Google Cloudの新DBMS、AlloyDB for PostgreSQLを触ってみた Vol.6 (最終回)
- AlloyDB
- AlloyDB for PostgreSQL
- DBMS
- Google Cloud
- PostgreSQL

目次
まえがき
こんにちは。開発部の高井(Peacock)です。
今回で最終回ということで、データ分析用途としての応用編を紹介して締めくくりにします。
概要
第1回、第2回、第5回などで取り上げている、イギリスの不動産取引データについて2パターンの集計を Pandas の pandas.read_sql() メソッドで実施、グラフ描画ライブラリのPlotlyを用いて表示してみます。
- 2013年1月1日以降のロンドン市における、物件種別(一戸建て・半戸建て... など)毎の月毎の平均価格推移
- 2000年のロンドン市における、各地域毎に一番高価な通りの物件価格(上位25位)
そして、これらのタスクについてカラムナーエンジンの有効化有無で優位性があるかも確認します。
実際のコード
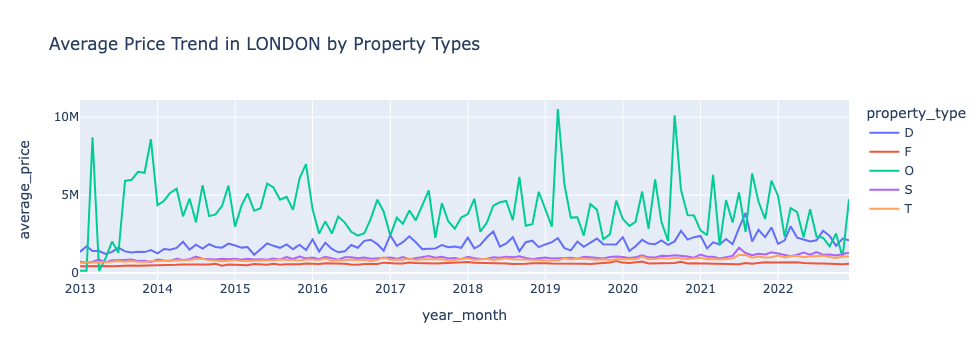
ケース1: 2013年1月1日以降のロンドン市における、物件種別(一戸建て・半戸建て... など)毎の月毎の平均価格推移
集計SQLクエリ:
SELECT EXTRACT(YEAR FROM transfer_date) AS year,
EXTRACT(MONTH FROM transfer_date) AS month,
property_type,
ROUND(AVG(price)::numeric, 2) AS average_price
FROM land_registry_price_paid_uk
WHERE city = 'LONDON' AND transfer_date >= '2013-01-01'
GROUP BY year, month, property_type
ORDER BY year, month;Python (Pandas)での集計:
df1 = pd.read_sql(q1, engine)
# 年月の型変換
df1["year_month"] = df1["year"].astype(int).astype(str) + "-" + df1["month"].astype(int).astype(str)
# グラフ描画
fig1 = px.line(df1, x='year_month', y='average_price', color='property_type',
title="Average Price Trend in LONDON by Property Types")このようなグラフが描画できます。
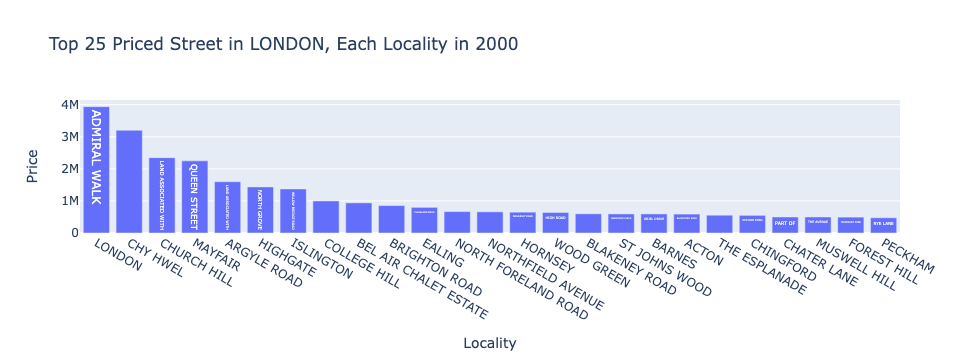
ケース2: 2000年のロンドン市における、各地域毎に一番高価な通りの物件価格(上位25位)
集計SQLクエリ:
WITH maxprices AS (SELECT locality,
MAX(price) AS max_price
FROM land_registry_price_paid_uk
WHERE EXTRACT(YEAR FROM transfer_date) = 2000
AND city = 'LONDON'
GROUP BY locality)
SELECT t.locality,
t.street,
t.price AS max_price
FROM land_registry_price_paid_uk t
JOIN maxprices m ON t.locality = m.locality AND t.price = m.max_price
WHERE EXTRACT(YEAR FROM t.transfer_date) = 2000Python (Pandas)での集計:
df2 = pd.read_sql(q2, engine1)
df2 = df2.sort_values(by="max_price", ascending=False).head(25)
# グラフ描画
fig2 = px.bar(df2, x="locality", y="max_price",
title="Top 25 Priced Street in LONDON, Each Locality in 2000",
text="street", labels={"max_price": "Price"})
fig2.update_layout(showlegend=False, xaxis_title="Locality")出力されたグラフ:
カラムナーエンジン有効状態でのパフォーマンス差
上記コードにおいてpandas.read_sql を用いてPandas DataFrameを作成する部分で有意差があるか比較してみました。
結果は以下のようになりました。例によって実データは掲載できないため、およその相対数値を表示します。
- ケース1: カラムナーエンジン有効状態のインスタンスが約3.3倍高速
- ケース2: カラムナーエンジン有効状態のインスタンスが約1.2倍高速
どちらのケースにおいてもカラムナーエンジンが十分に有効そうです。
まとめ
最終回、第6回としてPythonでPandasとPlotlyを用いて簡単なデータ分析の例を取り上げてみました。
特にカラムナーエンジンを有効にすると、データ分析のバックエンドとしても申し分なさそうな性能でした。
今回は割愛しましたが、第2回の読み取りプールも組み合わせるともっと良さそうです。
連載の終わりに
今回で今年(2023年)4月の第1回から続けてきたAlloyDB for Postgresの連載を締めさせて頂きます。
本連載を通して、少しでもAlloyDB for Postgresの情報を伝えることができたのではないかと思います。
そもそもRDBMSの知識も乏しい筆者でしたが、ここまで読んで頂いた方に感謝申し上げます。
今後も弊社テックブログでの執筆を(細々とですが)続けたいと思っておりますので、今後ともよろしくお願いします!
関連記事
-
 Google Cloudの新DBMS、AlloyDB for PostgreSQLを触ってみた Vol.52023.08.21
Google Cloudの新DBMS、AlloyDB for PostgreSQLを触ってみた Vol.52023.08.21- AlloyDB
- AlloyDB for PostgreSQL
- DBMS
- Google Cloud
- PostgreSQL
-
 Google Cloudの新DBMS、AlloyDB for PostgreSQLを触ってみた Vol.32023.04.17
Google Cloudの新DBMS、AlloyDB for PostgreSQLを触ってみた Vol.32023.04.17- AlloyDB
- AlloyDB for PostgreSQL
- DBMS
- Google Cloud
-
 Google Cloudの新DBMS、AlloyDB for PostgreSQLを触ってみた Vol.22023.03.29
Google Cloudの新DBMS、AlloyDB for PostgreSQLを触ってみた Vol.22023.03.29- AlloyDB
- AlloyDB for PostgreSQL
- DBMS
- PostgreSQL
Contactお問い合わせ

Google Cloud / Google Workspace導入に関するお問い合わせ