2023年7月新登場!Google Cloud SQLの最上位エディション「Enterprise Plus」を触ってみた
- Cloud SQL
- Enterprise Plus
- PostgreSQL

目次
前書き
こんにちは。開発部の高井(Peacock)です。
AlloyDB for PostgreSQLの連載を4月より掲載していますが、今回は2023/07/12にGAとなったGoogle Cloud SQLの新エディション「Enterprise Plus」についてプレビュー前検証する機会を頂けたので試していきます。
Cloud SQL Enterprise Plusエディションとは
公式の紹介ページを引用して拙訳すると、「Enterpriseエディション(以下、従来のCloud SQL)に加えて、最高レベルの可用性とパフォーマンスを提供します」とあります。
具体的にどの辺が、というのは以下の3点のようです。
- Data cache経由での読み取り性能
- 書き込みパフォーマンス
- オートスケーリング
GA時点(2023/07)でData cache SSDが有効になるのはMySQLのみで、今回検証するPostgreSQLについては対象外のようです。
インスタンス立ち上げ
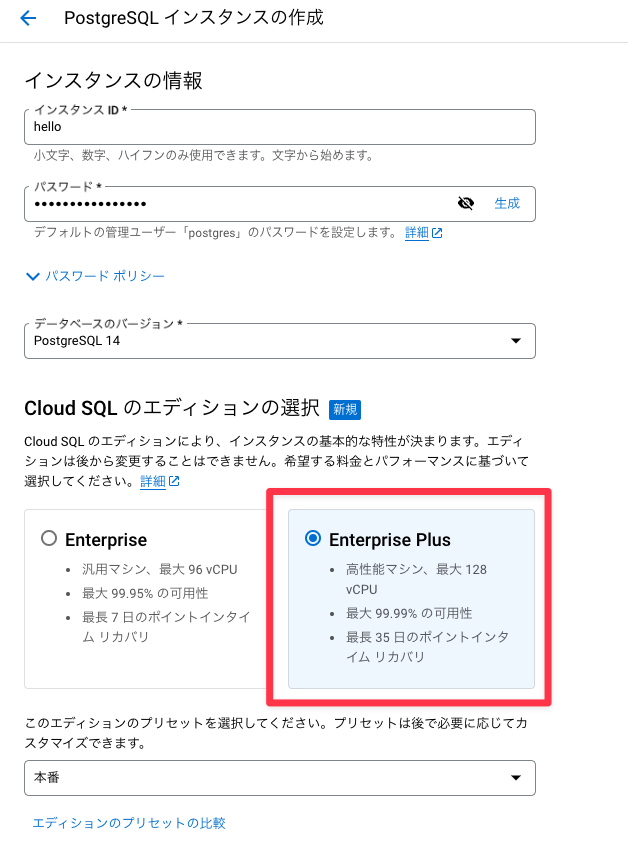
7月12日のGAでCloud Consoleからも作成できるようになったので、簡単に手順を示しておきます。
いつも通りMySQL/PostgreSQLを選ぶと「Cloud SQL のエディションの選択」という項目が出てきます。こちらでEnterprise Plusを選択すると作成できます。
マシンタイプはカスタマイズすると以下から選べます。メモリが従来のCloud SQLより多めに設定されているのがわかります。
- 2 vCPU、16 GB
- 4 vCPU、32 GB
- 8 vCPU、64 GB
- 16 vCPU、128 GB
- 32 vCPU、256 GB
- 48 vCPU、384 GB
- 64 vCPU、512 GB
- 80 vCPU、640 GB
- 96 vCPU、768 GB
- 128 vCPU、864 GB

パフォーマンス差について
対象のデータベース
各サービス3つともにPostgres 14.7系で作成しています
- 従来のCloud SQL(Enterpriseエディション): 8 vCPU, 30GB Memory (
db-n1-standard-32) - Cloud SQL Enterprise Plus: 8 vCPU, 64GB Memory (
db-perf-optimized-N-8) - AWS RDS(比較用): 8 vCPU, 32GiB Memory (
db.m5d.2xlarge)
結果(詳細な計測方法は記事末尾に)
実測値は掲載できないので、従来のCloud SQL(Enterpriseエディション)のSelectタスクのmedian(中央値)を1として相対値で掲載します。小数点第4位以下切り捨てです。
| 対象 | 従来のCloud SQL | Enterprise Plus | AWS RDS | |
| タスク | DBスペック | 8 vCPU/30GB RAM | 8 vCPU/64GB RAM | 8 vCPU/32GiB RAM |
| Insert | median | 1.900 | 0.946 | 1.241 |
| mean | 1.888 | 0.958 | 1.257 | |
| Select | median | 1.000 | 0.898 | 0.968 |
| mean | 1.011 | 0.905 | 1.188 | |
| Update | median | 0.502 | 0.272 | 0.331 |
| mean | 0.462 | 0.295 | 0.349 | |
| Delete | median | 0.118 | 0.092 | 0.092 |
| mean | 0.127 | 0.090 | 0.183 |
結果考察
概ね想定通りの結果になりました。従来のCloud SQLと比べ、メモリが2倍以上になったからかInsert, Updateでは倍近いパフォーマンスが出ていました。
まとめ
今回はCloud SQLの新エディションであるEnterprise Plusについて触って検証してみました。
時間の都合でPostgreSQLのみの検証でしたが、十分に実用的だったのではないかと思います。
補足: 検証内容について
補足として、今回触って検証した内容について前提を記載しておきます。
計測方法
AlloyDB連載でも取り扱っている英国不動産取引データCSVを使用しました。直近数年(2020 - )のデータに対し簡単なCRUDタスクをpsqlコマンド経由で実行したものをそれぞれ8回繰り返し計測しています。
実際の計測は以下のPythonスクリプトを使用しています。
#!/usr/bin/env python3.9
import pathlib
import statistics
import subprocess
import sys
import time
def main(ip: str, pw: str):
here = pathlib.Path(__file__).parent.resolve()
psql = ["psql"]
tasks = ["insert", "select", "update", "delete"]
results = {"insert": [], "select": [], "update": [], "delete": []}
env = {"PGHOST": ip, "PGUSER": "postgres", "PGPASSWORD": pw, "PGDATABASE": "pp_all"}
for i in range(1, 8):
script = (here / "create_table.sql").resolve().read_bytes()
print(f"{ip=} executing: {i}")
r = subprocess.run(psql, shell=True, env=env, input=script)
print(f"{r.returncode}, {r.stdout=}, {r.stderr=}")
for s in tasks:
script = (here / f"{s}.sql").resolve().read_bytes()
print(f"{ip=} Running task {s}")
start = time.time()
r = subprocess.run(
psql, shell=True, env=env, input=script, stdout=subprocess.DEVNULL
)
print(f"{r.returncode=}")
if r.returncode != 0:
print(f"{r.stdout=}, {r.stderr=}")
end = time.time()
duration = end - start
results[s].append(duration)
print(f"{ip=} Command {psql} {duration=} seconds")
else:
print(f"{ip=} Dropping table")
script = (here / "drop_table.sql").resolve().read_bytes()
r = subprocess.run(psql, shell=True, env=env, input=script)
print(f"{r.returncode}, {r.stdout=}, {r.stderr=}")
time.sleep(5)
else:
print(f"Executed to {ip=}")
for task, values in results.items():
median = statistics.median(values)
mean = statistics.mean(values)
print(f"{task=} {median=} {mean=}")
if __name__ == "__main__":
main(sys.argv[1], sys.argv[2])実際の計測タスク
各タスク(insert, select, update, delete)と準備・掃除用のSQLファイル・取り込む対象のCSVファイル(年別)も同ディレクトリに配置しています。
\copy land_registry_price_paid_uk FROM './pp-2022.csv' with (format csv, encoding 'win1252', header false, null '', quote '"', force_null (postcode, saon, paon, street, locality, city, district));
\copy land_registry_price_paid_uk FROM './pp-2021.csv' with (format csv, encoding 'win1252', header false, null '', quote '"', force_null (postcode, saon, paon, street, locality, city, district));
\copy land_registry_price_paid_uk FROM './pp-2020.csv' with (format csv, encoding 'win1252', header false, null '', quote '"', force_null (postcode, saon, paon, street, locality, city, district));SELECT
*
FROM
land_registry_price_paid_uk
WHERE
transfer_date::date >= '2022-01-01';UPDATE
land_registry_price_paid_uk
SET
price = 100000
WHERE
transfer_date::date >= '2021-01-01'
AND transfer_date::date <= '2021-12-31';DELETE FROM
land_registry_price_paid_uk
WHERE
transfer_date::date >= '2020-01-01'
AND transfer_date::date <= '2020-12-31';CREATE TABLE land_registry_price_paid_uk (
TRANSACTION uuid,
price numeric,
transfer_date date,
postcode text,
property_type char(1),
newly_built boolean,
duration char(1),
paon text,
saon text,
street text,
locality text,
city text,
district text,
county text,
ppd_category_type char(1),
record_status char(1)
);DROP TABLE land_registry_price_paid_uk;関連記事



Contactお問い合わせ

Google Cloud / Google Workspace導入に関するお問い合わせ