありません。ただ、定期的にスパイクして影響を与えている場合にはノード追加を検討しても良いかもしれません。
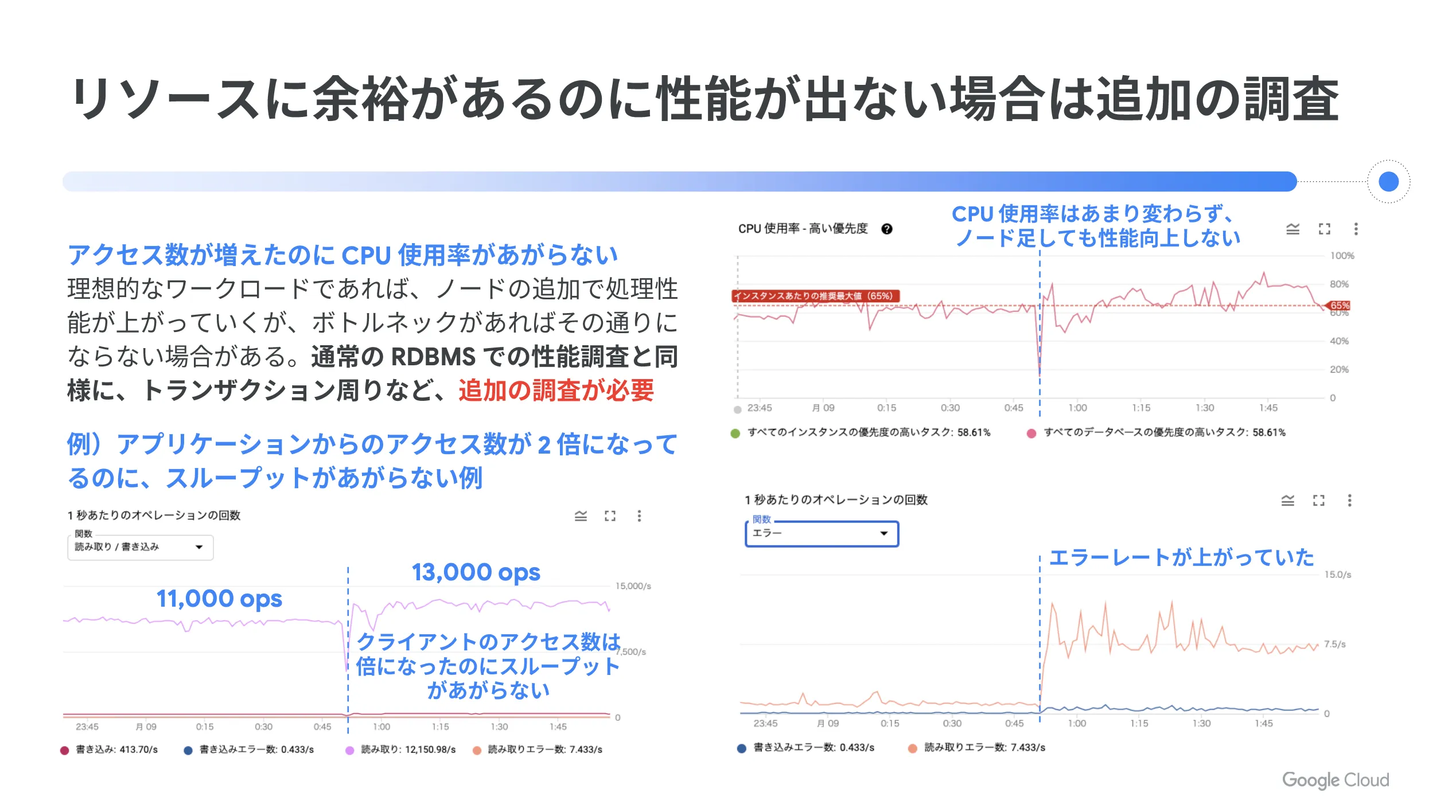
また、リソースに余裕があるのに性能が出ない場合は追加調査が必要になります。理想的なワークロードであれば、ノード追加によって処理性能が上がりますが、ボトルネックがあればその通りにならないケースもあります。通常の RDBMS と同様にトランザクション周りなどの追加調査を実施してください。
Cloud Spanner で性能調査をするためのポイント4.各種統計情報からトランザクションの状況確認
ここまでは Cloud Spanner 固有の話でしたが、ここからは RDBMS の一般的な内容に移っていきます。本章では、統計情報からトランザクションの状況を確認する際の詳細についてご説明します。
Cloud Spanner でクエリやトランザクションの状況を確認するためには、各種統計テーブルを使います。これらはイントロスペクションツールと呼ばれており、 Cloud Console のクエリや gcloud コマンドなどから SQL を使って各種情報を確認できます。

また、 Cloud Console のクエリ画面には「クエリテンプレート」が用意されており、各統計の代表的なクエリ例をそのまま実行することができます。その他、 Google Cloud の公式ドキュメントにあるクエリ例を参考にしながら、必要に応じて組み合わせて活用します。

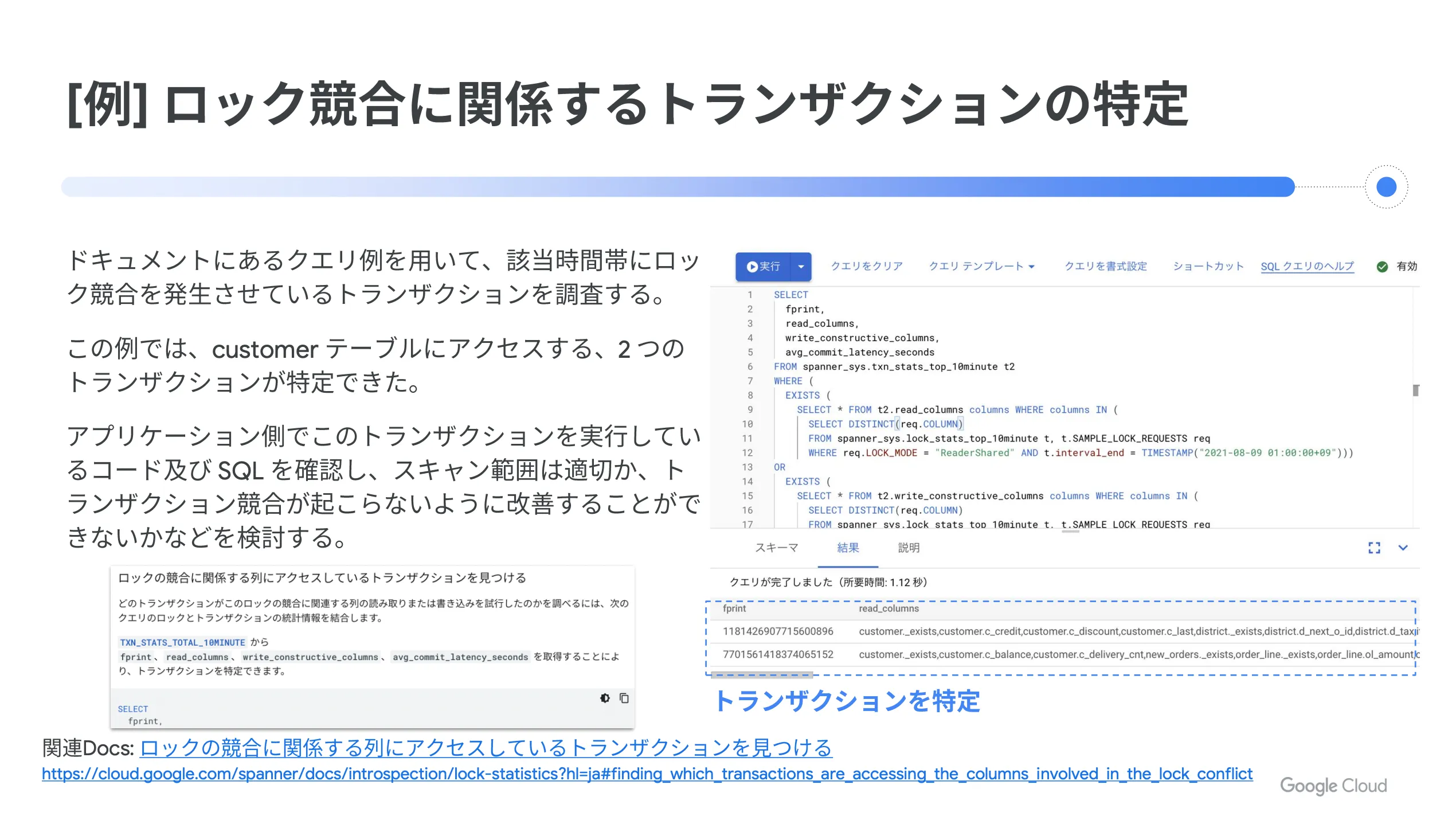
例えば、ロック統計から待機時間の調査を行う場合を見てみましょう。ロック統計から、エラーが頻発していた時間帯のロック状況を確認すると、アクセス数が増えてエラー数が増加しているタイミングから、顕著にロック待機時間が増えていました。そして、そもそもロック待機時間が長い傾向にあるように見えます。
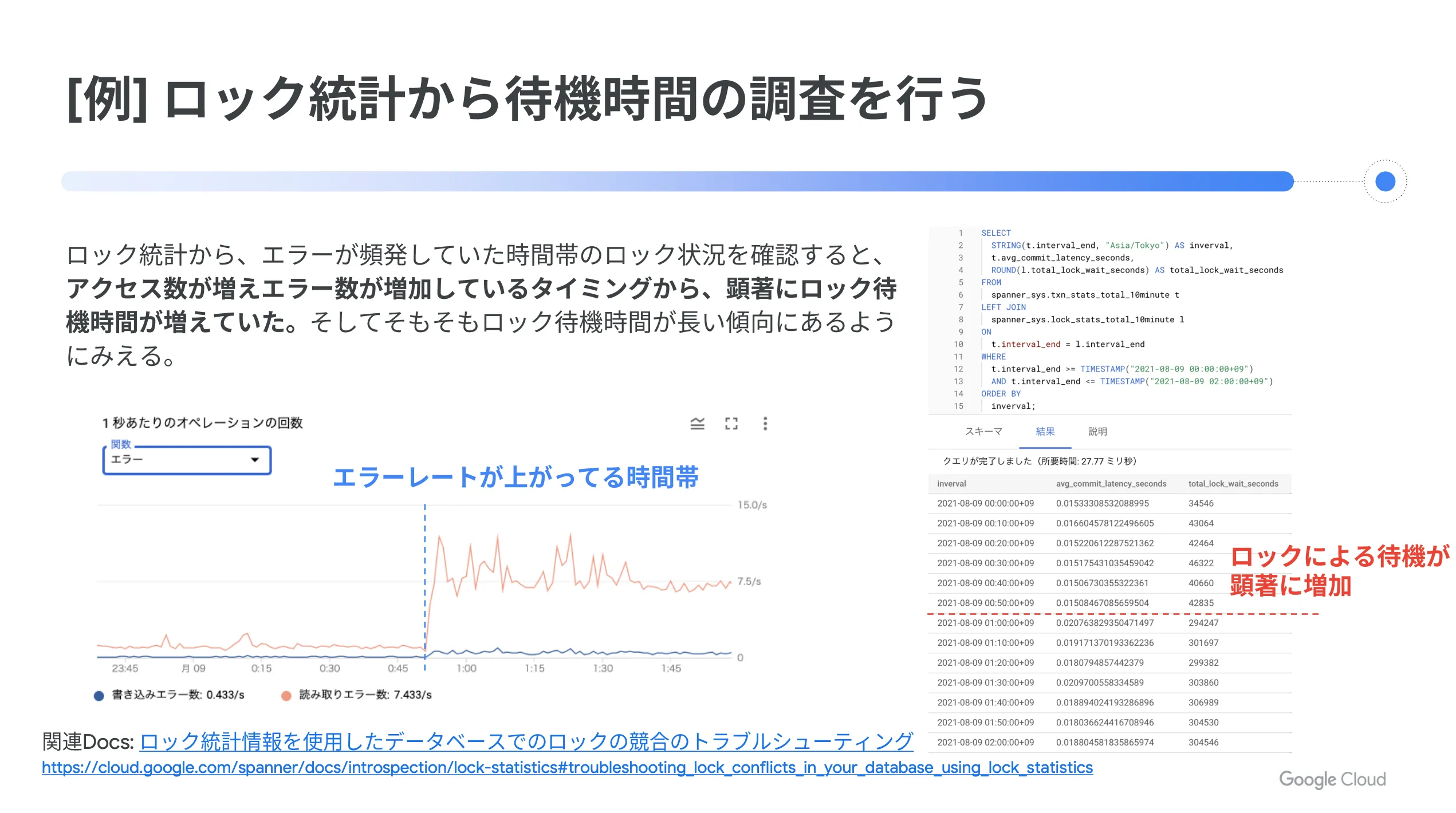
そこで、 Google Cloud の公式ドキュメントにあるクエリ例を使って、該当時間帯にロック競合を発生させているトランザクションを調査します。今回の例では、 customer テーブルにアクセスする2つのトランザクションが特定できました。
その後、アプリケーション側でこのトランザクションを実行しているコードおよび SQL を確認し、スキャン範囲は適切か、トランザクション競合が起こらないように改善できないか、などを検討します。
まとめ
本記事では、 Cloud Spanner の特徴をご紹介しつつ、 Cloud Spanner で性能調査をするためのポイントを詳しくご紹介しました。
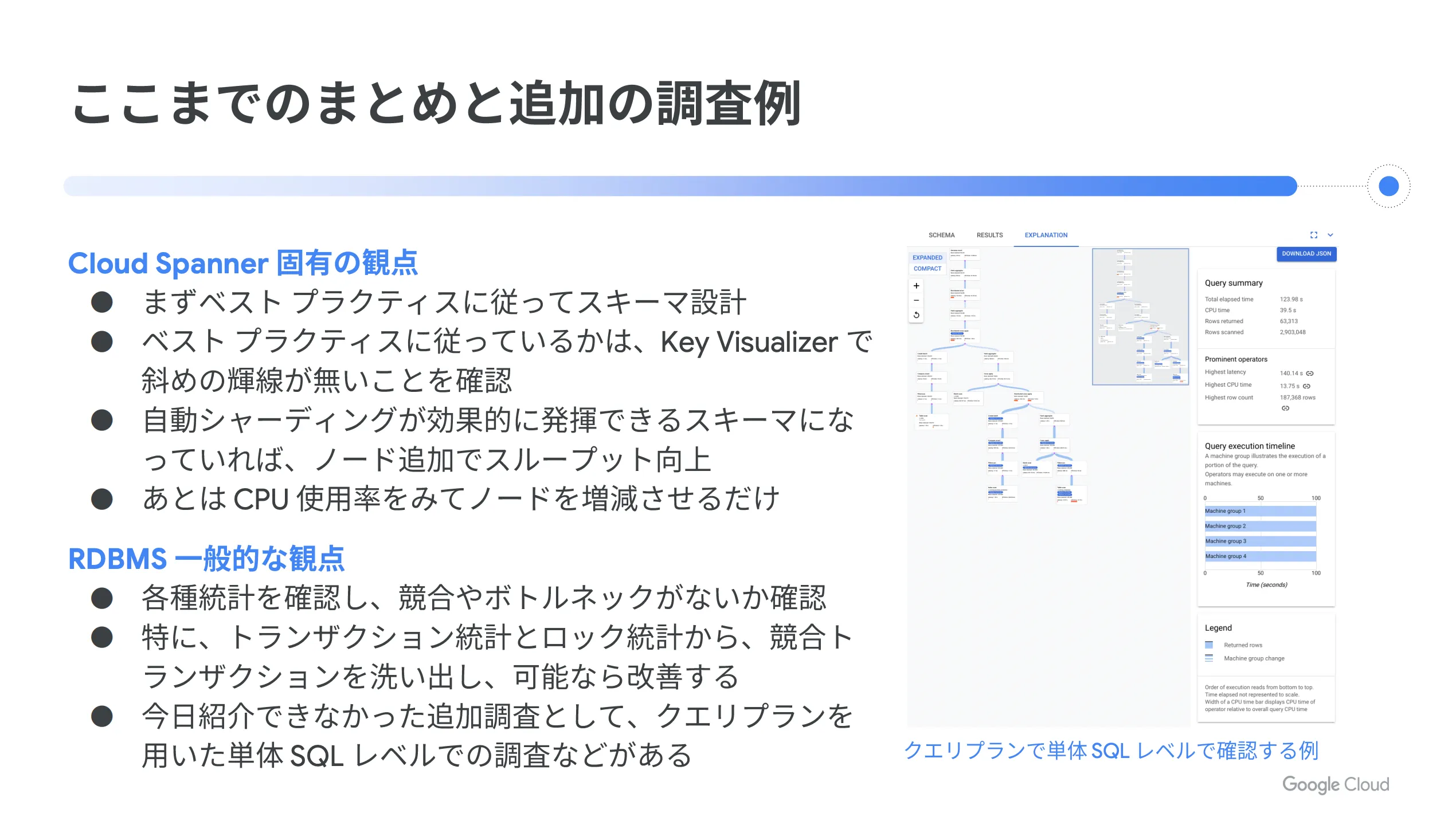
以下、記事の内容をまとめます。 Cloud Spanner 特有の観点と RDBMS の一般的な観点の2つに分けて記載していますので、改めて大切なポイントを確認しておいてください。
今回ご紹介したように、ポイントを押さえて正しい手順で作業を進めることで、 Cloud Spanner で性能調査を実施することが可能になります。記事内容を参考にして、試してみてはいかがでしょうか?
G-genは、Google Cloud のプレミアパートナーとして Google Cloud / Google Workspace の請求代行、システム構築から運用、生成 AI の導入に至るまで、企業のより良いクラウド活用に向けて伴走支援いたします。
関連記事


Contactお問い合わせ

Google Cloud / Google Workspace導入に関するお問い合わせ