LLM (大規模言語モデル)の仕組みとは?生成 AI との違いや活用事例などを一挙に紹介!
- LLM
- 大規模言語モデル
- 生成 AI

LLM (大規模言語モデル)とは?
LLM は「 Large language Models 」の略であり、日本語では「大規模言語モデル」と呼ばれています。大規模言語モデルという名前の通り、 LLM は非常に大規模なデータをもとに学習を行います。
具体的な学習データの例としては、 Web 上のコーパス(自然言語の文章・使い方などを広く収集し、コンピューターで検索できるように整理されたデータベース)や書籍、ニュース記事、会話ログなどが挙げられます。
昨今、 LLM の活用シーンは多岐にわたり、
- 情報検索の精度向上
- テキストの自動要約
- 会話エージェントの開発
- 翻訳の支援
など、あらゆる場面で LLM の活用が進んでいます。
この他にも、医学・法律分野における文書作成のサポートなど、専門知識が求められる特定領域への応用も期待されており、 LLM は日常生活やビジネスにおいて、大きな影響を与える技術の一つであると言えるでしょう。
LLM (大規模言語モデル)の仕組み
前述した通り、 LLM (大規模言語モデル)は膨大なテキストデータをもとに学習し、それらの学習データと人間によるインプットを掛け合わせて、自然言語の生成・要約などを行う深層学習モデルです。
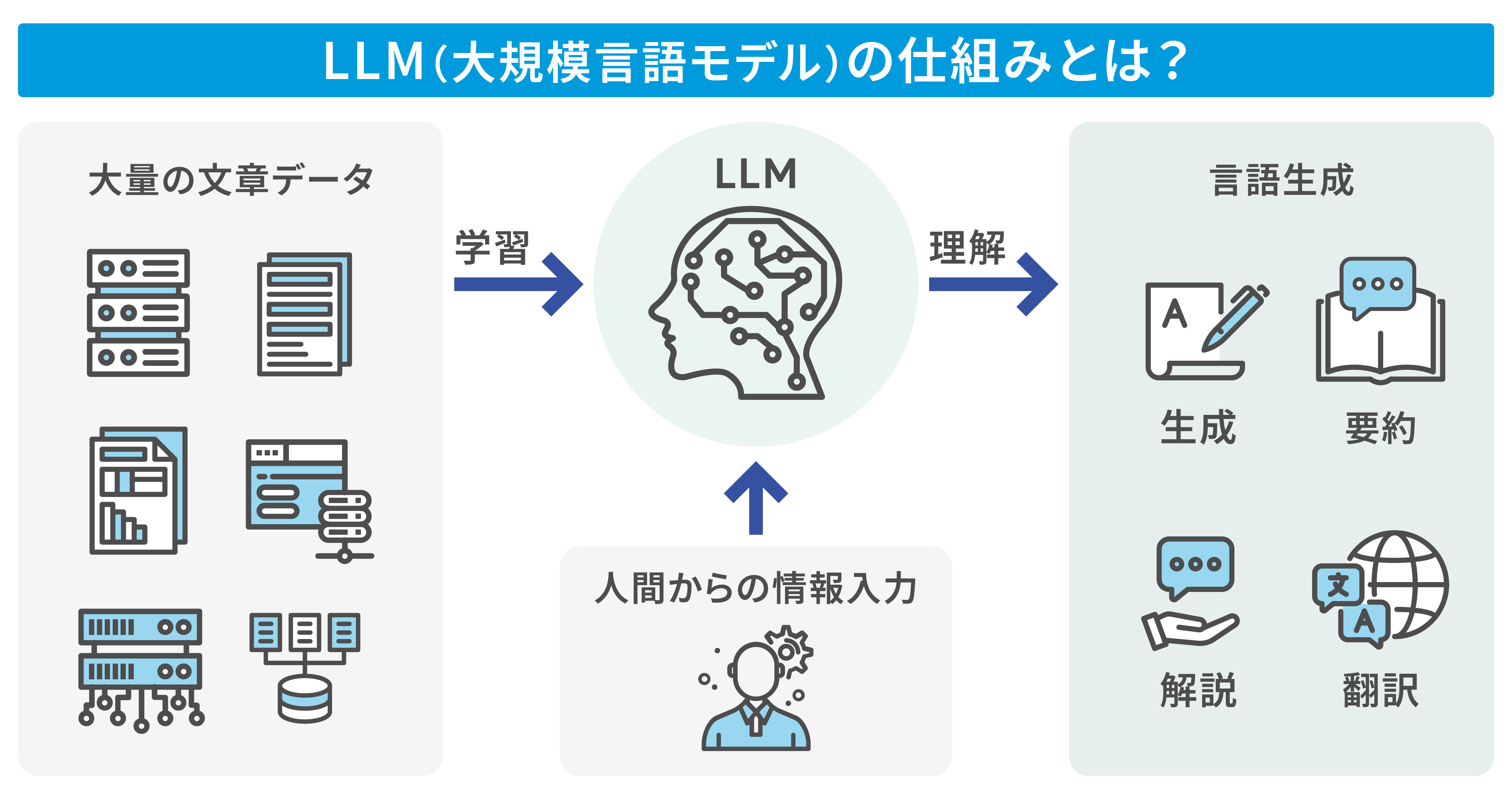
ここからは、
- 学習方法
- アーキテクチャ
- パラメータ
の 3 つの観点から、 LLM の仕組みについて解説します。
学習方法
LLM (大規模言語モデル)の学習方法における大きな特徴として、膨大な量のテキストデータをもとに学習する点が挙げられます。例えば、 Web 上の記事や書籍、ニュースなど、多種多様なソースから収集したテキストデータを利用してインプットを行います。
LLM はこれらのデータから言語のパターンや意味を理解し、次にどのような単語・言葉を置くのが適切なのかを予測することで、まるで人間のような自然な文章を生成できます。
アーキテクチャ
通常、 LLM (大規模言語モデル)のアーキテクチャは、次の 3 つの層に分かれていることが一般的です。
- 入力層
- 中間層
- 出力層
はじめに、入力層はテキストデータが最初に入力される場所であり、文章や質問文などが供給されます。次に、中間層でテキストデータから特徴量が抽出された後、出力層で言語の構文・意味を理解するための複雑な計算が行われます。
具体的な処理の流れとしては、ユーザーが入力したテキストデータが入力層へ入力された後、その内容をもとに AI が中間層でデータの特徴・変数などを分析します。そして、出力層での複雑な計算処理を経て、人間が理解しやすい形のアウトプットを返してくれるわけです。
このように、 LLM のアーキテクチャは 3 層構造になっており、それぞれの層が明確な役割を持って機能しています。 LLM が自然言語の生成・要約などを実現できる裏側には、上記のような仕組みが存在することを理解しておきましょう。
パラメータ
パラメータとは、モデルが学習によって調整する変数のことであり、 LLM (大規模言語モデル)では様々なパラメータが用いられています。例えば、ニューラルネットワークの重みやバイアスなどが LLM におけるパラメータの一例として挙げられます。
ニューラルネットワークの重みとは、ニューラルネットワーク内でノード間の接続の強さを示す指標です。入力データがノードを通過する際に、この重みがデータに掛け合わされますが、重みが大きいほど、その接続が持つ重要性は高くなり、逆に重みが小さいほど重要性は低くなります。そして、この重みを最適化することで、 AI から正しい出力結果を得られるようになります。
また、バイアスはノードの閾値(しきい値)を調整するためのパラメータです。入力データがバイアスで設定された一定の条件を満たした場合、ノードは出力を生成します。そのため、モデルが入力データに対して柔軟に反応するためには、このバイアスが重要なポイントだと言えます。
なお、 LLM 特有のパラメータとしては、注意機構の重みが挙げられます。注意機構の重みとは、各単語が他の単語とどれだけ関連しているかを計算し、その関連度合いに基づいて重みを割り当てるものです。高い関連度を持つ単語には高い重みが与えられ、低い関連度を持つ単語には低い重みが与えられます。これにより、 LLM は重要な情報をより効果的に抽出し、理解することが可能になります。
例えば、「犬が公園で遊んでいる」という文章があるとしましょう。注意機構はこの文を処理する際に、「犬」や「遊んでいる」といった単語に重点を置き、注意機構の重みが「犬」や「遊んでいる」などの単語に対して高く設定されます。これにより、 LLM はこれらの単語が文の意味を理解するうえで重要であると認識するのです。
そして、 LLM のように膨大な学習データを扱うモデルでは、これらのパラメータを適切に管理することが求められます。適切な重み・バイアスの調整により、モデルが入力データをより正確に解釈できるようになり、適切な応答を生成する能力が高まります。
そのため、大規模モデルにおいては、パラメータの初期化や更新、保存、最適化など、パラメータの管理が成否を分ける重要なポイントであることを理解しておきましょう。
LLM (大規模言語モデル)のトレーニングプロセス
次に、 LLM (大規模言語モデル)のトレーニングプロセスについて解説します。どのような手順でトレーニングを実施するのか、具体的な流れを理解しておきましょう。
トレーニングデータの準備
LLM (大規模言語モデル)のトレーニングを行うためには、膨大な量のテキストデータが求められます。主なソースとしては、 Web 上の大量の記事や書籍、ニュース、会話ログなどが使用されることが一般的であり、これらのデータは言語パターンの学習やモデルの構築に必要不可欠です。
また、データを準備する際には、テキストのクリーニング(不要な記号・ HTML タグの削除)やトークン化(単語・文の分割)などを実施することが重要なポイントです。これにより、モデルが効果的に学習できるようになり、高品質な LLM を構築できます。
トレーニングの手順とアルゴリズム
LLM (大規模言語モデル)のトレーニングでは、主に深層学習のアルゴリズムが使用されています。最も一般的なのは「 Transformer アーキテクチャ」を採用したモデルであり、これは自己注意機構(モデルが入力データ内の重要な部分に注意を向ける仕組み)を活用して文脈を理解し、長い文章を効率的に処理するためのアーキテクチャです。
具体的なトレーニング手順としては、はじめにデータをミニバッチ(小さなデータの塊)に分割して、モデルに供給します。次に、各バッチのデータを使ってモデルのパラメータを更新した後、バックプロパゲーション(ネットワークの出力と正解ラベルとの誤差からパラメータを修正する手法)により、パラメータを適切な値に調整します。
ハイパーパラメータの設定
ハイパーパラメータとは、 LLM (大規模言語モデル)のトレーニングプロセス中に手動で設定しなければならないパラメータのことです。ハイパーパラメータの例としては、学習率やバッチサイズ、エポック数(トレーニングデータを何回使用するか)などが該当します。
ハイパーパラメータの設定は、モデルの性能と収束速度に大きな影響を与えるため、慎重に作業を進める必要があります。なお、これらのハイパーパラメータは、実験と反復を通じて徐々に最適化されていくことが一般的です。
トレーニングの最適化技法
LLM (大規模言語モデル)のトレーニングを行う際には、最適化技法が重要なポイントになります。最も一般的な最適化アルゴリズムとしては、確率的勾配降下法(モデルのパラメータを調整して訓練データに適合させる手法)が挙げられます。
また、近年では学習率のスケジューリングやウォームアップ(学習の初期段階で学習率をゆっくり上げる手法)、勾配のクリッピング(大きすぎる勾配を制限する手法)なども広く使用されており、これらの技法はトレーニングの安定性・収束性を向上させるのに役立ちます。
このように、 LLM のトレーニングプロセスは、データの準備からモデルの最適化まで、多くの段階で細かい調整が求められます。適切なデータの処理や効果的なアルゴリズムの選択、適切なハイパーパラメータの調整、最適化技法の適用など、これらの要素をバランスよく調整することが、高度な言語理解モデルの構築に繋がります。
LLM (大規模言語モデル)の性能評価はどうするの?
LLM (大規模言語モデル)の性能評価は、そのモデルがどれだけ正確に言語理解・予測を行えるかを評価するための重要なプロセスです。
LLM の性能評価を行う際には、はじめに適切なテストデータセットを準備する必要があります。これは、モデルが訓練されたデータとは異なる(かつ同様の性質を持つ)データセットであり、文章の理解や文法の正確性、意味の理解などをカバーするデータが含まれます。
次に、 LLM の性能を数値化するための評価指標を選択します。なお、一般的な評価指標としては、モデルが正しく予想できた割合を示す「精度」や、モデルの予測と実際の値との差分を示す「損失関数」などが該当しますが、タスク特有の指標も重要です。例えば、機械翻訳では BLEU スコア、要約タスクでは ROUGE スコアを使用します。また、GLUE や SuperGLUE 、JGLUE などといった標準化されたベンチマークテストも活用します。
実際に評価を行うプロセスにおいては、テストデータセットを用いて LLM が文章・単語の予測などを生成し、その出力結果と正解ラベルを比較して、上述した評価指標に基づいてモデルの評価を実施します。
最後に、評価結果を分析してモデルの課題・改善点を抽出します。そして、エラーの種類や頻度を把握し、それらをもとにモデル設計やパラメータ調整を行うことで、モデルの性能を向上させることができます。
このように、適切な評価指標を選択し、体系的な評価プロセスを実行することで、モデルの強み・課題の理解やさらなる改善に繋がります。
LLM (大規模言語モデル)と機械学習・生成 AI との違い
LLM (大規模言語モデル)と混同しやすい言葉として、機械学習や生成 AI が挙げられます。これらは AI に関連するという意味では共通していますが、実際には異なるものとして明確に区別されています。
本章では、 LLM と生成 AI ・機械学習との違いをわかりやすく解説します。
LLM (大規模言語モデル)と機械学習の違い
まずは、 LLM (大規模言語モデル)と機械学習との違いをご説明します。
機械学習とは、コンピュータプログラムがデータから学習し、パターンやルールを抽出して問題を解決する技術の総称です。機械学習の対応範囲は広く、画像認識や音声認識、自然言語処理など、多岐にわたります。
また、機械学習の代表的な手法の一つとしてディープラーニングがあり、これは膨大なデータを AI に学習させることで共通点を自動で抽出し、状況に応じた柔軟な判断を AI 自身が行えるように強化するものです。つまり、機械学習の中にディープラーニングが内包されているとイメージするのがわかりやすいでしょう。
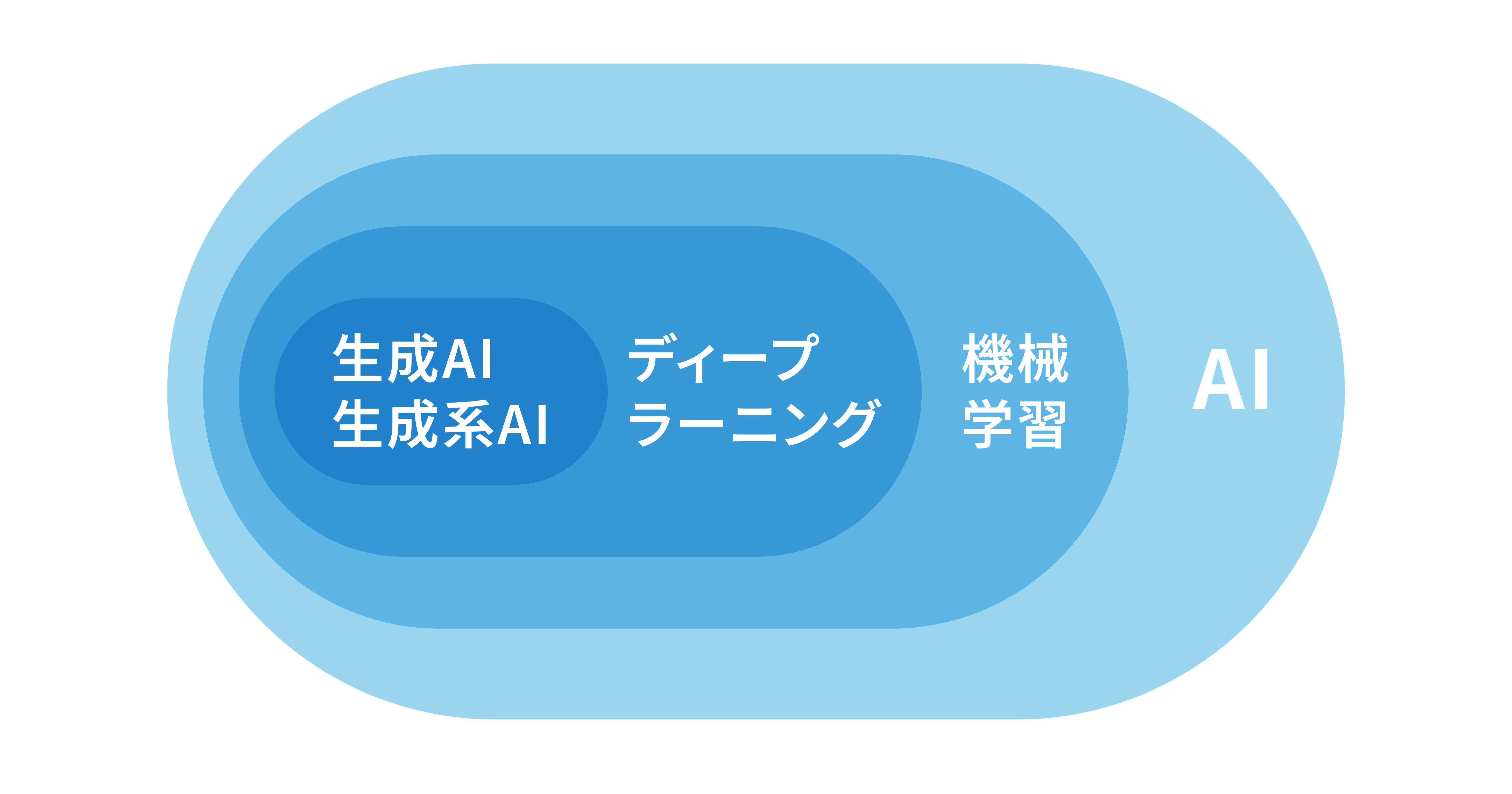
そして、 LLM (大規模言語モデル)は自然言語処理に特化したディープラーニングモデルの一種であるため、機械学習やディープラーニングと比較すれば、 LLM はより小さい範囲に対応しているモデルだと言えます。
LLM (大規模言語モデル)と生成 AI の違い
次に、 LLM (大規模言語モデル)と生成 AI との違いをご説明します。
LLM ・生成 AI はともに文章を自動生成することが可能ですが、生成 AI が作成するものは文章(テキスト)だけではなく、画像や音声など、様々なコンテンツを自動で生成できます。
その点、 LLM は自然言語処理に特化したモデルであるため、生成できるのはテキストのみになります。このように、 LLM は生成 AI という大きなカテゴリーに内包されている特化型のモデルであると言えるでしょう。
なお、生成 AI に関しては以下の記事で詳しく解説しています。
関連記事:生成 AI の仕組みやメリットとは?活用時のポイントや具体的なサービス例まで一挙にご紹介!
代表的な LLM (大規模言語モデル)
本章では、代表的な LLM (大規模言語モデル)を 4 つご紹介します。どのような LLM があるのか、各モデルの概要を理解しておきましょう。
Gemini
Gemini は Google が開発した生成 AI モデルであり、マルチモーダル(複数の異なる情報源から情報を収集し、統合して処理する仕組み)な情報処理に特化している点が大きな特徴です。テキストだけではなく、画像や音声などの複数ソースを統合的に扱うことが可能なため、情報源が多岐にわたる場合は Gemini が有効な選択肢になると言えるでしょう。
GPT-4
GPT-4 は OpenAI によって開発された LLM (大規模言語モデル)の最新バージョンです。 GPT シリーズは自然言語処理の分野で非常に影響力のあるモデルであり、文脈の理解や文章生成に優れている点が大きな特徴となっています。また、大規模な汎用テキストデータセットを使用して事前訓練されているため、多様な自然言語処理タスクに対応可能です。
LlaMA
LlaMA ( Large Language Model Meta AI )は、Meta AI が開発した先進的な LLM (大規模言語モデル)です。その主な特徴は、効率的なアーキテクチャにあります。より少ないパラメータ数で高い性能を実現し、計算リソースを効率的に利用できます。LlaMA は 7B、13B、33B、65B など、異なるパラメータサイズのモデルが提供されており、用途に応じて選択可能です。
※米国時間2024年4月18日に公開された「 Llama 3 」では、パラメーター数が80億と700億の2つのモデルが用意されています。
Meta AI は研究目的で LlaMA をオープンソース化しました。これにより、幅広い研究者やデベロッパーがモデルにアクセスし、改良を加えられるようになっています。
テキスト生成、質問応答、要約、翻訳など、様々な自然言語処理タスクに対応できます。また、特定のタスクや領域に特化させるためのファインチューニングが比較的容易です。
Claude
Claude は、Anthropic 社が開発した先進的な LLM (大規模言語モデル)です。その最大の特徴は、安全性と倫理性を重視した設計にあります。「 Constitutional AI 」という独自のアプローチを採用し、AIシステムに倫理的な原則を組み込むことを目指しています。Claude は有害なコンテンツの生成を避け、バイアスを軽減するよう訓練されています。
多様なタスクに対応可能で、自然言語処理、質問応答、文章生成、コード解析などを行えます。長い文脈や複雑な情報を理解し、適切な応答を生成する能力も備えています。カスタマーサポート、コンテンツ生成、研究補助、教育支援など、様々な分野での活用が期待されています。
代表的な LLM の比較
以下、今回ご紹介した 5 つの LLM モデルを表でまとめます。
|
モデル名 |
提供会社 |
特徴・強み |
|
Gemini |
|
・マルチモーダル対応 ・複数ソースを統合的に利用可能 |
|
GPT-4 |
OpenAI |
・高精度な文脈理解や文章生成 ・多様な自然言語処理タスクへの対応 |
|
LlaMA |
Meta AI |
・より少ないパラメータ数で高い性能 ・高い汎化性(異なる対象から共通点を抽出できる) |
|
Claude |
Anthropic |
・長い文章や複雑な文脈の理解 ・文脈に基づいた次の単語・文章の予測 |
このように、一口に LLM と言っても、その種類は多岐にわたります。モデルごとに強みや特徴が異なるため、それぞれの違いを理解して、自社に適したものを選択することが重要なポイントになります。
LLM (大規模言語モデル)でできること
ここまで、 LLM (大規模言語モデル)について詳しく解説してきましたが、 LLM を活用することで、具体的にどのようなことを実現できるのでしょうか?本章では、 LLM でできることについて解説します。
文章の作成・要約・分類
LLM (大規模言語モデル)を使えば、文章の作成・要約・分類を効率的に行うことができます。 LLM は与えられた文脈から自然な文章を生成できるため、記事やレポート、ストーリーなどの文章を自動的に作成してくれます。
また、長い文章を要約することも可能なため、テキストデータから重要な情報のみを抽出し、簡潔にまとめることができます。さらに、テキストのカテゴリー分けや感情分析など、文章の意図や内容を分類したい時にも大きく役立つでしょう。
質問に対する回答
LLM (大規模言語モデル)は、特定の質問に対して適切な情報を抽出し、簡潔かつ正確な回答を生成することができます。まるで人間が作成したような自然な文章を作成してくれるため、情報検索や対話システム、カスタマーサポート窓口でのチャット対応など、幅広いシーンでの活用が可能になります。
情報の検索・抽出
LLM (大規模言語モデル)は大規模なテキストデータベースから情報を検索し、必要なデータを抽出する能力を持っています。例えば、特定のトピックスに関する記事・文書を探し出し、その中から重要な情報を抜き出すような使い方が考えられます。これにより、情報収集や分析作業を効率化できるため、人間はより生産性の高い仕事にリソースを集中できるようになります。
プログラミングコードのチェック
LLM (大規模言語モデル)はプログラミング言語に関する文脈理解も行えるため、プログラミングコードのチェックや修正支援にも活用できます。例えば、コードのエラーを検出して適切な修正案を提案するなど、プログラマーにとって貴重な支援ツールとして利用可能です。昨今、エンジニアや IT 人材の不足が続いていますが、 LLM を活用することで、コードチェックを効率的に進められるでしょう。
翻訳
LLM (大規模言語モデル)は与えられた文章を他の言語に自動翻訳できるため、異なる言語間での翻訳作業にも有効に活用できます。これにより、国際的なコミュニケーションや多言語環境での情報アクセスがスムーズになるほか、これまで翻訳要員として雇用していた人材の人件費削減にも直結します。
LLM (大規模言語モデル)の活用事例
某 IT 企業では、日常業務の中で LLM を積極的に活用しています。
例えば、従来は会議の議事録を人間が手動で作成していましたが、 Zoom の文字起こし機能で抽出したテキストデータを LLM と組み合わせることで、要点のみを拾って高精度かつ簡潔な議事録の作成を自動化しています。
また、同社はカスタマーサポート向けの IT ツールを導入しており、そのツールには業種ごとの業界課題や市場トレンドなどのデータが格納されていますが、テキスト量が膨大であり、人間が理解するには文章が長すぎる点が大きな課題となっていました。そこで、これらのテキスト情報を LLM で要約し、重要なポイントを簡潔にまとめることで、顧客に対する提案準備を効率化することに成功したのです。
さらに、顧客の問い合わせに対して LLM が自動で回答を作成・返答してくれる仕組みを構築しているほか、顧客が入力したテキスト情報から感情を分析し、どのような顧客がポジティブ(ネガティブ)な印象を持っているのかをデータで見える化しています。
このように、様々な業務シーンで LLM を活用し、組織全体の生産性向上を実現している好事例となっています。
LLM (大規模言語モデル)を利用する際の注意点
最後に、 LLM (大規模言語モデル)を利用する際の注意点について解説します。
LLM は大規模なテキストデータセットをもとに学習を行うため、訓練用のデータに自社の機密情報が含まれる場合は、それらを安全に保護する必要があります。情報漏洩リスクを低減するためには、匿名化されたデータを使用したり、機密情報を含まないデータセットを選定したりするなど、セキュリティ観点から様々な工夫を行うことが大切です。
また、 LLM を利用する際には、知的財産権や著作権などの権利侵害のリスクも考慮しなければなりません。特に、テキストの生成や要約、翻訳などを行う場合には、原著作者の権利を侵害していないか、 LLM のアウトプットを慎重に評価する必要があります。
このように、 LLM は利便性が高い一方で、利用時に注意すべきポイントもいくつか存在します。自社の機密データを守り、権利侵害を避けるためには、適切なセキュリティ対策と法的なコンプライアンスを実施するなど、安全かつ法的遵守を意識した責任ある LLM 利用を心掛けることが大切です。
まとめ
本記事では、 LLM (大規模言語モデル) の概要や仕組みに加えて、活用事例や利用時の注意点など、あらゆる観点から一挙にご説明しました。
企業が LLM を活用することで、文章作成や情報検索、プログラミングコードのチェックなど、様々な業務を効率化できます。この記事を読み返して、 LLM の仕組みや代表的なモデルなど、重要なポイントを理解しておきましょう。
G-genは、Google Cloud のプレミアパートナーとして Google Cloud / Google Workspace の請求代行、システム構築から運用、生成 AI の導入に至るまで、企業のより良いクラウド活用に向けて伴走支援いたします。
サービスを見る
サービス資料をダウンロードする
無料で相談する
本記事を参考にして、 LLM の導入を検討してみてはいかがでしょうか?
関連記事


Contactお問い合わせ

Google Cloud / Google Workspace導入に関するお問い合わせ