機械学習の勉強歴が半年の初心者が、 Kaggle で銅メダルを取得した話
- deep-learning
- kaggle
- 機械学習
- 自然言語処理

R&D 事業部所属のデータサイエンティスト・機械学習エンジニア見習い(機械学習の勉強歴 約半年)が、 Kaggle の銅メダル*を獲得した手法を、解説していきます。
* 順位は4551人中356位でした
目次
想定する読者
- Kaggle ? なにそれ、おいしいの?
- Kaggle の順位が中間以下で、上位入賞するコツを知りたい
- 機械学習に多少でも触れたことはある
上記に合う人が対象です。 Kaggle 上位ランカー、普段からデータ分析業務に従事されている方にはちょっと物足りないかもしれません。
Kaggle とは
Kaggle (カグル)は、世界中の機械学習・データサイエンスに携わっている人が、データ分析力や機械学習のモデリング力を競い合うコンペティションまたはそのプラットフォームです。最近では、国内でもそれなりに知名度が上がり、日本勢の上位入賞者もちらほら見かけます。
自分のデータ分析力がどのレベルにあるのか、客観的に知ることができるので、興味のある方はぜひ参加してみてください。
Toxic Comment Classification Challenge
ここからは、筆者が銅メダルを獲得したコンテストについて説明します。
Toxic Comment Classification Challenge は、 Alphabet 傘下の Jigsaw が主催する、荒らしコメントを分類するコンペティションです*。 ( *数週間前にこのコンペティションは終了しました。)
Wikipedia の編集議論板で書き込まれた約15万のコメントを1つずつ、“荒らし( toxic )”、“ひどい荒らし ( severe toxic )”、“卑猥( obscene )”、“脅迫( threat )”、“侮辱( insult )”、“個人攻撃( identity_hate )”であるか分類します(下図)。

コンペティションの参加者は、上の6種類をどれだけうまく分類できるかを競い合います。今回は、これらをうまく分類できている度合い(スコア)を評価するために、 Area under the curve ( AUC )という指標が用いられています。本記事では AUC について解説いたしませんが、その内容を知りたい方はここが参考になります。
スコアは、以下の流れで採点されます。
- 主催者から与えられた訓練データによってモデルを学習させる
- 1.で学習済みのモデルからテストデータを入力して推論を行い、出力データを作成する
- 作成した推論結果をコンペティションの提出ページにアップロードすることで、 AUC が算出される
ここで採点されたスコアに基づき、 Leaderboard と呼ばれる表に参加者の順位が表示されます。 Learderboard には、 Public Leaderboard と Private Leaderboard の2種類があります。
Public は、コンペティション開催中に表示される順位表であり、テストデータの25%のみから算出されたスコアに基づいて、順位付けされます。 Private は、コンペティション終了後に表示される最終順位であり、残り75%のスコアに基づいて、順位付されます。最終結果は、 Private のスコアが採用されます。
参加者の間では、 Leaderboard に表示されているスコアを" LB "という略語で表現しています。参加者は、この LB スコアと、ローカルのデータ分析環境で算出された交差検証( Cross validation, CV )のスコアを判断材料にして、最終的に投稿する出力データを選定します。
Kernels の手法
Kernels とは、コンペティション参加者が自分のアイディアやソースコードを他の参加者と共有する場です。 Kernels では、機械学習のモデリングは勿論のこと、データ観察方法やデータの前処理・特徴抽出のノウハウがハイレベルに議論されているので、これらを読むだけで最先端のデータ分析技術をキャッチアップできます。
本項では、 Toxic コンペティションで議論の中心になった手法を紹介します。
性能の良いモデルを考える
できるだけ上手く分類できるようなモデル(分類器)を考えます。所謂、正攻法でありコンペティションの意義に合った素直なアプローチです。
以下に、議論されていた手法とその参考文献を列挙します。(ここでは、各種手法に深入りしません。詳細はリンク先の参考文献をご覧ください。)
- GRU ( Gated Recurrent Unit ), GRU + CapsuleNet
- LSTM ( Long Short-Term Memory )
- Bi-directional RNN ( GRU, LSTM )
- CNN ( Convolutional Neural Network )
- ↑の Deep Learning 手法を適当に組み合わせる
- Logistic regression
- Naive-Bayes
- H2O Word2Vec
- XGBoost または LightGBM (決定木( Decision Tree )ベースのアンサンブル学習)
- Extra-trees ( extremely randomized trees )
- Wordbatch
CapsuleNet といった最新の手法から、 Logistic Regression といった古典的な手法まで、多岐に渡るモデルが検証されていました。スコア( LB )は、アンサンブル学習 > Deep Learning 手法の組み合わせ > GRU, CNN > LSTM > その他 という順で、良好に出ていました。コンペティション残り1~2週間ではだいたいのアプローチは出尽くしていたような気がします。
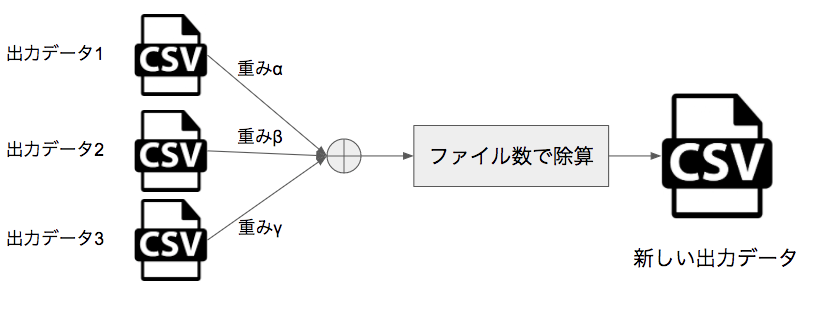
出力データ同士をブレンドする
モデルから推論された出力データを、適当な配分で足し合わせて、出力データ数で割ることで、新しい出力データを作成する方法です(下図)。つまり、各種手法で求められた推論値のいいとこ取りをしようとする発想です。できるだけ異なる手法同士を組み合わせることで、スコア上昇がしやすくなるようです。(詳細はこちらをご覧ください。)
このブレンディングですが、 Kaggle 参加者の間で物議を醸していました。 Kernels で投稿された成果物のタダ乗りに近い行為が、可能になってしまうからです。 Kernels では、モデルを公開した人が、その出力データを添付できるのですが、その出力データを適当に組み合わせてブレンドすることで、簡単に上位層のスコアに食い込めてしまうのです。実際、モデリングの議論が出尽くした残り1~2週間では、 Kernels でブレンド合戦が繰り広げられ、 Public LB ではスコアが僅か0.0002の範囲(0.9871~0.9868)に、約380人(223位~605位)も食い込んでいました(下図)。全員が、 Kernels の出力データを使ったブレンドを行なっているとは思えませんが、相当数の参加者がこの方法に恩恵を受けたのではないかと思います。

Kernels を良心的で有意義な共有の場にするためにも、ブレンド手法をとるのであれば、少なくとも自分で学習させたモデルの出力データを使う、という配慮が必要かもしれません。
どうやって銅メダルを獲得したか
ここからは、筆者が取った解法を紹介します。
注目した視点は、入力データを改変する“前処理”と、他者が提案したモデルを良いとこ取りする“モデルの流用”です。筆者が、 Toxic コンペティションへ本格的に参加したのは開催終了日の2週間前でしたので、モデリングの議論はだいたい出尽くしている段階でした。また、最新のモデリング手法の理論を学び、それを使いこなすほどの時間は残されていませんでした。
そこで、自分でできそうなことは、モデリング以外の処理で他者と差をつけることと定め、次のような手法を考えました。
入力データの改変
クリーニング
与えられた入力データをそのまま利用するのではなく、学習の邪魔になりそうな文字列を改変・削除 します。
- 省略語の変換
- 例: won’t → will not, I’m → i am 等
- 絵文字の変換
- 例:
:)→ smile,:(→ sad 等
- 例:
- Emoji、特殊記号の除去
- 例: 😡→ (なし)、♨️→(なし)等
上記3種類を適用した結果、LBが上昇 しました(具体的な数値は覚えておりません)。しかし、これらの発想は典型的なものであり、恐らくこの部分では他者とあまり差が付かなかったかと思います。
- 大文字・小文字の扱い
Kernels では、大文字・小文字全てを小文字に統一する手法が主流でした。恐らく、英単語を学習済みワードベクトル (FastText, Glove 等)でタグ付けするときに、(大・小文字関係なく)“同じ単語は同じベクトルとして表現した方が良い性能が出る”と判断したからと推測します。
しかし、英語で大文字を羅列するということは、その “文を強調している” という重要な情報が含まれています(参考)。筆者は、この情報を特徴量として入れようと考え、次のようなルールを定めて大文字・小文字の変換処理を行いました。
- 単語に2文字以上大文字が含まれている場合は、大文字に変換する。
- 例: TOXICやToXiC → TOXIC
- 大文字が2文字未満の場合は、小文字に変換する
- 例: Toxicやtoxic → toxic
この手法を適用した結果、LBが若干上昇 しました。多少は効果があったようです。
非英語コメントの扱い
与えられた入力データを観察したところ、訓練データに体感1%、テストデータに体感5%の非英語テキスト(下図)が混ざっていました。非英語系テキスト が、ノイズとなっていそうなので、これらを全て英語に翻訳しました。翻訳のソースコードは、 Translation API の pythonクライアントライブラリ を利用して作成しました。

この手法を適用した結果、LBが上昇するどころか、若干下降 してしまいました。
入力データの水増し(時間切れ)
前項の翻訳手法を考えているうちに、“英語コメントを別の言語に翻訳して、さらに英語に再翻訳 すればデータの水増しができるのでは?”と考えました。
日本語→英語→日本語の例を示すと、
志摩さんは、冬場に一人でキャンプをするのが趣味です。
↓
Shima is a hobby to camp alone in the winter.
↓
志摩は冬に一人でキャンプする趣味です。
という感じになります。文章が破綻せずに、元の文章とは異なる文を生成できる ことを上手く利用しよう、という発想です。
しかし、この手法はコンペティション終了間際に思い付いたので、実際には検証できませんでした。
実は、この 再翻訳によるデータの水増しはとても有効な手法 であり、(後ほど紹介する)1位チームがこの手法で差をつけたと述べていました!これができていれば、銀メダルを狙えたので物凄く悔しいです。
他者のモデルを良いとこ取りする
Kernels で提案されていた各種 Deep Learning 手法を、並列に掛け合わせたらどうなるか、という検証を行いました。異なる手法から生成された出力データをブレンドすることで、LBが上昇するという知見から、“モデル同士を並列に組んでも効果があるのでは?” と考えました(下図)。(執筆者の調査不足で、このような手法が既に存在しているのかは分かりません。)
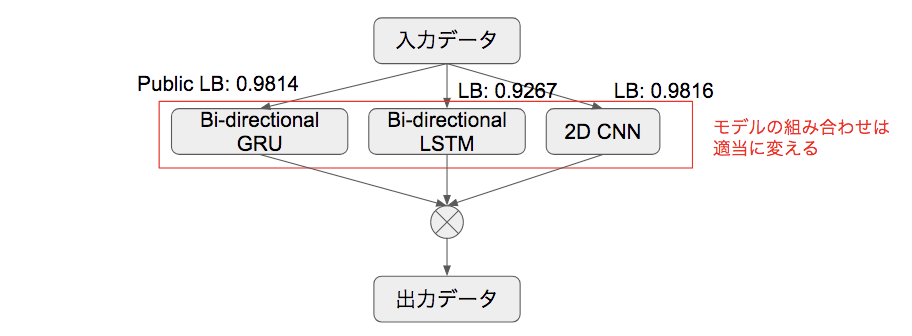
この手法を適用した結果、 Bi-directional GRU と 2DCNN の組み合わせが最良となり、Public LB が、個々のモデルと比較して 0.0007~0.0009ほど上昇 しました。
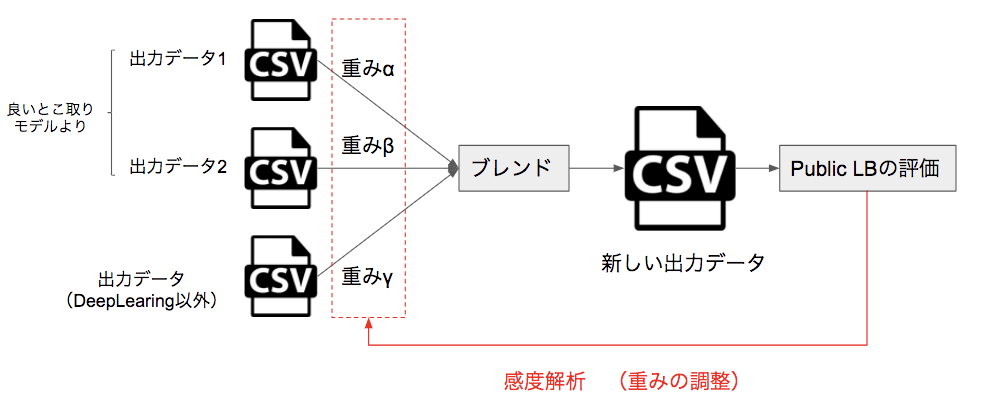
簡易的な感度解析によるブレンド最適化
最後に、良いとこ取り手法で生成した出力データと、 Deep Learning を用いないモデルの出力データを組み合わせて、ブレンドを行いました。単純にブレンドすると芸がないので、簡易的な感度解析(感度分析)によってLBの上昇を試みました(例 下図)。
簡易的な感度解析の手順は次の通りです。
- ランダムに重みの範囲(探索空間)を取り、新しい出力データを多数生成する
- 一番良いスコアをとるブレンドデータの重みを基準( Baseline )とする
- 重みのうち、“値が相対的に大きいものが、 LB スコアに貢献している”と仮定する
- 値が相対的に大きい重みを、0.5倍, 2倍に変化させる
- 4.で、スコアがさらに良くなった方に局所最適解が存在すると仮定する
- 局所最適解方向に、更に重みを大きく・小さくする
- LB スコアが上昇し終えたところが局所最適解の近傍であるとし、2~6で操作した重みをこれ以上動かさないようにする
- 他の重みを変化させて、さらに LB スコアの上昇を狙う
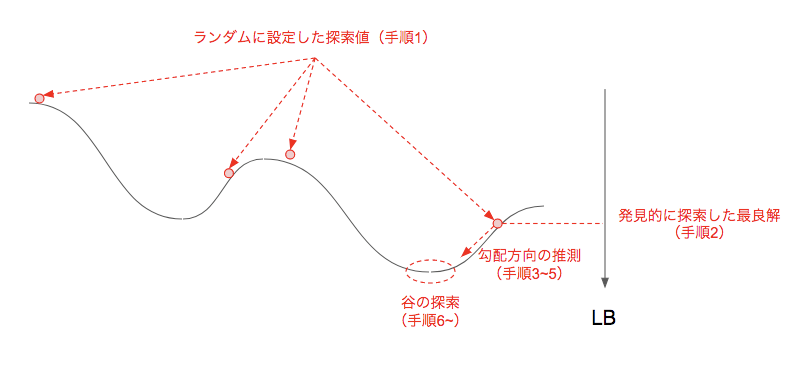
つまり、下図のように
発見的に LB の良好な解を探索(手順1, 2)→ LB を表現する関数の勾配方向を推測する(3~5)→ LB スコアの谷(局所最適解)になっていそうな重みの組み合わせを探索する(6~)
という流れで、できる限り LB を上昇させようという試みです。
1位の解法
Kaggle では、 discussion 掲示板で上位入賞者が自身の解法を投稿してくれる場合があります。 Toxic コンペでは、1位の人が解法を公開しているので、簡単に内容をみてみましょう。
- 学習済みモデルを色々変える
- Common Crawl, Wikipedia, Twitter に対して事前学習したワードベクトル( FastText, Glove )をすべて試したようです。( Public LB 0.9877)
- 英語の再翻訳
- 基本的なアイディアは前項で説明したものと変わらないです。英語→仏語→英語、英語→独語→英語、英語→西語→英語の3通りで検証し、テストデータの出力値は平均値を用いたようです。( Public LB 0.9877→ 0.9880)
- その他
- Pesuedo-labeling とアンサンブル学習によるスコア向上をとことん突き詰めていました。詳細はソース元を確認ください。( Public LB 0.9880→ 0.9890)
最上位の人は、天才的なアイディアを思いついているわけではなく、データ分析の経験者であれば思いつきそうなアイディアを丁寧に検証していた、という所が意外でした。また、モデルの改良ではなく前処理を重視していた点は、自分の着眼点がそこそこ良い線を行っていたことになるので、自信がつきました。そして、英語の再翻訳が大当たり だったことが嬉しかったのと同時に、これさえやっておけば銀メダルが……という後悔が若干残りました。
まとめ
今回、 Toxic コンペティションに参加して、
- データ分析の経験者であれば大概思いつきそうなアイディアを、一つ一つ丁寧に検証すれば、スコアは着実に上がる。
- Kernels を使えば、洗練されていないアイディアでも上位入賞は狙える
という感想を持ちました。つまり、 データ分析としてやるべきことをしっかり行えば、上位入賞どころか最上位も夢ではない と言えます!
おわりに
まずは、最後までお読みいただき、ありがとうございました!
機械学習初心者が Kaggle で銅メダル取った手法を振り返りましたが、いかがでしたでしょうか?本記事を読んだあなたが、“自分でも Kaggle で上位を狙えそう!” と自信を持っていただければ幸いです。
トップゲートでは “Kaggle 部” というサークルがあり、メンバーは積極的に Kaggle のコンペティションに参加し、ノウハウの共有やスコアの競い合いを行なっています。 Kaggle 部員になると、特典としてデータ分析で用いる高性能な Datalab GPU インスタンス環境や Cloud ML Engine, BigQuery などの GCP の環境を自由に使用できます! また、トップゲートには、 ** GCP を活用したデータ分析に強いエンジニアが所属しているので、分からないことがあればいつでも質問できます!**
本記事を読んで、 Kaggle や Kaggle 部について興味を持っていただいた方は、是非とも弊社の門を叩いていただければ幸いです。
採用サイトはこちら
弊社トップゲートでは、Google Cloud (GCP) 利用料3%OFFや支払代行手数料無料、請求書払い可能などGoogle Cloud (GCP)をお得に便利に利用できます。さらに専門的な知見を活かし、
- Google Cloud (GCP)支払い代行
- システム構築からアプリケーション開発
- Google Cloud (GCP)運用サポート
- Google Cloud (GCP)に関する技術サポート、コンサルティング
など幅広くあなたのビジネスを加速させるためにサポートをワンストップで対応することが可能です。
Google Workspace(旧G Suite)に関しても、実績に裏付けられた技術力やさまざまな導入支援実績があります。あなたの状況に最適な利用方法の提案から運用のサポートまでのあなたに寄り添ったサポートを実現します!
Google Cloud (GCP)、またはGoogle Workspace(旧G Suite)の導入をご検討をされている方はお気軽にお問い合わせください。
お問合せはこちら
メール登録者数3万件!TOPGATE MAGAZINE大好評配信中!
Google Cloud(GCP)、Google Workspace(旧G Suite) 、TOPGATEの最新情報が満載!
関連記事



Contactお問い合わせ

Google Cloud / Google Workspace導入に関するお問い合わせ